




CPUの高速化についていけないメモリーの速度
今回からはちょっと趣を変えて、「キャッシュ」の話である。キャッシュの目的は「レイテンシの遮蔽」にある。といきなり大上段に構えても話が通じないので、昔話から始めよう。

図1 初期のCPUとメモリーの組み合わせ
初期のPCの場合、図1のようにCPUとメモリーが直結(厳密に言えばメモリーコントローラーを介する)されていた。初期というのは、おおむねi386ないし互換チップセットが利用されていた頃までの話である。
この頃は、CPUの速度が速くても30MHz程度。対するメモリーチップの速度は100ns(10MHz)~80ns(12.5MHz)程度。たまに70ns品(≒14.3MHz)や60ns(≒16.7MHz)品が高値で販売されるという、ある意味のどかな時代であった。
もちろん、これでもCPUの速度には追いついていないが、例えば2~4ウェイ・インターリーブでアクセスすれば、40~50MHz相当で利用できる。こうした動作をサポートしていたメモリーコントローラー(チップセット)もあったから、性能面での乖離はそれほど大きくなかった。
ところがその後、486以降(正確に言えばi486DX2以降)は、乖離が急に大きくなる。まずコアの動作周波数とFSBの速度が一致しなくなった。その始まりは486DX2/40~66だ。FSBは20~33MHzなのに、CPUコアは40~66MHzで動作するため、どんなに高速なメモリーを持ってきても、メモリーアクセスはコアの半分の速度でしかできないようになった。
当初この差は2倍程度だったが、486世代でもAMD CPUでは差が4倍に広がった。さらに、一番極端だったPentium 4ベースのCeleron/Celeron Dの場合、400MHz FSBで2.8GHz駆動(7倍)とか、533MHz FSBで3.6GHz駆動(6.75倍)の製品も存在した。こうなると、メモリーアクセスが発生した瞬間に、この差がボトルネックとなる。
別の問題もある。386までは内部の処理にマイクロコードを多用しており、命令のレイテンシーがかなり大きかったから、メモリーアクセスに余分な待ちが入っても、性能面での大きなインパクトはなかった。ところが486以降は、ワイヤードロジックにより命令のレイテンシが大幅に改善したため、逆にメモリーアクセスのレイテンシが非常に大きな問題になり始めた。プログラムのロードや演算結果の書き出しにもメモリーアクセスは必須なので、CPUだけ高速化しても、これを高速化しないと意味がない。
読み込み時のキャッシュの基本的な動作

図2 CPUとメモリーの間にキャッシュを配置
そこで考えられたのがキャッシュである(図2)。当初のキャッシュはCPU内部におかれていたが、CPUの外にあっても中に置いても、基本的な動きは変わらない。読み込みの場合を考えてみよう。まずCPUはメモリーに対して、読み込み要求を発行する(①)。
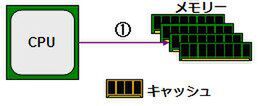
① CPUからメモリーに読み込み要求発行
これを受けてメモリーは、指定されたアドレスのデータをCPUに送り出すが(②)、この際にキャッシュにも同じデータを送り出す(③)。
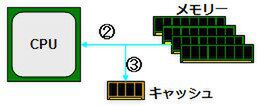
② メモリーからCPUにデータを送る。③同時にキャッシュにも同じデータを送る
以後、同じデータをCPUが要求した場合は、メモリーではなくキャッシュから読み出す(④)ことで、メモリーより高速に読み出しできるというものである。つまり、「1回目の読み出しは遅いが、2回目以降は高速に読み出せる」というのがキャッシュの仕組みである。
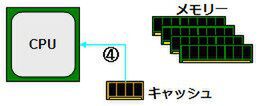
④ 同じデータの要求に対しては、キャッシュからCPUにデータを送る
速度を担保するため、通常のキャッシュはSRAMで構成される。これはCPUの内部回路と同じく論理回路のみで構成されるので、高速化されたFSBはもとより、CPUの内部に組み込んでも十分機能する。問題は、SRAMはコストが掛かる(=必要とするトランジスターが多い)ことである。
技術的には、最小なら4T SRAM(トランジスター4個でSRAM 1bit分)が可能だが、現実問題としては6Tや8T SRAMが多く使われていた。最近では8T構成はほとんど見なくなり、6T SRAMが主流になっているが、トランジスター1個(とキャパシタ)で構成されるDRAMに比べると、ずっとコストが掛かる。今のように潤沢にトランジスターが余っている時代はともかく、かつては少しでもトランジスターの数を減らしたいものだったから、SRAMに大量のトランジスターを割くゆとりはなかった。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























