



事例に厚みが増したAWS Summit 2017レポート 第7回
Dockerコンテナ+ECR、インフラ自動化など、サービス可用性を最大化する方法
「AWSだって壊れる」を前提に考えた可用性向上策、リコー事例講演
2017年06月13日 07時00分更新

AWS移行に合わせて「コンテナ技術」や「インフラのコード化」など適用
オンプレミスからAWSへの移行に際して、リコーでは大きく2つのポリシーを定めた。「基本的に同じ構成で移行すること」「徹底的に自動化すること」の2つだ。
ただし、同時に「コンテナ技術の採用」や「AWSのマネージドサービスの積極採用」「インフラのコード化」といった、ドラスティックな変更もここで行っている。運用開始後にドラスティックな構成変更を行うのは難しいので、移行のタイミングが「変更のチャンス」だと梅原氏は説明する。

移行において定めたポリシー
実際の移行作業ではまず、オンプレミス(プライベートクラウド)環境において、バックエンドシステムのコンテナ化を進めていった。梅原氏は、Dockerコンテナを採用したことで「可用性向上に大きく役立った」だけでなく、新しいアプリの開発時にサーバー環境(開発言語やバージョン)を気にしなくてよくなった点が大きなメリットだったと語る。
続いて、AWS側にコンテナ基盤を含むインフラを用意する。基本構成は、Dockerコンテナの管理サービスである「Amazon ECS(EC2 Container Service)」とレジストリサービス「Amazon ECR(EC2 Container Registry)」、そして「Amazon EC2」「Amazon ELB」となっている。

AWS側の基本構成。Dockerコンテナ管理/レジストリサービスのAmazon ECS/ECRを利用している
ここでは「EC2インスタンスが壊れた(ダウンした)場合」「インスタンス上のコンテナが壊れた場合」をそれぞれ前提として捉え、対策を行った。
インスタンスが壊れた場合は、AWSの「Auto Scaling」機能が自動的に新しいインスタンスを立ち上げる。さらに「cfn-init(CloudFormationのスクリプト機能)」が、立ち上がったインスタンスの自動再設定を行うため、自動的に元の環境に回復する。またコンテナが壊れた場合は、まずELBによって別の稼働しているコンテナにアクセスが振り分けられるおり、加えてマルチAZ構成の場合はほかのAZでコンテナが立ち上がっているので、いずれにせよサービスが停止することはない。
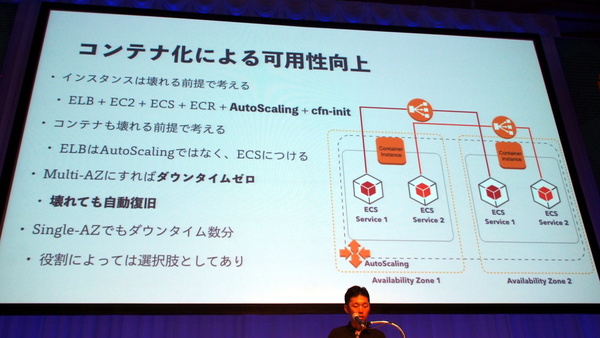
インスタンス、コンテナとも「壊れる(ダウンする)」ことを前提に可用性向上の対策を行った
さらに、一部のAPIサービスについては「Amazon API Gateway」「Amazon Lambda」「Amazon DynamoDB」を用いて“サーバーレス化”も行ったという。サーバーレス化によって、上述したインスタンスやコンテナの障害、あるいはデータセンター障害といったことを意識する必要がなくなるからだ。「AWSのマネージドサービス利用を極めていくと、行き着く先はサーバーレスになる」(梅原氏)。
一方で、AWSのマネージドサービスだけではうまくいかない部分もあった。梅原氏は、映像配信サーバーには特有の課題があり、単純なヘルスチェック機能やAuto Scaling機能とは相性が悪かったと説明する。これに関しては、グローバルの各リージョンに独自の仕組み(サービスレベルでの監視クライアント)を設け、映像配信サーバーの各系統が利用できるかどうかに応じて切り離し/切り戻しを行うこととした。なお、ここではマルチAZを使うことで、ダウンタイムゼロでの処理を実現している。
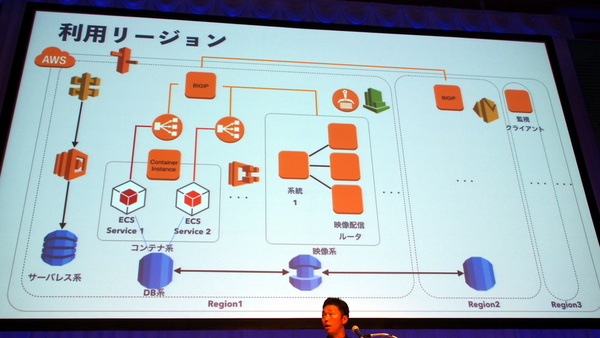
RICOH UCSのバックエンドシステム概要。現在、合計でおよそ20種類のAWSサービスを利用しているという
そのほか、MySQLから「Amazon Aurora」への移行による高速フェイルオーバー(停止数分→数秒)、ヘルスチェック値の最適化、自動復帰できないパターンの検証など「1秒でもサービス復旧を早くするために、できることはまだまだ多くある」と、梅原氏は説明した。
「本当に『インフラは1回作れば終わり』なのか」自動化のメリット
もうひとつの移行ポリシーが「積極的な自動化」だ。梅原氏は、移行におけるインフラ構築作業が繰り返し、2回以上に及ぶのであれば、その作業は自動化すべきだと語る。
「考えるべきことは、本当に『インフラは1回作れば終わり』なのか、ということ。実際、わたしたちは何度も作り直している」(梅原氏)
特に、開発環境やステージング環境は、必要なときだけ利用するインフラであり、そのたびに構築するため自動化のメリットが大きいという。また、基本的に作り直すことのない本番環境であっても、インフラ構築の自動化には「障害時の復旧を早める」メリットがある。
リコーでは、設定管理とオーケストレーションツールの「AWS CloudFormation」にオープンソースツールの「Kumogata」を組み合わせて利用し、自動化の基盤を整えている。ちなみに、開発環境は毎晩20時には自動的にシャットダウン、削除され、翌朝8時に作り直される仕組みになっているため、コスト削減やバグ混入のトラッキングなどに役立っているという。

リコーにおけるインフラの自動化(コード化)
さらに梅原氏は、イミュータブルインフラ化によって「インフラのバージョン管理」が可能になり、インフラ構築の“職人芸”がコード化されたこと、デプロイにおいても「Blue-Greenデプロイメント」が容易にできるようになったことなどを説明した。
可用性は実際に向上、次はアプリ/インフラの両方をふまえた対策へ
本格運用開始から約半年が経過し、梅原氏は「安心材料がたくさんあった」と語る。AWS移行によって大規模障害から解放され、インフラ稼働率は以前よりも向上している。「自動復旧の仕組みを入れているので、実際に障害が起きて自動復旧したケースもたくさんあった」という。
「可用性は実際に向上した。以前のインフラならば停止時間にカウントされていた障害を救うことができたほか、自動復旧にも幾度も助けられた。IaaS障害に強い設計ができたと思う」(梅原氏)

梅原氏は「事実、可用性は向上した」とまとめた
加えて梅原氏は、“可用性のボトルネック”が変わってきたことを実感していると語った。インフラ/IaaS側の対策で大規模障害を抑えることはできている一方で、インフラ側だけでなくアプリケーション側でのくふうが必要となることも増えているという。たとえば、前述した映像配信サーバーの例だ。
「要するに、アプリケーションの特性がこうだからインフラはこう改善しなければいけないとか、逆にインフラがこういう構成だからアプリケーションはこう構築しなければといったことが、さらなる可用性向上につながるのだと最近は考えている」(梅原氏)
まとめとして梅原氏は、クラウドであろうとも「インフラ障害は必ずある」という前提でシステム設計を行うこと、アプリケーションとインフラの双方を理解し、双方を改善していくことの2点を挙げて、講演を締めくくった。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第9回
クラウド
高齢化・労働力不足の農業をヤンマーのロボットトラクターは救えるか? -
第8回
クラウド
NASAとAWSが挑んだ宇宙からの4Kライブ中継の舞台裏 -
第6回
クラウド
日本の聴衆を戦慄させたAmazonの3つのイノベーション -
第5回
クラウド
新サービス登場とともに旧システムを捨ててきたJINSのAWS活用 -
第4回
クラウド
1日1000本の記事を書いた日経の“AI記者”、その基盤にAWS -
第3回
クラウド
ソラコム、NTT東日本、ソニーモバイル、グリーが語る「それぞれのAWS」 -
第2回
クラウド
ハイレゾ音源を含む300TBをAWS Snowballで移行したレーベルゲート -
第1回
クラウド
三菱UFJ銀登壇、大阪リージョン発表など「AWS Summit」基調講演 -
クラウド
事例に厚みが増したAWS Summit 2017レポート - この連載の一覧へ



