



“NoSQLデータベース”という説明だけではわかりづらいデータ統合プラットフォーム
「サイロ化したデータの統合に最適なDB」マークロジックCEOに聞く
2019年01月07日 07時00分更新

「マークロジックは、企業内の分断された“データサイロ”を統合するのに最も適したデータベースだと自負している」。米マークロジック(MarkLogic)CEO兼社長のゲイリー・ブルーム氏はそう語る。
MarkLogicは「マルチモデルデータベース」を標榜する、データベース(DB)をコアに据えたデータ統合プラットフォーム製品だ。多様なデータソース/データモデルを“そのまま(AS IS)”取り込めること、ACID特性やセキュリティなどエンタープライズ/ミッションクリティカル用途向けの機能と能力を備えることなどの特徴を持つ。特に大規模組織/企業では現在、アプリケーションごとにDBを構築した結果、上述したDBの「サイロ化(分断)」という問題が多く生じており、その有効なソリューションとしてアピールしている。
今回はCEOのブルーム氏と日本法人代表の三浦デニース氏に、MarkLogicの特徴や顧客ニーズの強い分野、大手金融機関や製造業などのエンタープライズシステムにおける導入事例などを聞いた。(インタビュー実施:2018年11月)

米MarkLogic CEO兼社長のゲイリー・ブルーム(Gary Bloom)氏、マークロジック日本法人代表の三浦デニース氏(マークロジック 日本法人オフィスにて)
あらゆるモデルのデータソースを統合する「マルチモデルデータベース」
マークロジックの創業は2001年。「インターネット検索と同じように企業内の情報を検索できるようにしたい」と考え、エンタープライズ検索アプリケーションの開発に携わってきた創業者のクリストファー・リンブラッド氏が、さらに根本的な「データの持ち方」から刷新しようと開発したのがMarkLogicだとブルーム氏は説明する。

ブルーム氏
前述したとおり、MarkLogicはマルチモデルDBとして多様なデータをネイティブに格納できる。JSON/XML形式に対応したNoSQLのドキュメントDBであると同時に、PDFや画像/動画といったバイナリデータ、リレーショナルDBのデータ(構造化データ)、地理空間情報データなどの格納にも対応する。加えてRDFによるメタデータ(コンテキスト情報やエンティティどうしの関係性を記述したRDFトリプル)も融合しており、取り込んだデータはあらゆる角度からの検索が可能になる。

MarkLogicの概要。エンタープライズ顧客に特化した戦略を取っている
同時に、MarkLogicはACID特性を完全に実現するトランザクショナルDBであり、クラスタ間や別のDBシステムとの分散トランザクションにおいてもデータの喪失や破損を防いで一貫性を保つ。コモンクライテリア認証、NIST、FIPS、HIPAA、FedRAMPなど各種セキュリティ認証を取得しており、データ暗号化だけでなく匿名化や部分削除(リダクション)、ユーザーロールに基づく細かな制御などを通じてデータの機密性も維持する。
このようにMarkLogicは、一般に“NoSQL DB”という言葉でひとくくりにされる他の製品とは異なる性格を持っている。ブルーム氏によれば、マークロジックでは「エンタープライズ(大規模組織/企業)のミッションクリティカルな基幹業務システムのみをターゲットとする」戦略を取っている。DB機能だけでなく、エンタープライズ向けデータプラットフォームとしてセキュリティやインデキシング、検索エンジン、リモートレプリケーション/DRなどの機能も統合しており、グローバルで1000以上の組織/企業がMarkLogicを導入している。

MarkLogicの特徴。構造化/非構造化データ、メタデータをすべて「そのまま」取り込み、セキュアな基盤上で、柔軟なデータモデル変更や統合的な検索を可能にする
“データハブ”でリレーショナルDB+ETLツールの課題を解消する
マークロジックではこうした製品特徴を生かし、既存のデータソースと多様な形式のアプリケーションとの間を柔軟につなぐ“オペレーショナルデータハブ”の実現を提唱している。
「(オペレーショナルデータハブは)あらゆるデータをいったんMarkLogicに入れてしまい、セキュリティやガバナンスを適用して格納/保管しつつ、使い方(アプリケーション)に応じて変換して取り出すという考え方だ。一カ所からデータを取り出すので、データの一貫性も担保される」(ブルーム氏)
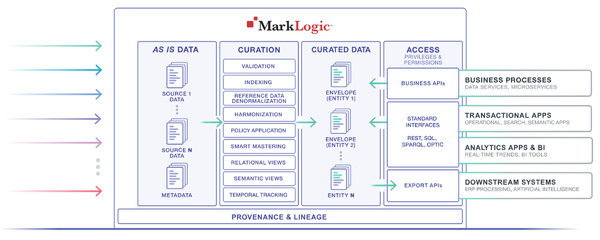
MarkLogicによるオペレーショナルデータハブの概念図(同社Webサイトより)
現在の顧客企業/組織は、社内のさまざまなデータソースを統合して活用したいと考えているが、従来型のRDBMSリレーショナルデータベース(RDB)とETLツールの組み合わせでそれを実現するためには大きなコストと時間がかかっていたと、ブルーム氏は指摘する。「データやアプリケーションが変化するたびに、ETLも作り込む必要があった。そのためアジャイルな環境ではなかった」(ブルーム氏)。MarkLogicのデータハブにより、そうした課題が解消されるというわけだ。
「最近はリレーショナルDBによってサイロ化してしまったデータを、データハブを通じて統合するというユースケースが多い。複雑化しすぎており、リレーショナルDBとETLツールでは実現できないと判断されたプロジェクトを、MarkLogicが引き継ぐというケースは多い。リレーショナルDB+ETLならば3~5年かかるような統合プロジェクトでも、MarkLogicならばほとんど1年かからずに完了できるアジャイルさも実現する」(ブルーム氏)
既存の基幹システムに手を加えず短期間でデータ統合を実現する
ブルーム氏はいくつかのエンタープライズ事例を紹介した。金融大手のJPモルガン・チェースでは、デリバティブ関連のポストトレード(取引後)処理を行う20個以上のリレーショナルDB(Cybase)からのデータをMarkLogicに統合することで、従来はバッチ処理で1日1回しか更新されなかった取引結果データが日中でも更新され、ポストトレード処理を行うアプリケーションが参照できるようになった。このMarkLogicは毎秒1600件のリクエストを処理し、DB管理者も10人から1人に減ったという。
「高速な取引処理を行う既存の基幹システム(データソース)自体はそのままで、そこからMarkLogicにデータを取り込んで統合し、検索や参照を可能にしている。金融業の場合はデータ保持に関するさまざまな規制があるが、MarkLogicがそれに対応している点もメリットだ」(ブルーム氏)
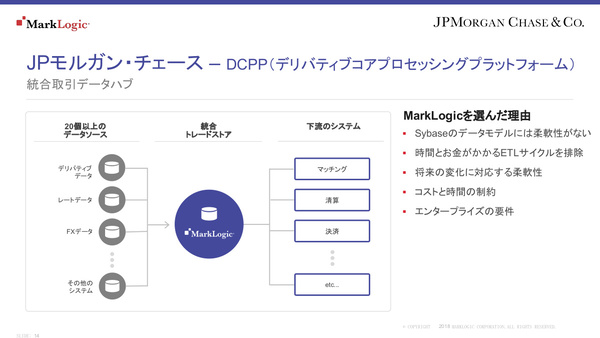
JPモルガンにおけるMarkLogicの導入事例。20以上のデータソースを統合、ETLツールを使わず下流システムでデータ活用可能にした
また米大手保険会社のエトナ(Aetna)では、企業買収(M&A)を繰り返してきた結果、人事関連システムが140個以上のデータソースを持つかたちに膨れあがっていた。これをリレーショナルDB+ETLツールで統合しようとしたが果たせず、MarkLogicで統合した。「顧客担当者は『リレーショナルDBでは実現できなかっただろう』と言っている。2つのプロジェクトが1年以内で完了した」(ブルーム氏)。
エネルギー大手(石油メジャー)のシェブロンでも、企業買収によって企業石油プラントの設計や部品に関する情報がサイロ化し、「そうした情報を得るために、プラントエンジニアは何時間もドキュメントを探さなければならなかった」(ブルーム氏)。これらの情報をMarkLogicのリポジトリに統合することで、たとえば問題が発覚した部品がどこに使われているか、影響範囲は、といったこともすぐにトラッキングできるようになったという。「リレーショナルDBならば8カ月かかると予想されていたが、MarkLogicは8週間でサービスインできた」(ブルーム氏)。

三浦氏
日本市場でも、海外と同じような活用事例が多いという。日本法人代表の三浦氏は「結局、海外で生じる課題は日本でも起きる」と述べ、たとえばHadoopを採用しデータレイクを構築したものの、柔軟な検索機能やガバナンスを求めてMarkLogicへ切り替えたケースがあると語った。日本市場の顧客プロジェクトに、海外で同様の事例を手がけたコンサルタントを連れてくることもあるという。
「日本市場では大きく2つの業種、製造業とライフサイエンス/創薬が伸びている。またパートナーは倍増しており、富士通、CTC、NTTデータといった日本のパートナーでは数百名単位でMarkLogicのトレーニングを行っている」(三浦氏)
製造業では、部品に関するデータをERPからMarkLogicに統合してどの製品に組み込まれたかのサプライチェーントラッキングを可能にした事例、大量のIoTセンサーデータから特定事象に関連するデータを引き出すシステムの事例などがある。また創薬分野では、構造化/非構造化データの混在する研究データを社内共有するために利用されており、規制機関に提出するための臨床データもMarkLogicに統合しているという。
ブルーム氏は、MarkLogicは既存カテゴリに当てはめることが難しく、説明するうえでは“NoSQL DB”というカテゴリ名よりも“データ統合に適したデータベース”という呼び方のほうがわかりやすいと語る。顧客への説明では、上述したようなユースケースを紹介することも多いと述べた。
「(リレーショナルDBなど)ほかの方法で実現できなかった顧客がMarkLogicにたどり着くケースが多い。もっとも、MarkLogicを知ったあとは次からMarkLogicを使おうということになり、われわれの売上のおよそ80%は既存顧客からのものが占める」(ブルーム氏)
「MarkLogicを一言で説明するのは難しいが、顧客が実際に使えばわかってもらえる瞬間が来る。われわれはそれを『なるほどモーメント』と呼んでいる(笑)」(三浦氏)
本記事はアフィリエイトプログラムによる収益を得ている場合があります



