



「HPE Machine Learning Development Environment」「HPE Swarm Learning」の2ソリューション
HPE、大規模機械学習とエッジ分散型機械学習のソリューションを発表
2022年05月26日 07時00分更新

日本ヒューレット・パッカード(HPE)は2022年5月25日、AI開発を加速するソリューションとして、大規模な機械学習モデルの開発とトレーニングのためのターンキーソリューションである「HPE Machine Learning Development System」と、エッジや分散拠点における“共同機械学習”を促進する「HPE Swarm Learning」を発表した。
日本ヒューレット・パッカード HPC&AI・MCS事業統括 執行役員の根岸史季氏は、機械学習モデルを進化させるためには大規模なトレーニングを実行できるインフラが必要になること、またさまざまなデータが生成されるエッジにおいても機械学習処理(エッジ学習)が必要とされることを説明し、今回の発表で「分散学習分野やシミュレーションにおいて、自信を持って提供できるソリューションが揃うことになる」と語った。
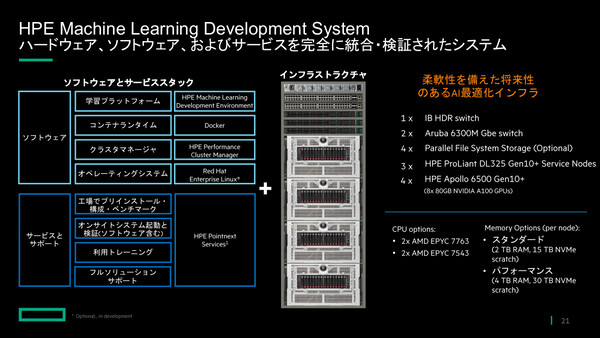
「HPE Machine Learning Development System」の概要


日本ヒューレット・パッカード HPC&AI・MCS事業統括 執行役員の根岸史季氏、AIビジネスデベロップメントマネージャーの山口涼美氏
「AIをPoCから実運用へと加速させる」ターンキーソリューション
HPE Machine Learning Development Systemは、機械学習ソフトウェア基盤やコンピュート、アクセラレータ、ネットワーキングを統合したエンド・トゥ・エンドソリューション。大規模なトレーニング処理を容易に実現できる環境を提供することで、より高精度なAIモデルを、迅速に開発できる。
HPEでは2021年6月、オープンソースのAIトレーニング基盤を手掛けるDetermined AIを買収した。今回リリースしたHPE Machine Learning Development Systemには、同社の技術を基にした「HPE Machine Learning Development Environment」と呼ぶAIトレーニング基盤を統合しており、これまで数週間~数カ月かかっていた機械学習モデルの構築期間を、数日に短縮できるという。
同ソリューションは、32GPUの小規模構成から256GPUの大規模構成まで、さまざまなワークロードに対応。最適化されたコンピュート、アクセラレータ、インターコネクトを提供し、効率的に拡張することもできる。最上位構成では、AI/HPCプラットフォームである「HPE Apollo 6500 Gen10 Plus」による構成も用意している。
HPE Machine Learning Development Environmentのほかにも、「Docker」や「HPE Performance Cluster Manager」「Red Hat Enterprise Linux」などのソフトウェア環境を搭載。これらは工場でプリインストール、構成、ベンチマークを実施したのちに出荷され、オンサイトでシステム起動と検証を行って納品される。さらに、HPEによる利用トレーニングや、フルソリューションサポートも提供する。

シームレスに統合されたプラットフォームを提供し、さまざまなモデル開発/トレーニングを効率化する
同社 AIビジネスデベロップメントマネージャーの山口涼美氏は、「HPE Machine Learning Development Systemは、AIをPoCの段階から実運用へ加速させる大規模な開発およびトレーニングのためのターンキーソリューション」だと説明する。モデルの精度を高めるための労力を削減し、モデルの再利用やパラメータ設定の簡便化、コード書き換えの最小化、モデルの共有/再利用の促進などが図られるという。さらに「効率的なGPUリソースの利用、肥大化するコストと時間、環境やツールの多様性や変化といった、機械学習モデルエンジニアが持つ課題を解決できる」と述べた。
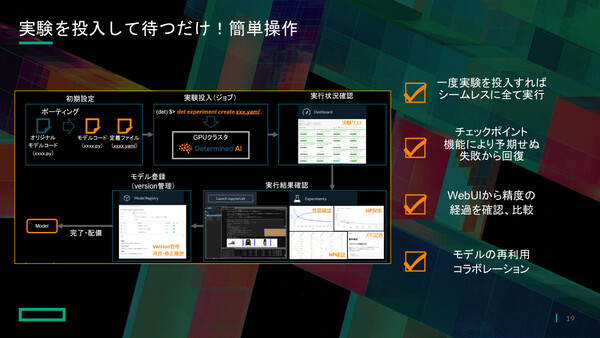
同ソリューションは一度実験を投入すればすべてを自動実行する。「全自動洗濯乾燥機のように、一度ボタンを押せば洗濯から乾燥まで終了するのと同じ」(山口氏)
HPE Machine Learning Development Systemを採用したAIスタートアップの独Aleph Alphaでは、5カ国語のテキスト/画像処理のほか、人間とほぼ同等の文脈理解を組み合わせ、AIアシスタントによる複雑な文章の作成、高度な要約、何百もの文書からの情報検索、会話文脈での専門知識の活用などを可能にした。このAIモデルのトレーニングスループットを50%向上させることができたという。
エッジノード間の分散/共同機械学習「HPE Swarm Learning」
もうひとつの新発表であるHPE Swarm Learningは、エッジにおける分散型の機械学習処理によって、データの保護と共有を両立しながら精度の高いモデル学習を実現するAIソリューションと位置づけられている。
具体的には、API経由で実データそのものではなく学習結果(AIモデル)をノード間で随時共有し、トレーニング効果を高める。これにより、データプライバシーを維持しながら、AIモデルの学習結果を共有、統合することが可能で、医療分野での活用やクレジットカード詐欺の検出など、エッジでのインサイトを加速することができる。
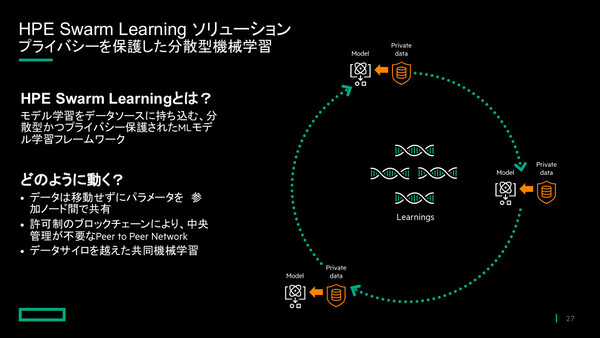
「HPE Swarm Learning」の概要
このHPE Swarm Learning は、Hewlett Packard Labsが開発した技術だ。2021年5月にはNature誌に掲載され、ベータ版を提供してきた。
「一般的な中央集権型の学習では、あらゆる場所で発生したデータをデータセンターやクラウドに集約するため、通信帯域の圧迫や生データの転送という無駄、モデル更新のタイムラグといった課題があった。また、データプライバシーの確保や、企業間/拠点間のコラボレーション型開発ができないという課題もある」(山口氏)
一方でHPE Swarm Learningでは、データを移動せずにパラメータを参加ノード間で共有するかたちをとるため、「データサイロを越えた共同機械学習が可能になる」(山口氏)。各ノードは機械学習処理を行ったパラメータを他ノードと共有し、「融合」したパラメータを受け取る。目的の精度が得られるまで学習と融合を繰り返すことで、最終的には全ノード共通の高精度なAIモデルが出来上がる仕組みだ。パラメータは、プライベート型ブロックチェーンネットワークを用いて共有される。
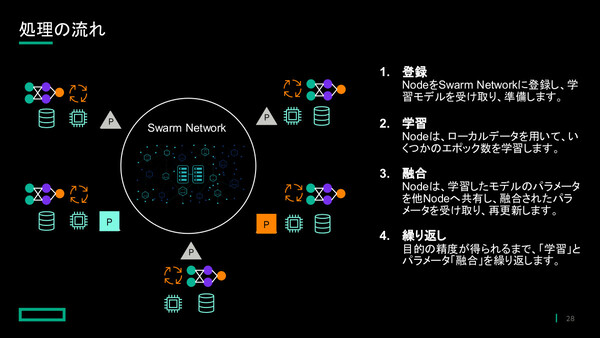
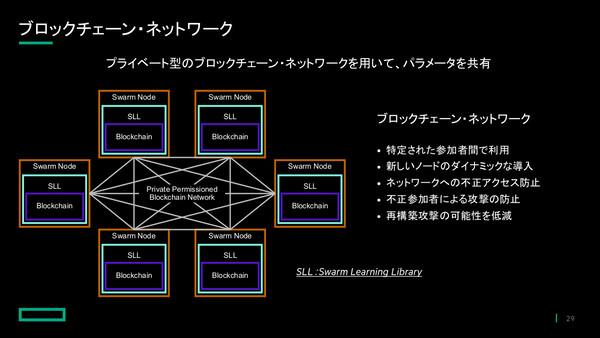
HPE Swarm Learningにおける「共同機械学習」処理の概要
山口氏は「異なる拠点でのデータ活用や、企業や組織間の共同学習、分散管理での平等な関係の構築、参加メンバーの道的な広がりにも対応でき、非中央集権型の学習が可能になる」と、その特徴を強調した。中央へのデータ移動や複製のコストも削減される「サステナブルナAI学習環境を実現できる」としている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



