




Cascade Lakeの106倍の性能という
QualcommのCloud AI 100
SiMa.aiとは逆に、突如としてAIアクセラレーターチップそのものを発表したのがQualcommである。
SiMa.aiやGroqのようなスタートアップ企業の場合、まずファンドなどから資金を集める必要があり、そのためにはアーキテクチャーや市場、将来性などを早いタイミングでアピールする必要があるため、チップ完成の前に発表するわけだが、Qualcommのような大企業の場合は自前で開発資金を十分賄えるので別にチップの完成まで発表の必要はないわけだ。
さてそのQualcommが9月16日に発表したのがCloud AI 100である。開発の動機は単純で、より高性能のAIプロセッサーが必要だからである。
Qualcommの場合、Snapdragonシリーズに搭載されているHexagon DSPを利用してAIの処理が可能で、15TOPS程度までの処理性能はすでに確保している。

Snapdragonに搭載されるHexagon DSPは、最近ではTensorアクセラレーターなども搭載しており、十分に強力なAIアクセラレーターとして利用されている
QualcommはMobile Edgeの10社のうちの1社であり、このあたりは抜け目がない。ただ、いわゆるEmbedded Edgeではもっと高い処理性能が必要であり、Cloud向けはさらに高性能なものが要求される。ここに向けたアクセラレーターがCloud AI 100となる。

Cloud AI 100は、Dual M.2(M.2コネクターが2つ並んだフォームファクター)ないしPCIe x8のカードという形(Dual M.2は消費電力に併せて2種類)が提供される
もっともQualcommは、その詳細を発表するつもりはまるでないようで、内部構造として示されたのは下の画像だけである。

Cloud AI 100の概要。HBMやGDDR/DDRではなく、LPDDRを利用するというあたりがQualcommならではだろう。もっとも昨今LPDDR4は4.3Gbpsに達しており、GDDR/HBMほどではないがDDR4よりは帯域が広いので、これはこれで合理的かもしれない。オンダイSRAMも最大144MBと強烈。コアあたり9MBということだろう
核となるのはAIC(AI Core)であるが、これが最大で16コアで400TOPSとあるので、1コアあたり25TOPSほどの計算になる。
ラインナップは15W、25W、75Wの3つで、15Wのものは4コア、25Wのものは6コアで、どちらも動作周波数を若干落とした構成。フルスピードのものが16コア構成で75W動作ということなのだろう。
さてこのCloud AI 100、性能として示されたのが下の画像だ。20WというのはDual M.2カードの構成に近いだろうが、Cascade Lakeを1とした時に106倍の性能とされる。
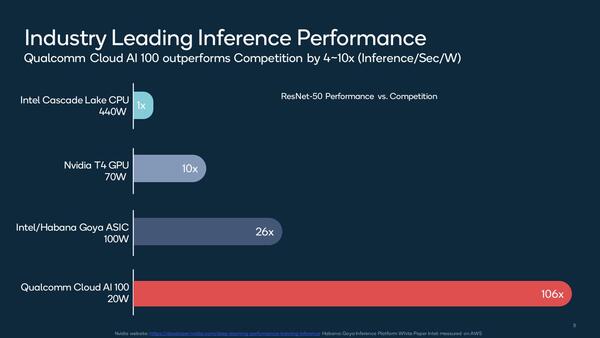
競合と比較して4~10倍の効率、というのはすでにCascade Lakeは競合相手されていないということでもある
もっと強烈なのが下の画像で、GroqのTSPすら比較にならないほど高速、というのがQualcommの主張である。
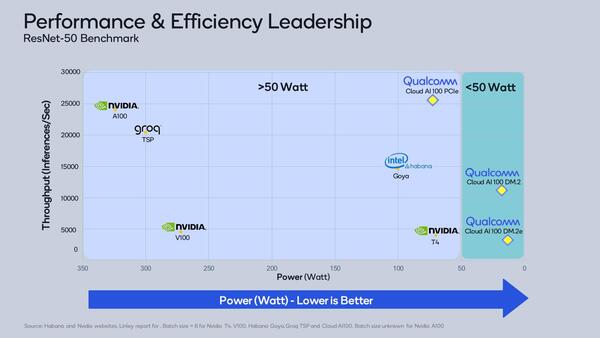
少しわかりにくいが、横軸は消費電力を逆順にして示しており、遠いほど省電力で動作することになる
さてQualcommのおもしろいのはここからだ。PCIeカードもしくはDual M.2カードというからには、サーバーなどに装着する形での運用を考えそうなものだが、なぜかその開発キットはEmbedded Edge向けの構成なことである。

Cloud AI 100は、屋外での利用を考慮した筐体に収められる形で出荷されるという
Cloud AI 100はあくまでもアクセラレーターなので、Snapdragon 865およびSnapdragon X55と組み合わせることで、アプリケーションプロセッサー兼ISPと5Gの接続性を確保できるとする。

MLSoCの構成を3チップで実現した格好になっている
Qualcommによる、この開発キットの紹介ビデオ(https://www.youtube.com/watch?v=AFb1KoGUOlE)によれば、24台のフルHDカメラを接続し、この動画を25fpsでキャプチャーしながらそこにAI処理を施せるとしている。

24台のフルHDカメラで25fpsの動画をキャプチャーしながらAI処理を施せるという。しかもそれぞれのカメラに対して異なるネットワークを適用可能だとしている。もちろんこれはシンプルな車両認識アルゴリズムなので、もっと複雑なアルゴリズムを実行させるともう少し効率は落ちるかもしれない
これは従来のEmbedded Edge向けAIアクセラレーターでは手が出ない要求性能であり、これを見事に処理できるというわけだ。
この開発キットは今年10月から出荷予定で、Cloud AI 100チップそのものの量産開始は2021年前半とされる。Qualcommのことだからきっと量産を開始しても内部の詳細は公開しない気がするが、このAI推論市場もなかなか厳しい戦いになっていることがおわかりいただけたはずだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























