
いまいちはっきりしない
Core Complexの構造
昨年開催されたAMDの発表会Next Horizonでも、今年のCESの基調講演でもはっきりしなかったのはCCXの構造である。
下の画像はZenベースのダイの内部ブロック図であるが、2つのCCXは直接つながっておらず、インフィニティ・ファブリック経由での接続となる。
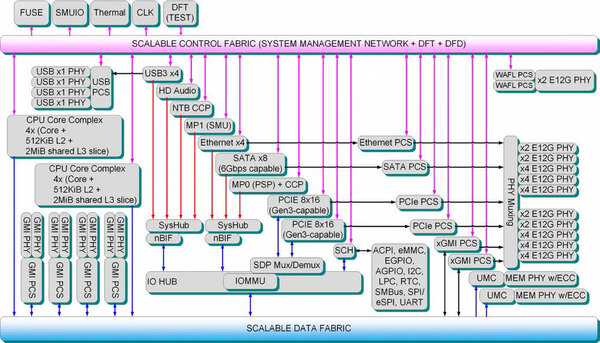
Zenベースのダイの内部ブロック図。左中央に2つのCPU Core Complexがあり、それぞれはScalable Control Fabric/Scalable Data Fabricにのみつながっているのがわかる
画像の出典は、“Processor Programming Reference (PPR) for AMD Family 17h Model 01h, Revision B1 Processors”
これを簡単に書けば、下図のような構成になる。
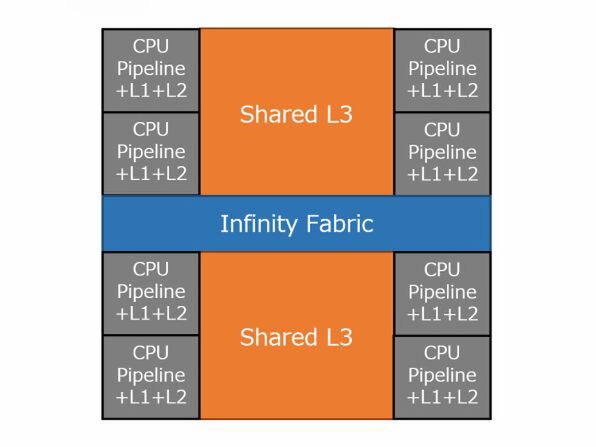
Zenベースのダイの内部ブロック
Ryzen、あるいはRyzen 2の場合、このインフィニティ・ファブリックはCPUダイの中だけで閉じているのでこれでも問題はなかったのだが、Zen 2ベースの場合はメモリーなどに対してもインフィニティ・ファブリック経由で接続することになる。
ということは、この構造を継承したとすると、下図のような構図になってしまう。これは果たして合理的かどうか? という話だ。
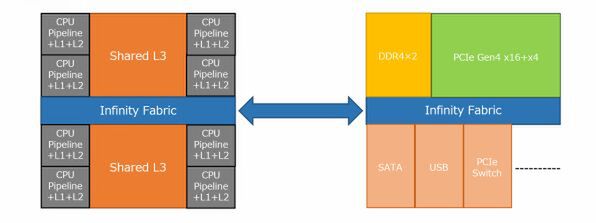
Zenの構造を継承した場合の、Zen 2の内部ブロック
CPUダイの側とI/Oダイの側の2つのインフィニティ・ファブリックのスイッチが連携して動くとすれば、インフィニティ・ファブリックをまたいでのCPUコア間の通信がさらに遅くなることになる。
逆に連動していないとすれば、CPUコアからメモリーアクセスを行なう場合、CPUコア→CPUダイ側のインフィニティ・ファブリック スイッチ→I/Oダイ側のインフィニティ・ファブリック スイッチ→メモリーコントローラー、と2つのスイッチを挟むことになり、そうでなくても大きくなりそうなレイテンシーがさらに増えることになり、あまり賢明とは思えない。
それもあって筆者は、Zen 2世代では下図のようにCCXが拡張されたのではないかと考えている。
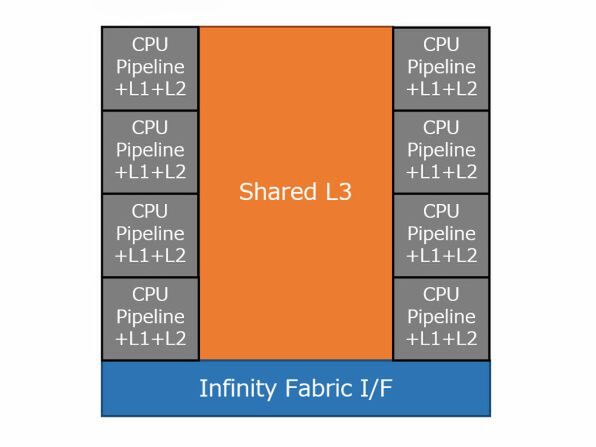
筆者が想像するZen 2の内部ブロック
つまりCPUコア同士はインフィニティ・ファブリックを介さず3次キャッシュ経由で直接接続されており、この3次キャッシュにインフィニティ・ファブリックのI/Fだけが用意されている。そしてインフィニティ・ファブリックのスイッチそのものはI/Oダイの側に集約されているという案だ。
そもそもなぜCCXが4コアベースなのかといえば、Raven Ridgeが4コアだからというのが答えになる。4コア製品が最小単位だからCCXは4コアベースとし、8コア製品はCCXを2つ搭載したわけで、もし最小構成が8コアならばCCXを8コアに拡張してもかまわないということだ。
もっともこの案にもいくつか欠点がある。最大のものは、これだと仮にRaven Ridgeの後継、つまり7nmで製造されるGPU統合RyzenがCPUとGPUをモノリシック(一体的)なダイで統合する場合にやりにくいことになる。また7nm世代でも、モバイルや組み込み向けに最小構成が4コアだとすれば、やはり8コアでCCXを作るのは無駄が多すぎる。
それとSenseMIはインフィニティ・ファブリック(正確にはScalable Control Fabric)をベースに構築されており、これのネットワークをI/Oダイ側に持っていって大丈夫なのか? というのが現時点では判断ができない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ












