




他社を凌駕する性能と消費電力
スループットのみならずレイテンシーも低い
では性能はどうか? というのが下の画像だ。Nvidia V100とNVidia T4、それとHabana Labs/IntelのGoyaを対象として、性能と性能/消費電力比のどちらも圧倒的に高いとしている。
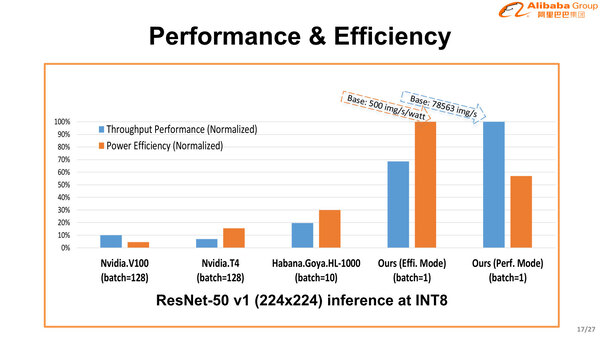
Hanguang 800の性能。性能/消費電力比最大(Effi.Mode)と絶対性能最大(Pere.Mode)の2つの動作モードがあることがわかる
動作モードは5つほど用意されており、25Wから276Wまでの範囲で、性能比も6.2倍に達する。この25Wや50Wというモードは、単にAlibaba Cloudだけではなくエッジ向けに組み込む場合も想定してのものだろう。
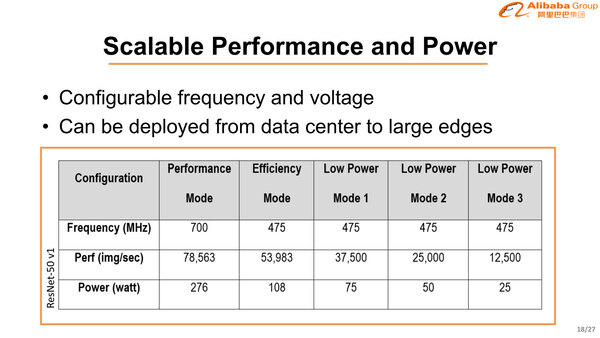
Efficnency Modeは4つのコアを全部有効にするが、Low Power Mode 1~3はおそらく有効コア数も減らしていき、Low Power Mode 3では1コアのみが稼働する状況と思われる
スループットのみならずレイテンシーも低い、というのがHanguang 800の特徴でもある。Batch Sizeに関係なく画像処理のスループットは一定であり、しかもレイテンシーは0.11ミリ秒と圧倒的に低いとされる。
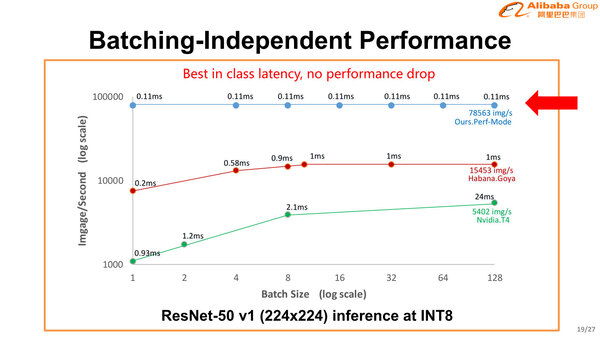
Batch Size=1の場合はまだそれほどレイテンシーの差がないが、ただNvidia T4やHanabaのGoyaでは十分な性能が出ない。フル性能を出そうとするとBatch Sizeを128程度にする必要があり、これだとHanabaのGoyaで1ミリ秒、NvidiaのT4では24ミリ秒までレイテンシーが悪化するというのが彼らの主張だ
ResNet以外でもこうした特徴は変わらないという結果も示されている。
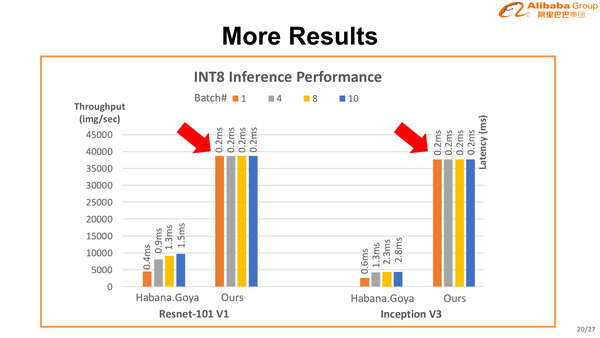
ResNet-101やInception V3でもレイテンシーはBatch Sizeにかかわらず0.2msで、それでいて処理性能は圧倒的に大きいとされる
NVIDIAのV100やA100との比較が下の画像で、スループットと性能/消費電力比もNVIDIAのGPUを圧倒しているとする。
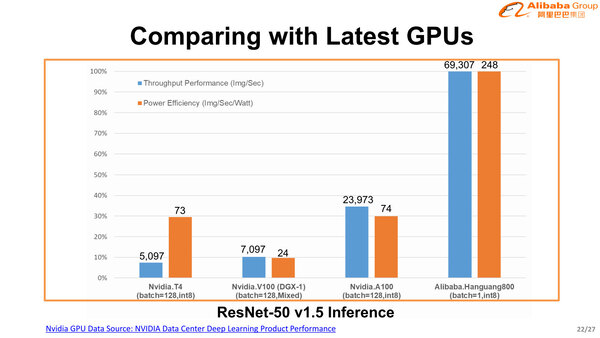
NVIDIAのV100やA100との比較。もっともこれはINT 8を前提にした処理だから降りという部分もあるのだろう
このHanguang 800、昨年9月の発表時の説明では、すでにAIを利用するさまざまな事業で利用されているという話だった。具体的には製品の検索やレコメンデーション、eコマースにおける自動翻訳、広告、カスタマーサービスなどである。
実はこうした自社ビジネス向けを従来のCPUやGPUから置き換えるだけでコスト(主に電気代)を大幅に削減できるというあたりである程度開発コストは償却が済んでいるだろう。
現状のAlibaba Cloud上でユーザーが直接Hanguang 800を利用できるインスタンスそのものは存在しないが、例えば分析のData IntegrationやImage Searchなどで、内部的にHanguang 800が動いているだろうというのは容易に想像がつく。
なんというか、使い方がすごく限られ、これまで説明してきた推論向けプロセッサーに比べて柔軟性がだいぶ劣る気がするとはいえ、そのあたりをわかったユーザー(つまりAlibaba Cloud自身)が使う分には問題ないということだろう。こうしたプロセッサーは、今後も増えていくと思われる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ











ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")











ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












