



ロードマップでわかる!当世プロセッサー事情 第873回
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃
2026年04月27日 12時00分更新

GPUの性能限界を打破する「GPM」と「MSM」の分離
そこで論文ではGPUをGPM(GPU Module)とMSM(Memory System Module)に分割し、これをチップレット構造で接続するという方法を提唱した。下図にある(a)が従来型のものである。
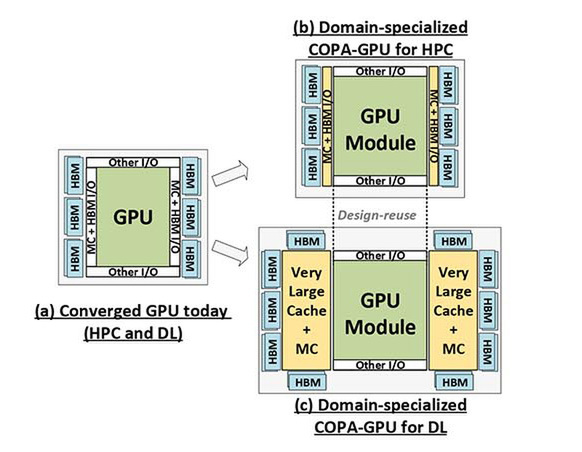
NVIDIAが2021年に発表した論文にある図を拡大したもの
ここからMSMを分離したうえで、HPC向けには最小限のLLCとHBMを接続する形にするのが(b)のHPC向け、大容量LLCと強化したHBM帯域を利用できるようにするのが(c)のDL向けだ。
ここでGPMとMSMをどう構成するか? ということで提案されたのが下の画像だ。
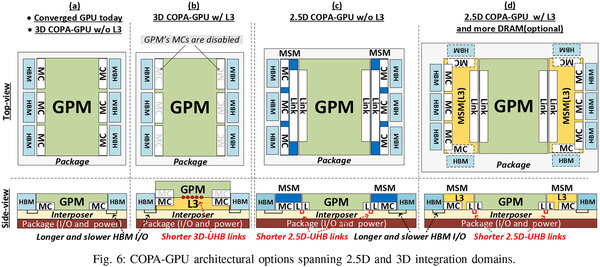
GPMとMSMをどう構成するか? を示した図
(a)がPascal~Rubinまで利用されてきた構図である。これに対して(b)~(d)は以下の格好となる。
(b) L3キャッシュをGPMの下に3D積層。またメモリーコントローラーをL3側に移動。要するにL3付きMSMの上にGPMが載る形になる。
(c) MSMをGPMの両端に配し、間をシリコン・インターポーザーで接続する形。一番実装は楽。
(d) (c)の構成でMSMにL3も追加する構成。当然MSMの大きさは(c)よりも大型化すると思われる(そこで上下にHBMをさらに追加する案まで出ている)。
見たことがある構成だな、というのは当然で(d)はAMDのRDNA 3ベースのRadeon RX 7000シリーズで実装されているし、(b)は同じくAMDのInstinct MI300シリーズの実装そのものである。(c)は強いて言えばインテルのPonte Vecchioがこれに近いと言えるだろう。
NVIDIAは2021年の時点で、こうした構成を検討するほどに先見の明はありながら、製品に関しては構成に保守的な態度だったが、さすがにここに来てもうチップレットによるモジュール化待ったなしになったというべきか。論文では実際にさまざまなシミュレーションを行ない、COPA構成をとったGPUは、非COPA構成のGPUの2倍の性能を発揮できると結論付けている。
前掲の2028年ロードマップに戻ると、FeynmanはDie Stackingと明記されている時点で3D COPA-GPU w/L3の構成を取っている可能性は非常に高いだろう。もっともこの論文がなかったとしても、GPUのダイに大容量キャッシュとメモリーコントローラーを集積したダイを3D積層するというのはごく自然な流れである。
プロセスを微細化してもSRAMの容量はそこまで増えないし、NVIDIAのGPUはReticle Limitの限界に挑戦するような大きなダイサイズにすでに達しているため、ダイサイズを増やすわけにもいかない。そして水平方向にL3を増設する(上の画像(d))方式は、GPUとLLCの距離が長くなりすぎる。これは特に消費電力の観点で不利であり、3D接続にするのがごく自然であろう。
懸念事項を挙げるとすれば、実装はTSMCのSoIC-Xになるのだろうが、SoIC-XはAMDは3D V-CacheやInstinct MI300シリーズですでに実績を重ねているが、Instinct MI300XのGCDは110mm2とかなり小さい。Feynmanのダイサイズがどのくらいになるかは不明だが、これまでの経緯を考えると600mm2を切ることは考えにくい。
ただこれだけのサイズのダイをSoIC-Xで接続して、温度変化などに起因する歪の影響をカバーしきれるのか、はTSMCにとっても未知数であろう。あるいはAMD同様にGPMの方も細かく分割して実装する可能性もあるが、これまでのNVIDIAの製品を見ると考えにくい。
Feynmanがどんなプロセスで製造されるのかは不明だ。可能性としてはGPMがTSMC A16か、ひょっとするとN2Pあたり、MSMはTSMC N3あたりではないかと予想する。N5/N4ではHBMの速度が間に合うか怪しいからである。
これに組み合わされるのはカスタムHBMであるが、昨今のHBMはなかばセミカスタムと化している。もちろん汎用品もあり、メモリーメーカーは自社あるいはTSMCなどに委託して一番下のロジックダイを製造、その上に自社製造のDRAMダイを積層していく形だが、技術力のあるメーカーはその一番下のロジックダイを自社で設計・製造してこれをメモリーベンダーに提供。メモリベンダーはロジックダイの上に自社のDRAMダイを積層する形だ。
すでに世の中にはNVIDIAのロジックダイを積層したHBMメモリーというのは存在しており、その意味では単なる実情の追認に過ぎないのだが、あえてここでカスタムHBMと書くからにはJEDECで定めた仕様から外れたカスタム仕様(例えばピン数を勝手に増やすなど)になっている可能性がある。このあたりは6月のCOMPUTEX、あるいは10月のGTCあたりでもう少し詳細が出てくるかもしれない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")



















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












