




GPU Technology Conference(GTC)は、NVIDIAが毎年開催しているGPU開発者向けのイベントだ。今年も3月17日から米国サンノゼ市で開催され、初日には、創業者でCEOのジェンスン・ファン氏による基調講演が行なわれた。

基調講演でTITAN Xを披露するジェンスン・ファンCEO
GPGPUの性能の活用法は
「ディープラーニング」(深層学習)!?
NVIDIAは、GPUやGPUボードのメーカーとして著名だが、最近では、GPUの汎用演算機能(GPGPU、General Purpus GPU Computing)に力を入れている。というのもPC向けのプロセッサは、GPUを統合していて、PC向けCPUを持たないNVIDIAは不利な状況にある。
そこで、同社が目をつけたのが、モバイルや車載などのPC以外の分野だ。たとえば、スマートフォンでは、ARMのシェアが高く、インテルといえども(ARMに後塵を拝する)1プレーヤーにすぎない。モバイル分野ではARM社が設計したCPUコアとGPUや周辺回路、メモリコントローラーなどを統合したSoCを半導体メーカーが製造し、これをスマートフォンやタブレットのメーカーが採用するという構造になっている。

基調講演の最後には、テスラのイーロン・マスクCEOが登場。ジェンスン氏と自動車の将来について話した
また車載用のコンピューターでもインテルのシェアは高くなく、また立ち上がり中の市場であるため、NVIDIAが参入する余地も十分にある。
GPUは、シェーダープログラミングなどで、もともと汎用演算が可能になっていて、画像データを生成するという構成から、特に単一の命令で多数のデータを同時処理するSIMD(Single Instruction Multiple Data)演算を得意としている。
このため、GPGPUを使うと、インテルのプロセッサのような汎用プロセッサに比べると高い演算性能を持つ。ただし、大量のデータを処理するというのが前提で、少量のデータを処理するような場合には演算性能はそれほど高くならないことがある。こうしたGPGPU機能を利用する専用システムとして、同社はTeslaなどのGPU応用製品を商品化している。
NVIDIAは、PC向けの高性能なGPUを開発してビデオボードを製品化する一方で、GPUをTegraシリーズに組み込んだり、科学技術計算向けのシステムにするなど、GPGPUをビジネスの大きな柱としつつある。その中で昨年話題になったのが「ディープラーニング」(深層学習)だ。
簡単に言うとディープラーニングは、大量の画像データを処理して自動分類したり、カメラ入力から歩行者や物体を識別するといった用途に応用されはじめている技術だ。大量の行列演算を必要とする処理であるため、GPGPUと相性がいい。
上の応用例からもわかるように、ディープラーニングは車の自動運転や画像、ビデオなどの認識などで需要が高まっている。あるいは、ディープラーニングによってはじめて実用可能になった分野もある。
画像や音声、言語などの大量のデータを
認識や識別する「ディープラーニング」
2015年のNVIDIAは、GPGPUの大きな分野としてディープラーニングを主要なターゲットとし、多くの製品がディープラーニングでの有用性があることを主張する基調講演を行なった。ある意味、NVIDIAはディープラーニングに“賭けている”といえるだろう。
実は昨年のGTCでもディープラーニングとGPUの関係が注目されていたが、NVIDIAはあくまでGPGPUの1分野というスタンスだった。しかし、今年のジェンスン・ファン氏の講演は、ほとんどがディープラーニング関係であり、ここで行なわれた4つのアナウンスは、すべてディープラーニングとなんらかの関係がある。また、GTCのセッションの多くがディープラーニングに関連した内容になるなど、その傾倒ぶりは半端ではない。
ディープラーニングとは、人の頭脳内にあるニューロンのネットワークを模倣した「ニューラル・ネットワーク」をコンピューターで実現するものだ。
応用方法としては画像や音声、ビデオ、自然言語などの認識、識別、分類などがあるが、最近はこの分野が注目されていて、さまざまな応用が登場している。GoogleやFacebook、Twitterなどのインターネットで大量のデータを扱う企業のほとんどがなんらかのディープラーニング関連の開発や研究のプロジェクトを持っている。
ニューラルネットワークは、多数のノードを接続し、入力された情報に対して、「重みづけ」をして次段のノードへ送る。1つのノードには、複数の入力(他のノードの出力)が接続されており、その状態によって、出力をどうするかを決める。ニューラルネットワーク自体は過去にもブームになったことがあったが、当時は、現在に比べると計算能力も高くなく、ノード数も限られていたこと、インターネット普及前であり、大量のデータも存在しなければ、これらに簡単にアクセスする方法もなかった。
その後の研究で、画像を高確率で認識できる技術や、特別な前処理、データに合わせたプログラミングなどを行なわなくても、ニューラルネットワークに直接画像データを送り込んで、結果を見て、自動で調整していくシステムを作ることができるようになった。こうしたシステムを「ディープラーニング」といい、それまでのニューラル・ネットワークのシステムとは区別する。
ここにうまくはまったのがGPUによる汎用演算機能だ。ディープラーニングでは、大量の行列計算を行なう必要があり、特にデータの特徴などを抽出する「学習」時には、動作結果から誤差を求め、それによってパラメーターを修正、さらに学習を繰り返すという形になるため、行列の計算速度が扱うことができるノードの数や学習にかかる時間を決めていた。GPUによる高速計算はディープラーニングを高速化し、実用的な学習時間、認識時間を実現したわけである。
基調講演で発表された4つのプロダクトは
いずれもディープラーニングに関連するもの
今年の基調講演は、このディープラーニングにNVIDAが大きくコミットしたことを示す内容となった。基調講演では4つのアナウンスが行われたが、それは新GPUボード「TITAN X」、ディープラーニングのためのソフトウェアパッケージ 「DIGITS」とこれを高速に実行できる「DIGITS DevBox」、そして次世代のGPUアーキテクチャ「PASCAL」と自動運転のためのコンピューターボード「Drive PX 」だ。
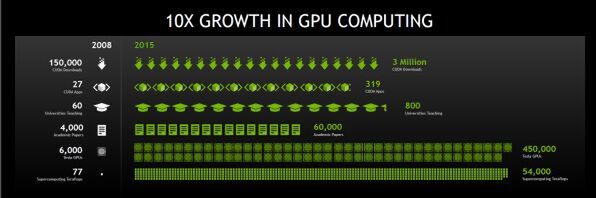
ジェンスン氏は、この7年のGPUの進化を振り返り、性能が10倍になっていることを示した
このどれもがディープラーニングに関わる製品である。とはいえ、NVIDIAは、ディープラーニングにしか使えないGPUを作るわけではない。GPU性能を上げ、ボードを開発する場合に、ディープラーニングを考慮しているだけとも言える。企業の存続をディープラーニング1つにだけ賭けるのは無謀すぎるし、いつかはディープラーニングも当たり前の技術になってしまうからだ。しかし、基調講演での表現は、ディープラーニング一色だった。
まず、ジェンセンCEOは、GPUの7年間の発展を振り返る。2008年のGPUに比べて2015年のGPUは10倍の性能を持つに至った。そして発表されたのが「TITAN X」こと「Geforce GTX TITAN X」である。これには、MaxwellアーキテクチャのGM2xx GPUチップが搭載されている。このチップには80億のトランジスタが集積されており、3072個のCudaコアが統合されている。単精度での演算性能は7T FLOPSで12GBのメモリを搭載する。価格は999ドルだ。

Titan Xは12GBのメモリーを搭載。3072個のCUDAコアを持ち、価格は999ドル
実は、ディープラーニングをGPUで処理する場合、搭載メモリ量が性能に大きく影響するという。メインメモリーとビデオカード上のメモリーの転送にはオーバーヘッドがあるため、大量のメモリーを搭載して、メインメモリーとの転送回数を減らすことで、性能が向上することになる。
TITAN Xでは、いつも通り、グラフィックスアニメーションを見せるなどの紹介があったが、ディープラーニング性能についても言及があった。16コアのXeonプロセッサでは43日近くかかるディープラーニングの学習処理がTITAN Xでは、2.5日で終わるという。前世代のTITAN Blackでも5日近くかかっているため、2倍の性能向上になったという。

TITAN Xでは、ディープラーニングの処理性能が前世代(TITAN Black)の2倍あるという
次にジェンスン氏は、ディープラーニングについて説明を行なっていく。たとえば画像の認識では、直接画像のドットをニューラルネットワークの入力として、さらに何段階ものノード層を配置、大量の画像データを入力して学習をさせていく。こうした様子をビジュアル化したものを見せ、いかに処理が大量にあるかを説明した。
また、画像にテキストによる説明を自動で付けるシステムのデモも行われた。画像を説明するためのキャプションはごく当たり前のものであっても、これまでは人が画像を見て文章を作るしかなかった。それを自動化できるようになったわけだ。

ディープラーニングを応用した画像に説明を自動的につけるシステムのデモ。上部のテキストはコンピュータが画像を認識して自動的に生成したもの
画像の説明は、掲載されるメディアや記事内容などの影響を大きく受け、同じ画像であってもメディアのジャンルが違えば、まったく違う内容になる。しかし、ジャンルを限定すれば、比較的短時間で実用システムになりそうな感じだ。実際アメリカでは、スポーツの実況中継やニュースの解説を自動で行なうシステムが研究されているという。
こうした分野向けにNVIDIAは、DIGITSというソフトウェアパッケージを開発した。これは、既存のディープラーニング用ソフトウェア(たとえばカルフォルニア大学バークレー校で開発されたCaffeなど)に対して、GPUを利用するためのコードを追加し、ユーザーインターフェースを追加したもの。これを使うことでGPUを使うディープラーニングの構築が簡単にできるようになる。

NVIDIAのDIGITSソフトウェアパッケージは、GPUを使ったディープラーニングのプラットフォーム
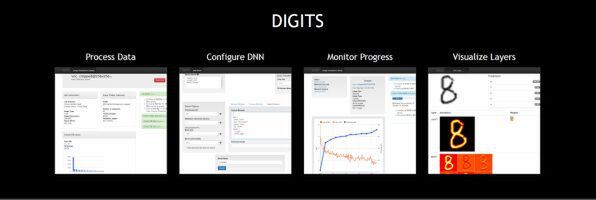
DIGITSには、ディープラーニングの設計や学習が可能で、そのための情報を表示するこのようなユーザーインターフェースも搭載している
さらに、このDIGITSを高速で処理できるハードウェアとして「DIGITS DevBox」を開発した。これは、TITAN XなどのGPUボードを最大4枚搭載可能なワークステーション(PCアーキテクチャ)だ。OSにはLinuxが搭載されており、DIGITSがインストールされている。主にディープラーニング用のニューラルネットワークの設計や学習を行なわせるためのシステムだ。価格は1万5000ドル。今年5月には出荷が開始されるという。

DIGITS DevBoxは、TITAN XなどのGPUボードを4枚搭載可能なディープラーニング向けシステム。今年5月からの出荷で、価格は1万5000ドル
(次ページでは、「来年登場のPASCALはディープラーニングで現世代の10倍の性能」)
本記事はアフィリエイトプログラムによる収益を得ている場合があります














ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")

















