




MACユニットを高速に回すことに特化
さてそのEthos-Nシリーズの基本構成であるが、内部そのものは非常に単純である。Inference(推論)向けであり、かつ幅広い用途に使われることを考慮してか非常に簡単である。端的に言えばMACユニットをどれだけ高速に回すかしか考えていない。
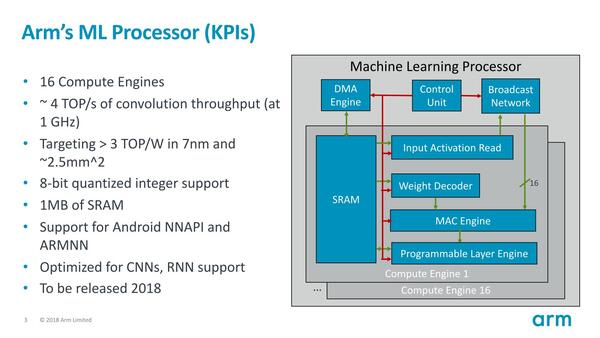
Ethos-Nシリーズの基本構成。これはEthos-N77のもので、Ethos-N37/57/78ではコアの数がSRAMのサイズが異なる
扱うのもINT 8のみという割り切った構成である。ただし7nmプロセスで2.5mm2程度のダイサイズで、かつ3TOPS/Wをターゲットにするという、シンプルにしてぶん回すだけではやや難しい性能ターゲットとなっている。これを実現するためにEthos-Nシリーズは以下の4つの原則を掲げている。
- 固定スケジューリング
- 畳み込みの効率化
- 帯域削減
- プログラマビリティー/スケーラビリティー
まず固定スケジューリングだが、エリアサイズ削減(余分な回路を入れて回路規模を大きくしない)と消費電力削減のために、動的なスケジューリングはComputation Engine側で一切実行しない。
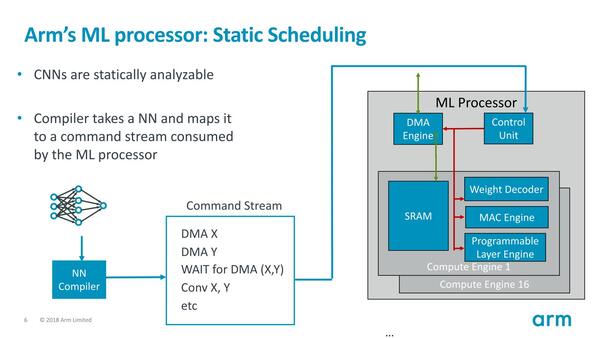
Computation Engine側で動的なスケジューリングは行なわない仕組み。要するにあらかじめソフト側で完璧にコマンドを組み立てておかないと効率が悪いという話でもある
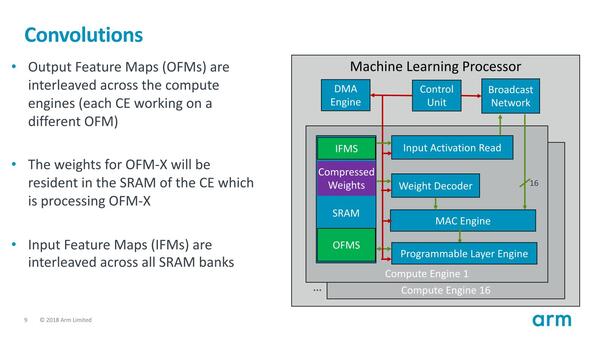
その一方で、疎行列で計算を省くといった工夫はない。このあたりは、そうしたメカニズムを入れることでむしろ機構が複雑化することを避けたのだと思われる。さらに固定スケジューリングでは、高速化してもあまり意味がないという話もある
次の「畳み込みの効率化」であるが、畳み込みはデータに重み(Weights)をかけて、その結果を合算する形になる。やっていることは単純だが、なにしろ扱うべきデータ量が多いし重みの数も非常に多く、結果外付けのDRAMに格納しておくことになる。
これは部品点数の点でも消費電力の点でも不利なため、内蔵のSRAMに、特に重みは圧縮して格納することで、畳み込みの計算の際に外部DRAMアクセスの必要を排除し、効果的に演算ができるようにしたというものだ。
ちなみに入力画像(IFMS:Input Feature Maps)が大きい場合、当然入力領域を分割して複数のCompute Engineで処理することになるが、畳み込みの計算の処理そのものは複数のCompute Engineはまたがない(それをやるとむしろオーバーヘッドが大きくなると判断したのだろう)。
ただ畳み込みの計算を終わらせて出力(OFMS:Output Feature Maps)を作成する際には、再び複数のCompute Engineの結果をまとめて処理する形になる。
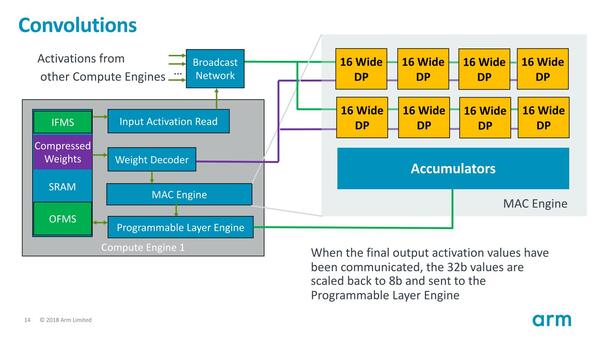
ちなみにこの中で一番ブン回るのがMACユニットになるので、ここは16nmおよび7nmプロセスに最適化してある、と説明されている
帯域削減は上でも触れたが、外付けのDRAMを接続するとそれだけで消費電力が倍近くなる。
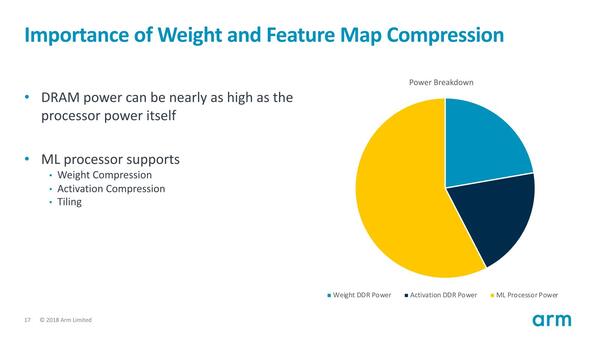
これはArmの試算であるが、外付けのDRAMを使うようにすると4割以上消費電力が増えるとしている
そこで内蔵SRAMを搭載することでDRAMの必要性を排除するわけだが、ただSRAMでも容量が大きくなれば消費電力はそれなりにかかるし、回路規模が大きくなるからエリアサイズ増大に直結してコストが上がることになる。
これを避けるためには、無駄な容量を使わないように工夫する必要がある。そこでSRAMへのWeightやFeature Mapの格納はすべて圧縮するようにした。もちろんこうなるとCompute Engineの側に圧縮/伸張エンジンが必要になるのだが、これによる消費電力増や回路規模増大を加味しても、SRAMの必要容量を減らせることのメリットの方が大きいと判断されたわけだ。
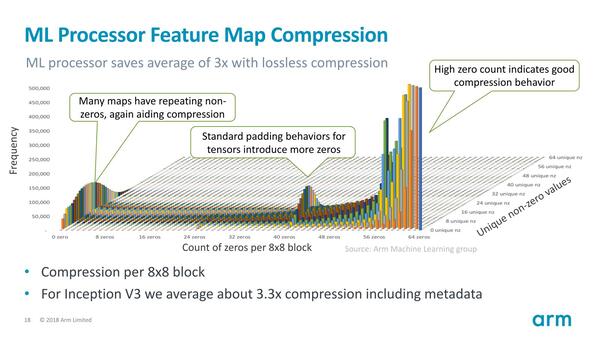
Feature Mapの場合、特に疎のデータが多いケースでは圧縮が効きやすいこともあって、平均で3.3倍の圧縮率が実現できたとする
また、これはハードウェアというよりはソフトウェア側の話になるが、プルーニング(ネットワークそのものの圧縮)をすることでメモリーを削減している。
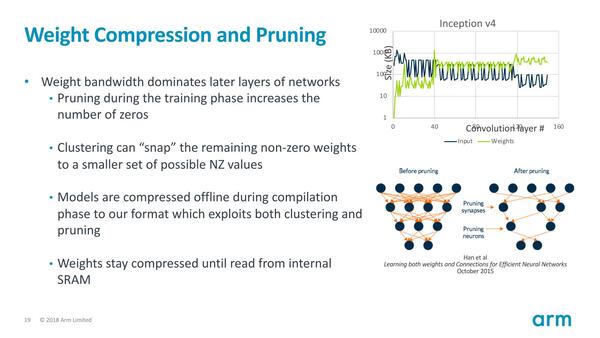
Weightも当然圧縮をかける。プルーニングは右下の図でわかるように、精度を落とさずにネットワークそのものを簡単化する技法であるが、Ethosの場合はこれはソフトウェア側で対応するものになっている
加えて言えば、SRAMベースであるからアクセス時間が正確に見積りできる。これを利用して、コンパイラの段階で各々の処理で必要となる帯域をきちんと見積って最適化を図ることで、帯域を削減できる余地があるとする。
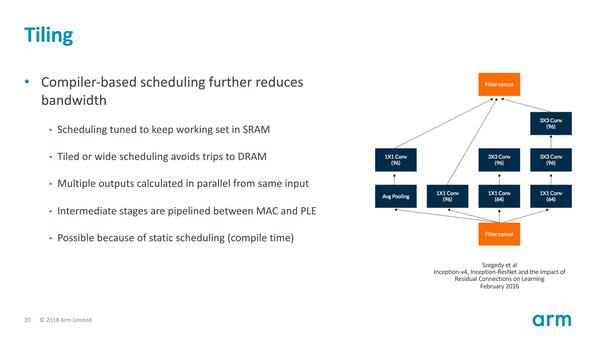
最適化することで帯域を削減できる余地があるという。もっともこれもソフトウェア側がどこまで最適化を図れるか次第ではある
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































