
新たにAGU2制御を追加した
Load/Storeユニット周り
ALUに関しては今回特に言及がなかった。ということで、次はLoad/Storeユニットになる。以前の構造と比較するとわかるが、以下のような違いがある。
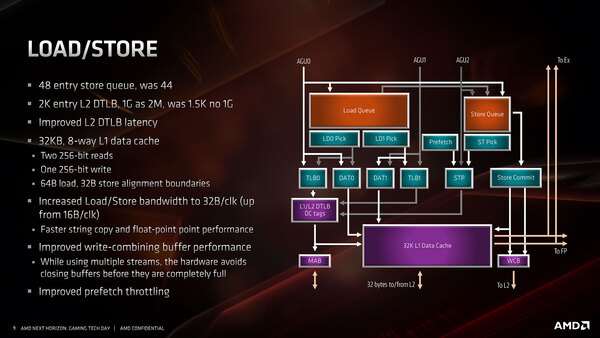
Load/Storeユニットの構造。よく見ると、以前の画像もこの画像もいくつか矢印が抜けてる、あるいは線が抜けてる部分があるので、脳内補完してみてほしい。AGUを追加した理由は、AVX256命令をサポートするためには256bit×2のLoadと256bitのStoreを1サイクルで実行できないといけないためである。でないと、AVX256命令の処理がLoad/Storeでストールすることになる。
- 新たにAGU2からの制御が追加された
- Store Pipe Pick周りの構造が少し変わった(Store Pipe Pickはプリフェッチからのデータは参照しない。プリフェッチは直接STP:Store Pipeにリクエストを出す)
ちなみに3つのAGUであるが、以前は2つのAGUについて、Storeに関してはAGU0ないしAGU1からStore Queueにリクエストを出すだけだった。
| AGU0 | 基本はLoadでTLB 0/Data 0に直接アクセス可能。ただStore Queueにリクエストを出すこともできる。 |
|---|---|
| AGU1 | やはり基本はLoadで、TLB1/Data 1に直接アクセス可能。ただStore Queueにリクエストを出すこともできる。 |
これがZen 2ではAGU2が新たに追加された。
| AGU2 | 基本はStoreで、Store Pipeに直接アクセス可能。ただLoad Queueにリクエストを出すこともできる。 |
|---|
これを利用して、AGU0/1がLoad、AGU2がStoreをそれぞれ発行することで、256bit Load×2と256bit Store×1が同時に発行できるようになった形だ。
ただLoad/Store Queue経由では、かならずしもAGU0/1がLoad、AGU2がStoreである必要はなく、その意味ではインテルのAGUに比べると柔軟性は高いと言える。
広帯域になったキャッシュ周り
さて、次がキャッシュ周りだ。Zen 2では1次/2次/3次キャッシュがすべて32Bytes/サイクルで接続されるという、けっこう広帯域な構成になっている。
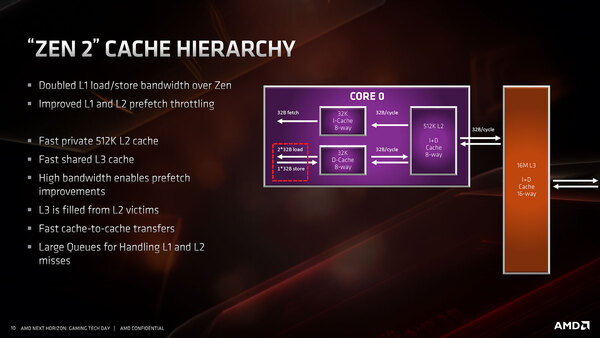
キャッシュ周りの構造。3次キャッシュはCCXの4つのコアで共有、という構造は同じ
ちなみに1次/2次キャッシュはSharedだが、2次/3次キャッシュはVictimの構成になっているのは従来と同じ。余談ながら、このVictimキャッシュが理由で、3次キャシュへのプリフェッチの機能は実装されていないそうである。
キャッシュ周りでは、3種類の制御命令が新たに追加されている。これは性能改善というよりは、例にもあるようにNVDIMMやアクセラレーター、あるいは将来のOSの利用に向けたもので、どちらかといえばRyzen系列というよりはEPYC系列向けの機能と言えよう。

3種類の制御命令が追加。ついにキャッシュ制御にまでQoS(Quality of Services)の概念が入ったか、という感じである
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ













