



Intel Tech Tour 2025取材レポート【その3】
Panther LakeのGPU「Xe3」はなぜArc Bシリーズなのか?16コア12Xe版のゲーミング性能は前世代の倍でマルチフレーム生成も発表
2025年10月21日 13時00分更新

最適化を徹底することで進化したXe3
最大6基のXeコアをレンダースライスに詰め込めるようになったことだけがXe3の特徴ではない。Xeコアの内部に格納しているXVE(Xe Vector Engine:GeForceならCUDAコアに相当する部分)が改良され、スレッドの同時処理数がXe2と比較して最大25%増加した。演算ユニットの利用効率が向上したことで、重いシェーダーを走らせるゲームグラフィックスやAIの処理において性能向上が期待できる。
処理効率を上げるための大きな工夫として、GPU内における最も重要なリソースの1つであるレジスターの効率的運用に手をつけた。GPU内のレジスターの割り当ても可変割り当てを導入し、スレッドごとに必要なレジスター数を調整できるようになった。従来はスレッドごとのレジスター割り当て数が固定されているため、処理の複雑さによってはレジスターが余る・不足するといった無駄が生じる。これを動的に割り当てることでレジスターの過不足が発生しにくいようにしたわけだ。
もう1つの大きな改善は、XVEやXMX(Xe Matrix Engine:GeForceならTensorコアに相当)などの共有メモリーといえるL1キャッシュの増量だ。Xe2では192KBだったがXe3では256KBになり、33%の増量となった。これにより、レイテンシーの改善やVRAM(内蔵GPUなので実態はメインメモリー)へのアクセスを減らせる。
ほか、レイトレーシングユニットの強化やXVEを使わずに処理する固定機能(異方性フィルタリングの処理など)も強化。CPUのアーキテクチャーと同様に、コアそのものの内容は大きく変えてはいないものの、最適化できる部分を積み重ねて性能を伸ばしているわけだ。電力の制限が厳しいモバイルPC向けGPUならではの尖らせ方といえる。

Xe3アーキテクチャーの強化はXVEの処理効率の向上、レイトレーシングユニットの強化、固定機能の強化の3本柱

XeコアのL1キャッシュ(中央下で半分消えかかっている部分)は、XVEやXMXから見れば共有メモリー(ゆえに、SLM:Shared Local Memoryと書いてある)といえる機能である。これをXe2比で33%増やすことで、メモリーアクセスを減らし、レイテンシーを改善できる

Xe3ではXe2よりもスレッドの処理数が25%増加したほか、レジスターの動的割り当てで処理効率を向上。さらに、AI系の処理用にFP8の逆量子化(dequantization)にも対応している

Panther LakeのGPUでもレイトレーシングは無視できない。レイトレーシングユニットにおいては、レイを飛ばしてどのトライアングルに衝突するかをテストする際に処理する順序を考える必要がある。この順序の並びを考える処理が追いつかない時はレイを飛ばす処理を遅らせる、という「レイの動的解決機能」を実装した。並び替え処理を待つレイが多量に渋滞することで発生するレイトレーシングユニットの窒息を回避する機能、といったところか

Xe3では異方性フィルタリングの性能を2倍にした。異方性フィルタリングはイマドキのディスクリートGPUでは最高のx16でもたいした負荷にはならないが、モバイルPC向けのGPUだとまだ重いという感じだろうか。また、URB(Unified Return Buffer)マネージャーは先のレイトレーシングユニットの強化と関連している

Xe3のAI処理性能は最大120TOPSに到達(16コア12Xe版の場合)。Lunar Lake時代はCPU全体で120TOPS、GPUだけだと67TOPSなのだから、Panther LakeのAI処理性能はLunar Lakeの2倍近いといえる。ただし、これは12Xe版の話なのでXeコアが最も多いからTOPSも伸びた、という話ではあるのだが……
Xe2より性能は50%向上、ワットパフォーマンスは40%向上?
ここまでの最適化や改善でどこまで性能がLunar Lakeよりも伸びたのか? この疑問の答えるが次の図だ。これは機能ごとの性能改善をまとめたものだが、Xe2とほとんど変わらない部分もある一方で、異方性フィルタリングやレイの衝突判定といった処理では2倍、レジスターを多量に消費するようなシェーダー処理では2倍〜3倍、といった感じ。
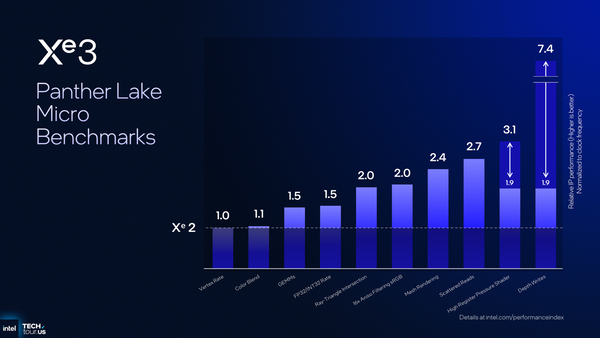
Xe2とXeの性能差を示した図
今回、インテルはLunar LakeのGPUとPanther Lakeの16コア12Xe版のGPUを比較したデータを多数用意した。しかし、前者はXeコアが8基で後者は12基のため、Panther Lakeのほうが有利であることは明白である。
ただし、ゲーム1フレームの処理における時間を見ると、Xeコアが12基のPanther Lakeは8基のLunar Lakeの半分程度(=処理性能は約2倍)で終えている。Xeコア数比だと性能は1.5倍にしからないが、各所の改善を積み重ねることで2倍に到達したことになる。
とはいえ、その点を考慮してもやはり8コア版のPanther LakeのGPU性能は、Lunar Lakeよりも若干劣ることになる。Panther Lakeの8コア版はGPU性能があまり重要ではないセグメントに投入されるとしても、これはやや残念な話だ。
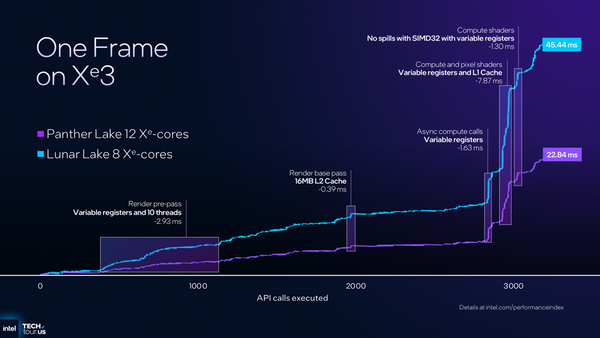
インテルのGPUではよく出てくる1フレームの処理時間を比較するグラフ。横軸はAPIコール数(描画処理の進捗)で、縦軸はそれにかかった時間(単位はミリ秒)である。Panther Lakeの16コア12Xe版はLunar Lakeの半分程度の時間で済んでいる。Panther Lakeはさまざまな改善のおかげでXeコア数比以上に性能を改善している、がインテルの主張である
Arrow Lake、Lunar Lake、Panther LakeのGPU性能を概観すると、性能はLunar Lakeから50%向上、ワットパフォーマンスはArrow Lakeから40%向上と謳う。CPUと同様にGPUも根本的な設計はそのままに、細かい最適化や改善の積み重ねでワットパフォーマンスを大幅に向上させることは、モバイルPC向け製品ならではのアプローチだ。
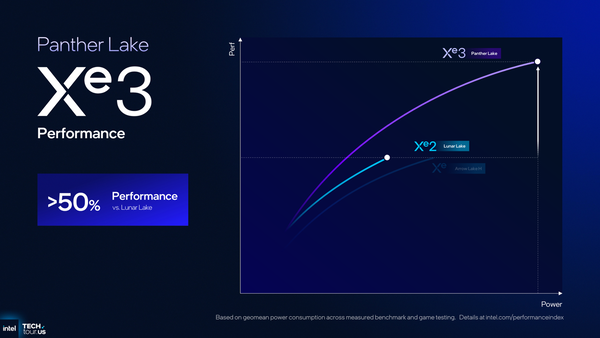
Panther Lake16コア12Xe版の性能は、Lunar Lakeより50%向上。Arrow Lakeとの比較には言及されていないが、Arrow Lakeの性能-電力カーブの上端を見ると、実はLunar Lakeとほぼ同じところで止まっている。つまり、Arrow Lake基準で見てもPanther Lakeの16コア12Xe版は50%向上しているということになる
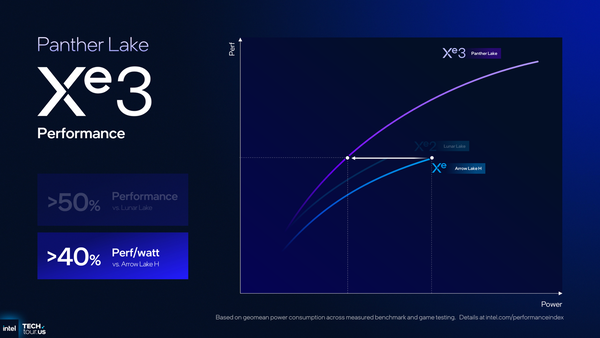
同じ性能であれば、Panther Lakeの消費電力はArrow Lakeよりもずっと低く、ワットパフォーマンスでは40%向上している。ここではLunar Lakeへの言及がないものの、Lunar Lake比で見ると20%向上といった感じだろうか。Xeコアが12基に増えても消費電力が下がっていると考えれば、順当すぎる進化と言えるだろう
本記事はアフィリエイトプログラムによる収益を得ている場合があります













で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


























