
前回に引き続き、今回もRyzenの話だ。今回は、2017年2月5日~9日にかけてサンフランシスコで開催されたISSCC 2017におけるAMDの発表資料を元に、Ryzenの内部構造、主に回路的な工夫について解説しよう。
このうちいくつかの項目については、連載372回で説明したHotChipの内容とやや被ることをあらかじめお断りしておく。
FPUの改良で消費電力を15%改善
まず下の画像が基本的な要件である。x86命令レベルでは1サイクルあたり4命令のデコード構造だが、内部のmicro-opレベルでは1サイクルあたり6命令の処理が可能とされる。

Ryzenの概要。これとほぼ同じ内容が、体裁だけ変えてRyzenの説明会でも発表された
これにあわせて、Register File(演算の際に利用するレジスタの物理的な格納場所)の数もExcavator比で大幅に増やされている。またキャッシュ/メモリーに対するロード/ストアーのバッファも合計168エントリー装備され、リード 12/ライト 6の処理ポートが搭載されるという重厚な構成である。

Ryzenの物理構造。このうち一番下のAggressive Vt swapping and downsizing algorithmsはおそらくPure PowerやPrecision Boostを指しているものと思われる
このあたりまではHotChipsの説明とそう変わらないのだが、追加されたのは消費電力に関わる部分だ。IPCを40%以上改善するとともに、スイッチングの容量(≒スイッチングに要する電力)を15%以上改善する、としている。これを実現するための特徴として、以下の特徴が示されている。
- MiMCapを採用(これは後述)
- 内部は3種類の電圧供給とする
- コア毎と2次/3次ャッシュは電圧プレーンを分離する(つまりコアとあわせると1つのCore Complexに5種類の電源プレーンが存在する)
- 第3世代のAVFS(Adaptive Voltage Frequency Scaling)を採用する
まず、コア(4コア+8MB 3次キャッシュ)の構成を、インテルのおそらくはSkylake世代と比較したと思われる数字がこちら。
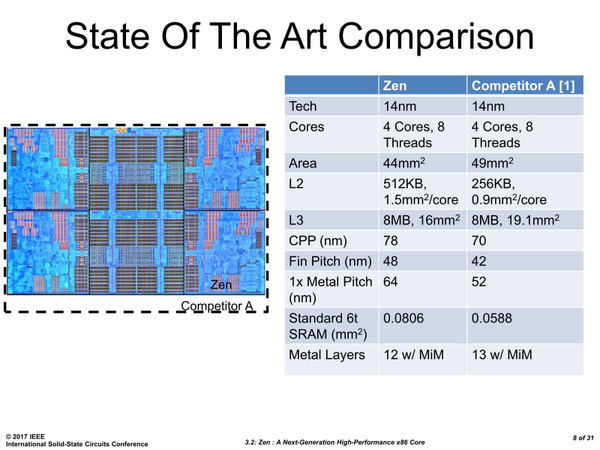
コアの構成。普通に6T SRAM(6トランジスタで構成されるSRAM)を作ると、インテルが0.0588平方mmなのに対し、Globalfoundriesでは0.0806平方mmと37%ほどGlobalfoundriesの方が大きくなることからも、インテルがいかに攻めたプロセスを提供しているかがわかる
同じ4コア/8スレッドであるが、2次キャッシュはSkylake比で倍の容量なのに、全体としてはRyzenの方がエリアサイズが小さく収まっている。
実際に比較すると、Fin Pitch(FinFETのFinの間隔)は48nm vs 42nm、CPP(Contacted Poly Pitch)は78nm vs 70nmということで、トランジスタの最小サイズはZenの方が27%ほど大きくなる。
そもそも昨今では、14nmプロセスと言いつつも、実際には14nmの寸法になっている部分は1つもない。その代わりにFin Pitch(プレナー型トランジスタの場合はTransistor Pitchなどとも呼ぶ)とCPPを使ってプロセスの大きさを判断することが普通だ。
これに関しては以下の経験則(ASML Formula:ASMLの法則)がある。
ノードサイズ=0.14×(CPHP×MMHP)^0.67
CPHPはCPPの半分、MMHPはFinPitchの半分をそれぞれ示す値で、上の数字を使うとRyzen(GlobalFoundriesの14LPP)は13.70nm、Skylake(インテルの14nm)は11.66nm相当になる。
要するにインテルの方が攻めたプロセスを利用しているわけで、同じ回路サイズならばRyzenの方がエリアサイズが大きくなるはずであるが、これを小さくまとめることができた、というのがRyzenの特徴である。
理由の一端は、FPU回りにある。Ryzenでは512bit幅のAVX-512をサポートしない。
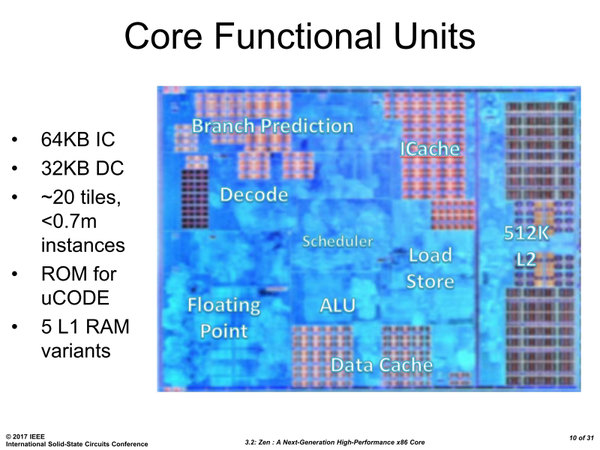
RyzenのFPU回り。もっとも昨今では、512bitのFPUを入れたからといってそんなにエリアサイズが大きくなるわけではないのだが、それでも節約するに越したことはない、という判断であろう
正確に言えばこれが実装されているのはXeon PhiとSkylake-EP/EXというXeon向けのコアのみで、デスクトップ向けのSkylakeやKabylakeでは無効化されているが、無効化されているだけで回路としては存在する。
結果、例えばAVXレジスタの量は4倍に増えている。初代のAVXレジスタは、SSE用のXMM0~XMM15という16個のレジスタ(128bit幅)を256bit幅に拡張したYMM0~YMM15が用意されるが、AVX512用にはこれをさらに512bit幅にするとともに、数を倍にしたZMM0~ZMM31が用意される。このスペースは馬鹿にならない。
当然FPUも倍の数が必要になるし、512bit幅のデータのロード/セーブを行なうために、ロード/ストアーユニットはRyzenの2倍にあたる4基が搭載される。当然データバスの幅もそれだけ確保しなければならない。
こうして考えていくと、AVX512を搭載するためのコストはけっこう高いものになる。実際AMD CTOのMark Papermaster氏が、質疑応答の中で明確に答えてくれた。
「AVX512の搭載は当初から考えていなかった。理由は2つある。1つはコストが高くつくことだ。もう1つは、もしそこまで浮動小数点演算性能が必要なら、我々は良いGPUを持っているから、こちらを使えば済む」
このあたりの割り切りも、小さなダイエリアの実現に貢献していると思われる。
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ













