



事例に厚みが増したAWS Summit 2017レポート 第7回
Dockerコンテナ+ECR、インフラ自動化など、サービス可用性を最大化する方法
「AWSだって壊れる」を前提に考えた可用性向上策、リコー事例講演
2017年06月13日 07時00分更新

5月31日の「AWS Summit Tokyo 2017」では、法人向けテレビ会議システムのサービス提供基盤としてAWSを活用しているリコーの梅原直樹氏が、インフラ障害の発生を前提としたサービス可用性の向上策について講演した。AWS移行のタイミングで、Dockerコンテナやデプロイ自動化などに取り組んだという。

「AWS Summit Tokyo 2017」で講演した、リコー オフィスサービス開発本部 SI開発センター 第四開発室 クラウドPFグループの梅原直樹氏

講演タイトルは「サービス全断はダメ、ゼッタイ。途切れないテレビ会議システムを目指して」
グローバル展開するテレビ会議システムのバックエンドをAWSへ移行
「RICOH UCS(Unified Communication System)」は、ポータブル型専用端末やPC、スマートデバイスなどを使って利用できる、多拠点対応の法人向けテレビ会議システムだ。バックエンドサービスを、顧客内に設置するオンプレミスシステムではなくクラウドサービスとして提供しているのが特徴で、同社ではこのプロダクトを日本国内だけでなくグローバルに展開している。
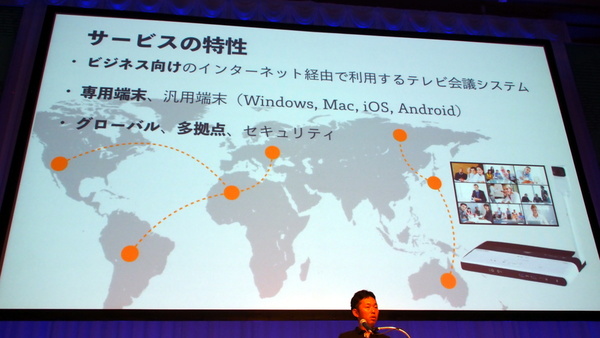
「RICOH UCS」は同社がグローバルに展開するビジネス向けのテレビ会議システムだ
RICOH UCSのバックエンドサービスを支えるインフラとして、当初およそ5年間はリコーのデータセンターに設置したプライベートクラウドを、そして現在はAWSを利用している。1年ほど前にDRサイトからAWS移行を開始し、昨年(2016年)12月からはメインサイトとしてAWSを利用、そして今月(2017年6月)には移行を完了する。
オンプレミスのプライベートクラウドからパブリッククラウドへ移行した理由について、梅原氏は、コスト高であったこと、物理リソースの追加や削除が柔軟でなかったこと、グローバルに拠点を展開して高品質のサービスを提供したかったことなどを挙げる。現在では、AWSがグローバルに持つ16リージョンのうち、11リージョンを利用しているという。
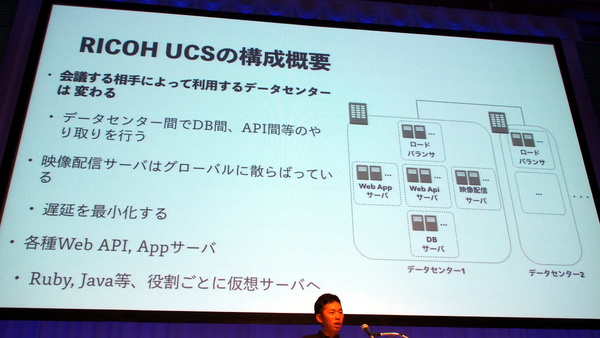
RICOH UCSのバックエンドシステム。映像配信サーバーはグローバルに分散し、顧客が最寄りのサーバーに接続することで遅延を最小化する
「止めてはいけないサービス」と「必ず壊れるインフラ」の矛盾
グローバル展開するRICOH UCSは、各国のビジネスタイムを考えると24時間365日、いつでも利用できなければならない。さらに、動画/音声の品質劣化や通話の切断といったサービス障害を起こさないことも重要だ。
「たとえば、お客様が大事な遠隔商談をしている最中に、テレビ会議の品質が劣化したり映像が途切れたりしてしまったら問題だ。つまり、RICOH UCSは『とにかく切れてはいけないサービス』だと言っていい」(梅原氏)
しかし、サービス品質保証は永遠の課題だ。特に、インフラについては「『壊れない』という前提で考えてしまいがち」(梅原氏)だが、実際には障害は必ず起きるものだ。実際、リコーでは2015年にオンプレミスのインフラで大規模障害を起こしてしまい、広範囲な影響を及ぼしてしまった苦い経験があると、梅原氏は振り返る。

リコーでは2015年に大規模なインフラ障害を経験し、サービスへも影響を及ぼしてしまった
それならば、AWS/パブリッククラウドへの移行により可用性が向上し、インフラ障害を考慮しなくても済むようになるだろうか。梅原氏は、オンプレミスインフラ障害の反省を込めながら「そうは思わない」と語る。「やはり『インフラは必ず壊れる』という前提に立ち、マインドチェンジしていく必要があるはず」(梅原氏)。
AWS移行を契機にサービス可用性を向上させるために、梅原氏は障害発生要素をレイヤーに分けて考えた。アプリケーションやサーバーレイヤーの障害と比べ、データセンターやリージョン、あるいは全リージョンに及ぶ障害の発生頻度は低い。それでも、絶対に障害が発生しないというわけではない。事実、今年2月にはAWSが米国でリージョン障害を起こしているし、昨年4月にはGoogle Cloud Platformが全リージョンに及ぶ障害を起こしている。

リージョン単位での大規模障害はAWSでも発生している
こうした検討の結果、リコーでは、コスト的にも技術的にも現実的なデータセンター単位の障害について取り組み、可用性を向上させていくことにした。
「障害は必ず起きるので、いわゆる『Design for Failure(障害を想定した設計)』の考え方を採用する。データセンター1つが丸ごとダウンしても、ほかのどこかでサービスを提供し続けられる環境を実現する。さらに可用性を高めるためには、障害検知を早くして、早く直すことが重要なので、自動復旧の仕組みを採用する。加えて、新規インフラをデプロイする際のダウンタイムもゼロにする」(梅原氏)

リコーが目標とした可用性レベルは「データセンター単位の障害でも復旧できるサービス」
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第9回
クラウド
高齢化・労働力不足の農業をヤンマーのロボットトラクターは救えるか? -
第8回
クラウド
NASAとAWSが挑んだ宇宙からの4Kライブ中継の舞台裏 -
第6回
クラウド
日本の聴衆を戦慄させたAmazonの3つのイノベーション -
第5回
クラウド
新サービス登場とともに旧システムを捨ててきたJINSのAWS活用 -
第4回
クラウド
1日1000本の記事を書いた日経の“AI記者”、その基盤にAWS -
第3回
クラウド
ソラコム、NTT東日本、ソニーモバイル、グリーが語る「それぞれのAWS」 -
第2回
クラウド
ハイレゾ音源を含む300TBをAWS Snowballで移行したレーベルゲート -
第1回
クラウド
三菱UFJ銀登壇、大阪リージョン発表など「AWS Summit」基調講演 -
クラウド
事例に厚みが増したAWS Summit 2017レポート - この連載の一覧へ



