



「とにかくデータをたくさん学習させればいい」は誤り、「db tech showcase」講演レポート
機械学習プロジェクト、成功のカギは「ドメイン知識」
2020年11月24日 08時00分更新

インサイトテクノロジーが主催するデータベース技術者のためのテクノロジーカンファレンス「db tech showcase 2020 ONLINE」が、2020年10月27日~12月10日までの7週間にわたって開催中だ。本稿では、11月17日に行われたセッション「AI/ML導入そして運用の成否を分けるポイントは」の内容をレポートする。
40分間の同セッションの講師を担当したのは、インサイトテクノロジー プロダクト開発本部の小浦方寛太氏だ。小浦方氏は統計・機械学習(ML、マシンラーニング)を用いたシステム開発を担当しており、特に教師なし異常検知システムの提案や構築を受け持つことが多いという。“推し”の実問題解決アプローチは「ベイズ学習」と「モデリング」とのこと。セッションでは、機械学習プロジェクトを成功させるためのポイントについて、小浦方氏が実際に担当した顧客先での事例を交えて説明した。

インサイトテクノロジー プロダクト開発本部の小浦方寛太氏(db tech showcase 2020 ONLINE Webサイトより)
機械学習に「客観性」を期待してはダメな理由
まず、機械学習で何ができるのか。「ベイズ理論による機械学習入門」(須藤敦志著/講談社/2017)によれば、「機械学習とは、データから規則や構造を抽出することにより、未知の現象に対する予測やそれに基づく判断を行うための計算技術の総称」である。小浦方氏はより具体的に、機械学習が得意とすることを次のように説明する。
「人間では処理しきれない大量のデータ、人間の手に余るほどデータ間の関係が複雑なデータ、高速に判断して処理する必要があるデータ、安定して処理する必要があるデータなど、人間では容易にできないデータ処理で、機械学習は力を発揮する」(小浦方氏)
誤解されがちなのは、機械学習とは、機械(コンピューター)が「客観性」をもった判断や、唯一の「真実」を導き出すわけではないという点だ。機械学習と言えど、人間の主観やバイアスを完全に排除することはできない。未知の状況に対して予測をする際は何かしらの仮定を人間が導入しない限り解は定まらないし(不良設定問題)、客観的なデータ分類はありえない(醜いアヒルの子定理)と言われている。
人間の心理としてAIや機械学習に客観性を期待してしまいがちだが、機械学習を使ってデータから価値を得るプロセスは、主観の排除とは正反対のアプローチになる。重要なのは、機械学習を使って解きたい問題や学習させるデータに関する知識(これを「ドメイン知識」と呼ぶ)をもった人間が、機械学習の種類(アルゴリズム)を選択したり、機械学習の結果を適切に解釈したりすることだ。
「機械学習を含めたプロダクトをビジネスとして成功させるためには、プロダクトに関するドメイン知識を持った人を巻き込めるかどうかがカギになります」(小浦方氏)
顧客からドメイン知識を得られない場合にはどうするか
実際に、小浦方氏が機械学習エンジニアとして関わったある顧客プロジェクトでは、顧客から十分なドメイン知識を得られたことが成功につながったという。
このプロジェクトでは、日本各地に設置された膨大な数のWi-Fiルーターについて、pingの応答はあっても実際には通信障害が発生している「サイレント故障」を、機械学習の適用で自動検知するシステムの構築が目的となった。ここでは、これまで現場で故障検知を手がけてきたエンジニアと協議を繰り返し、そこから得られたドメイン知識を異常検知モデルに反映。その結果、サイレント故障を検知することに成功し、障害件数を10分の1に削減できたという。

ネットワーク機器のサイレント故障検知の事例
しかしながら、顧客側の事情によっては、データやドメイン知識を外部の分析者に提供できないこともある。
小浦方氏が関わった別の顧客プロジェクトは、数十~数百のセンサーデータからセンサー間の関連を考慮して異常検知を行うものだったが、顧客からドメイン知識を得ることが困難だった。データは大量にあるがドメイン知識がない、こうしたプロジェクトは失敗率が上がってしまうが、小浦方氏のチームは、教師なしモデルでいったん検出した“異常候補”をユーザーに提示、それをアノテーション(評価)してもらうことで情報の不足を補い、異常検知モデルを構築することができたという。
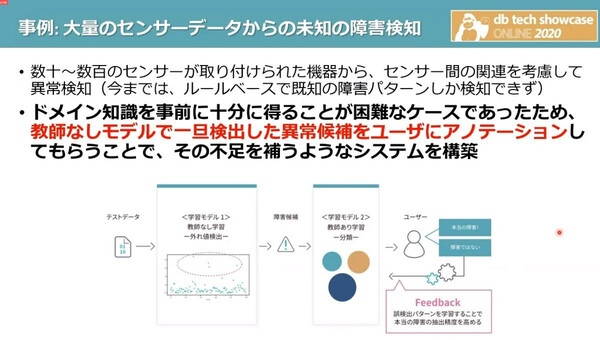
センサーデータからの未知の障害検知
教師なし学習でもドメイン知識が大事
異常検知のプロジェクトが難しいのは、学習させるための「異常時のデータ」が入手しづらい点だ。異常時のデータがわずかでもあればよい方で、異常の教師データはない場合が多いと小浦方氏は言う。教師なし手法を用いれば何らかの異常検知アルゴリズムは作れるが、それが実際に「使える」ものなのかどうかの評価が難しい。そこで、正常時のデータを加工して人工的に異常データを作り、それを検知できるかどうかを評価させることになるが、この異常データを作るためにはやはりドメイン知識が欠かせない。
小浦方氏は最後に「“とにかくデータをたくさん学習させればよい”という考え方は基本的に誤り。それよりも、ドメイン知識のほうがはるかに重要です」と述べ、セッションを締めくくった。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



