




























人手による修正コストを削減、生成AI活用した「PDF構造化技術」でPDFデータを読み取るソリューション開始
文● ASCII
Irwin&co株式会社は1月6日に、生成AIを活用した「PDF構造化技術」によってPDFデータを読み取る法人向けソリューションの正式リリースを発表した。同技術は、不動産マイソク(販売図面)、登記簿謄本、帳票等のPDF、PowerPoint・Excel等からエクスポートされたPDFが混在する非定型フォーマットにおいて、99.9%のデータ読み取り精度を実現するとのこと。従来のAI OCRでは避けられなかった「目視チェックと手修正」の手間を解消するという。

多くの企業がデータ入力業務の効率化を目的に「AI OCR(光学文字認識)」を導入しているが、作業が「期待したほど楽にならない」という声も聞かれるという。同社によると、その原因は従来のOCR技術が抱える構造的な課題にあるとのこと。PDFを画像として処理するため、読み取り精度は90%程度にとどまるそうだ。また、表組みや段組が複雑な書類では、どの数値がどの項目かを文脈から理解できずに正しくデータ化できない場合があるという。
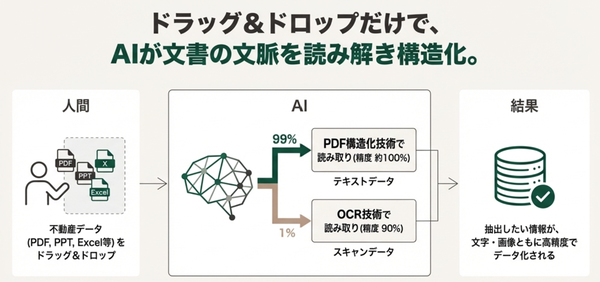
同社では、AI OCRとは異なるアプローチで同システムを開発。従来のOCRがPDFを「画像(絵)」として読み取っていたのに対し、「PDF構造化技術」ではPDFを「意味と構造を持つ文書」として認識。テキストデータを含むPDFに対しては、テキスト情報を直接抽出し構造化し、精度を高めるとのこと。スキャンデータ等の画像PDFに対しては画像解析を行うハイブリッドな処理によって、全体として99.9%という読み取り精度を達成したという。

本記事はアフィリエイトプログラムによる収益を得ている場合があります
