



Intel Tech Tour 2025取材レポート【その3】
Panther LakeのGPU「Xe3」はなぜArc Bシリーズなのか?16コア12Xe版のゲーミング性能は前世代の倍でマルチフレーム生成も発表
2025年10月21日 13時00分更新

協調ベクター対応もアピール
そして、今回インテルはDirectX 12に導入される予定の「協調ベクター(Cooperative Vectors)」対応もアピールした。これはCES 2025でNVIDIAが先鞭をつけた「ニューラルシェーダー」のDirectX上での呼び名で、GPUで実行されるグラフィックスパイプラインにAIのニューラルネットワークを組み込むことを可能にする技術だ。
協調ベクター自体は特にXe3のような最新GPUが必須というわけではない。とはいえ、Panther LakeのGPUに搭載しているXMXを利用すればよりスムースに協調ベクターが動作する、とアピールしたいわけだ。

XMXを利用することでグラフィックスパイプライン内でのAI処理がスムースになる。これはMicrosoftとの緊密なパートナーシップにあるとも強調した
協調ベクターの例としては、2次元の映像から3次元モデルを生成する「NeRF(Neural Radeiance Field)」を紹介した。些細なオブジェクトをすべてモデリングしなくても、色々な角度から撮影した画像を用意すれば、それらしく見えるオブジェクトになって3D的に描画されるという技法だ。
つまり、ゲームに登場する些末な小物をNeRFで描画することで、小物をモデリングする手間を大幅に簡略化することが可能になる。ただし、AI処理が入るぶんフレームレートに影響が出ることは間違いないため、今後の発展次第といったところか。
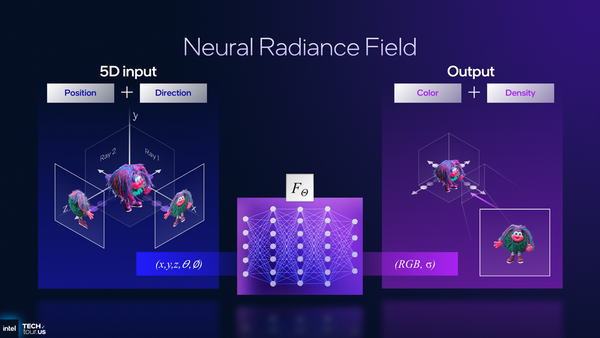
NeRFは複数の映像と角度、座標をニューラルネットワークに渡すと、それが3Dのモデルのようにレンダリングされる。中央にあるFΘの部分の処理をXMXに担当させることでよりスムースに実行できる

16コア12Xe版Panther LakeのGPUのインフォグラフィック
まとめ:「効率こそすべて」なXe3
CPUに引き続きGPUも「斬新さ」は少ないが、細かい最適化と改善の積み重ねで性能を伸ばしていることがわかる。特に電力効率については徹底的にテコ入れしており、モバイルPC向けCPUに搭載するGPUとしては順当な進化であるといえる。現時点でCPU内蔵GPUとしては最強であるAMDの「Radeon 890M」にどこまで食らいつけるか楽しみである。
本当はNPUやIPUもカバーしようと思ったが、セッション2つぶんの資料を盛り込んだら予想外に分量が多くなったので、今回はここまでとしたい。次回はNPU/ IPU、Wi-FiやBluetoothといったPanther Lakeの周辺技術の話をお届けしよう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります













で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")
























