




Cray X1の性能は
超並列の名機Red Stormの2倍以上!
Cray X1の場合は1つのキャビネットにこのノードモジュールが最大4枚で収められることになる。このキャビネット内の構造が下の画像である。
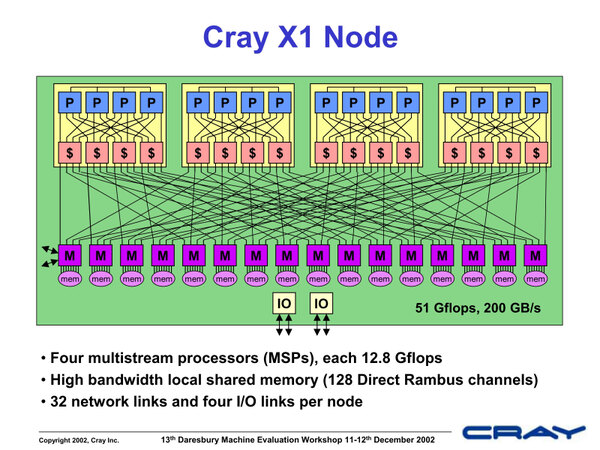
1枚のノードモジュール上にあるMSPとメモリーコントローラーは専有型ではない、という構造がおもしろい
4枚のノードモジュール上に搭載されているMSPとメモリーコントローラーがすべてお互いに直接接続されるという類のない構成であり、このあたりはCray T3D/T3E譲りとなっている。
キャビネットあたり4枚のノードモジュールというのは割と少なく、密度が低そうに思えるが、内部を見ると結構な部分を冷却ユニットが占めているようで、それも仕方ないのかもしれない。

Cray X1のキャビネット。一番下のポンプ類はフロリナートの循環用、その上の空洞に見える部分がフロリナートを冷却するための熱交換器が入っているものと思われる。両脇に見えるのがノードモジュール間の相互接続用のケーブルと思われる
ちなみに当時のカタログには、AC(Air Cooled)キャビネットで最大4ノード、LC(Liquid Cooled)キャビネットで最大16ノードとされており(1ノード=4CPU、つまりMCM1個が1ノード)、先のノードモジュールとキャビネットの写真はLCタイプのものと思われる。
キャビネット1個ではノードモジュール×4なので、4×4×4=64CPUでピーク性能は819.2GFLOPSに達する。実はこの性能は結構すごい。
同じCrayが手がけたRed Stormは、40TFLOPSを実現するために2GHzのOpteronを1万個強集積した(I/Oなどのための分もあるので、1万個では足りない)。この時には1キャビネットにOpteronを4つ搭載したCompute Bladeを最大24枚搭載できたので、ラフに言えばキャビネットあたり384GFLOPSになる計算だが、X1はこの倍以上の性能になっているからだ。
そしてもちろんキャビネット間はインターコネクトで接続が可能になっていた。
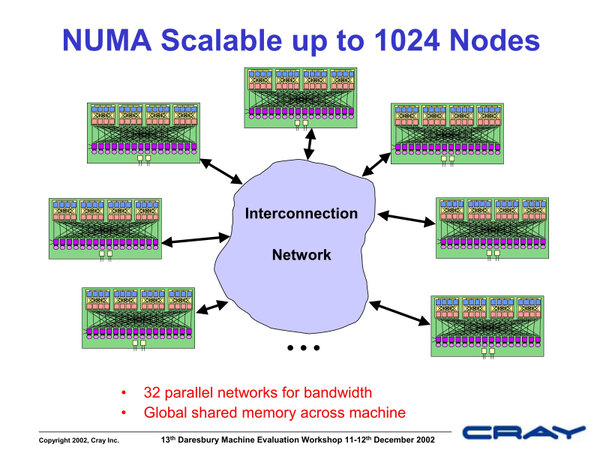
キャビネット間はインターコネクトで接続可能。さすがにキャビネットをまたいでのメモリー共有は非現実的というのはわかっていたようだ。このあたりはRedStormなども同じである
当時のカタログによれば最大64キャビネット、CPUの数にして4096個までを1つのシステムとして運用可能であり、この際のピーク性能は52.4TFLOPSに達する計算だった。これもRedStormの目標だった40TFLOPSを上回っている。
さて、このCray X1だが最終的には252コア(4キャビネット構成)のもののLINPACKの結果が2003年11月のTOP500に掲載される。理論性能3225.6GFLOPSに対して実効性能2932.9GFLOPSで効率は91%近く、非常に良い数字ではあるのだが、組織は「米国政府」とあるだけで詳細は明らかにされていない。
実はこれ、アメリカ国家安全保障局のようだ。となれば詳細が出てこないのも無理ないところ。実はこのX1、まだSGIの傘下にあった時代から、SV2の開発に関してNSAから一部開発補助を受けていたという話があり、これもあってSV2の開発そのものをやめることはできなかったらしい。
要するに国家安全保障局がどうしても高性能なベクトルマシンが必要で、それはRedStormのような超並列構成では実現できなかったのだと思われる。また、Cray-1以来のベクトルマシンに特化したアプリケーションが多数走っていたことも関係するであろう。
最終的に国家安全保障局に納入されたと思しきシステムは当初オークリッジ国立研究所に納入されて、ここで早期評価を受けた(pdf)。他には2003年に米陸軍高性能コンピューティング研究センターに導入したり(関連リンク)、アラスカ大学フェアバンクス校(UAF)が2004年に2キャビネット構成を導入(関連リンク)したり、あるいはオハイオスーパーコンピュータセンターもCray X1を導入している(関連リンク)。
ちなみにオークリッジ国立研究所への導入の際のインストールの様子が、オークリッジ国立研究所のCSMD(Computer Science and Mathematics Division)に掲載されている(関連リンク)。
他にも米国外への売却実績として韓国航空気象サービス、ワルシャワ大学数学・計算モデリング学際センター、スペイン気象庁などが挙げられているが、いずれにせよどこもキャビネット数はそう多くなく、トータルとしての売れ行きはあまり芳しくなかったようだ。
最後のベクトルマシンとなった
「Cray X1E」
これに続き2005年にはX1のアップグレードとしてCray X1Eが発表された(関連リンク)。大きな違いは、Cray X1では1つのMSPユニットを1つのMCMとして実装していたのに対し、2つのMSPユニットを1つのMCUに実装したことだ。
また動作周波数も800MHzから1.13GHzまで引き上げられており、この結果1つのキャビネットには最大128コアのベクトルプロセッサーが実装可能となり、性能はキャビネットあたり最大2.3TFLOPSと3倍弱まで引きあがった。
Cray自身による1キャビネット構成での結果がTOP500にも掲載されているが、効率は84.9%とX1よりもやや落ちるのは、メモリー帯域まで同じ調子でアップグレードするわけにはいかなかったことを考えるとむしろがんばったほうかもしれない。
こちらもいくつかのユーザーはX1からX1Eにアップグレードを行なったものの、そもそものユーザー数があまり多くなく、また新規にX1Eを導入したユーザーもあまりいなかったようで、結局このCray X1Eが本当に最後のベクトルマシンとなった。
理由は簡単で、超並列あるいはGPGPUなどを併用したシステムの方が導入コストだけでなく運用コストまで考えると低価格で済む、という潮流はいかんともしがたく、結果これまでベクトル向けのプログラムを保有していたユーザーが少しづつこれを超並列向けに書き換え始めており、ベクトルマシンに対するニーズそのものが減ってきたからだ。
実際、ベクトル性能を引き上げる方向は連載279回で解説したT90あたりで打ち止めになっており、その先はプロセッサーの数を増やすという方向にシフトしていたため、既存のベクトル向けアプリケーションも否応なく超並列に対する準備を必然的に迫られていたわけで、ただその移行にずいぶんかかったということだ。
T90が1995年の出荷で、X1Eが2005年であるから約10年。その間に、ユーザーはすでにベクトルから超並列にゆっくりとシフトしていたのが、Cray T1/T1Eがあまり商業的には成功しなかった理由だろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ














ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")

















