



Intel Tech Tour 2025取材レポート【その2】
Tick-Tock戦略の再来?Panther Lakeが前世代から大きく変わらず性能が向上した理由
2025年10月17日 10時00分更新

CPUコアは「Cougar Cove」と「Darkmont」に刷新
Panther LakeではPコアとEコアのアーキテクチャーもIntel 18Aに合わせて最適化した「Cougar Cove」と「Darkmont」になった。Meteor LakeからArrow LakeやLunar Lakeに進化する過程において、CPUコアのアーキテクチャーは常に刷新してきたわけではない。特にArrow LakeではLP EコアとEコアのアーキテクチャーが異なる(SkymontとCrestmont)など、混沌とした製品もあったのだ。だが、Panther LakeはPコアとEコアのアーキテクチャーが揃って1世代新しくなった。これはMeteor Lake以来の大きな変化といえる。

Panther LakeではIntel 18Aに最適化した新しいCPUコアアーキテクチャーを採用。どちらもより高い性能をより低消費電力で実行することにフォーカスしている

どの世代がナンタラCove、カンタラmontを使っているのかすぐに忘れるので、この図はありがたい。Meteor LakeからLunar Lakeまで、ところどころ前世代のものを継承しつつ小刻みに更新していったが、Panther LakeはPコア、Eコア、LP Eコアすべてを刷新した。ここ4世代の中では久々の完全リニューアルなのである
Cougar Coveは、Lunar LakeのLion Coveと同様にSMT(ハイパースレッディング)に対応しない。下の図からも明らかなように、Lion Coveからデコーダーや演算器(ALUなど)の数に関してはまったく変わっていない。

Cougar Coveのブロック図。右に出ている箱の種類や数に関しては、Lion Coveからまったく変わっていない。一方で、左に列挙されたメモリーディスアンビギュエーションやTLBの強化、分岐予測の改善によって性能を最適化したという表現のほうが正確だろう
ではなにを変えたのかといえば、これまで存在していた無駄を極力省くことでIPCを向上させる工夫を各所に凝らしている。その1つが「メモリーディスアンビギュエーション(Memory Disambiguation:曖昧性解消)」の挙動である。現在のCPUでは実際のプログラムの実行順序を一旦無視して実行する(いわゆる、アウトオブオーダー実行)ことがあるが、メモリー上のデータを読み書きする順番を間違えると大変なことになる場合がある。
例えば、2つの処理(AとB)がそれぞれアドレス(XとY)を参照している(AがXを参照、BがYを参照といった具合)なら、両者に依存関係はないので並列に実行できる。しかし、AとBが同じアドレスXのデータを参照しているなら、プログラム(機械語)に記述している通りの順番で実行させなければならない。AとBを実行する順番が入れ替われば、結果が変わってしまう可能性があるからだ。
この判定に関わる機能がメモリーディスアンビギュエーションである。Cougar Coveではこのロードとストアの関係の予測精度を向上させることで、命令スケジュールを最適化。順番を無視していい処理は先行して進められるため、結果的にIPCの向上につながるというわけだ。さらに、分岐予測はLion Coveで導入したアルゴリズムを改良し、予測精度の向上と同時に処理可能な分岐数を増加している。
だが、分岐予測を強化するとそのぶんキャッシュ効率も重要になる。そこで、キャッシュのTLB(Translation Lookup Buffer)の容量も従来の1.5倍に拡大している。より多くの分岐履歴を保持できるようになったので、分岐予測ミス時のペナルティーを軽減できるようになるわけだ。
以上をまとめれば、Cougar CoveはLion Coveの基本的構成はそのままに、メモリーディスアンビギュエーションや分岐予測などの強化によって効率を最適化し、IPCの向上を狙ったアーキテクチャーであるといえる。
Panther Lakeではプロセスルールどころか配線技法まで変えてしまったが、流石にコアの中身まで完全新規IPを導入することはリスクが大きかったとみえる。絶対性能よりも電力効率の向上率を重視するモバイルPC向けCPUだからこそ、電力効率重視の設計に舵を切ったことは手堅い選択かもしれない。
インテルによれば、シングルスレッド性能はArrow Lake-HやLunar Lakeに比べ、10%程度伸びるという。そのうえで、Arrow LakeやLunar Lakeと同程度の性能であれば、実に40%少ない消費電力で動作する。Cougar Coveは電力効率の改善に注力したアーキテクチャーなのだ。
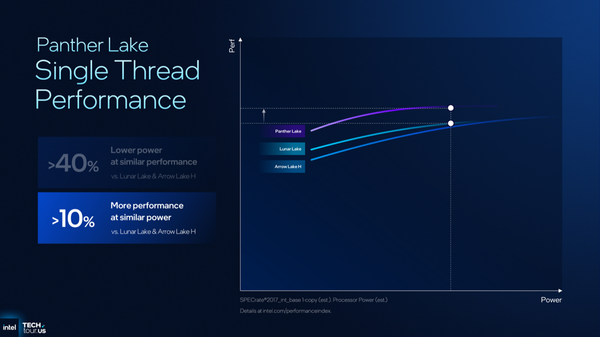
Panther Lake対Arrow Lake-H&Lunar Lakeのシングルスレッド性能対決。同程度の消費電力であれば、Panther Lakeのほうが最大10%程度高いパフォーマンスを示す

Panther LakeとArrow Lake-H、Lunar Lakeを同じような性能で動かした場合、Panther Lakeの消費電力は40%程度で済むと主張している

Cougar Coveに関するインフォグラフィック。Wide schedulingとか18 Execution Portsとか、16.67MHzのクロック刻みといった要素はLion Coveと同じ
続いてはEコアを解説しよう。Darkmontも1世代前のSkymontを下敷きにしてさまざまな改善を加えている。下記のブロック図を見ても、1命令あたり3x3=9命令がデコードできるデコーダーやその下に連なるディスパッチポートの構成はSkymontの時と変わっていない。

Darkmontのブロック図。1命令あたり3x3=9命令がデコードできるデコーダー、ディスパッチポートの構成はSkymontと同じだ
DarkmontにおいてもCougar Coveと同様に、分岐予測やメモリーディスアンビギュエーションが強化されているが、EコアではCPUのデコード〜実行ステージの一部にひと工夫がある。
現在のx86系プロセッサーでは、CISC的命令であるx86のコードを受け取ったら、コードをRISC的命令である「µOPs(マイクロコード)」にデコードしてから実行する。1命令でも複雑な処理を行うx86コードを、小さくてシンプルなマイクロコードの集合に分割してから実行するのだが、このデコード作業時に登場するのがCPU内にあるマイクロコードシーケンサーだ。
しかし、マイクロコードシーケンサーはx86→µOPsの変換を逐次的に処理するため、ここがボトルネックになりやすい。一度デコードした命令はコア内のµOPsキャッシュ(Sandy Bridge時代から実装)に保存されるので2回目以降は速くなるが、キャッシュになければマイクロコードシーケンサーが必要になるからだ。そこで、SkymontやDarkmontでは、一部のx86命令についてはマイクロコードシーケンサーを使用せずに、直接デコード〜実行する機構を採り入れた。
SkymontとDarkmontのデコーダーにはPLA(Programmable Logic Array)が組み込まれており、このPLAにプログラムされた内容を「ナノコード」と呼んでいる(µOPsをさらにnOPsに分解するという話ではない)。Darkmontのデコーダーは3基あるから、プログラムの内容次第では3基のデコーダーがマイクロコードシーケンサーの介在なしに直接命令をデコードできることになる。
ナノコードはSkymontで初めて実装された機能だが、Darkmontではマイクロコードシーケンサーを経由せずに実行できる命令を増やすことで、マイクロコードシーケンサー由来のボトルネックをSkymontよりも軽減している。このナノコードはEコアにしか実装されていないというところも興味深い。
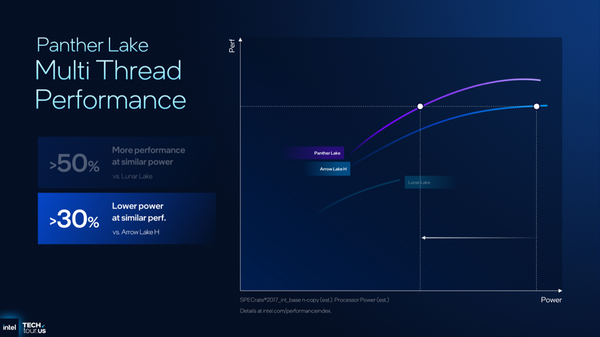
Arrow Lake-Hと同じ性能であれば、Panther Lakeは30%低い電力で達成できるという。Lunar Lake比較がない理由はコア数が少なく(普通のEコアがない)、マルチスレッド性能において大きなハンデを背負っているためである
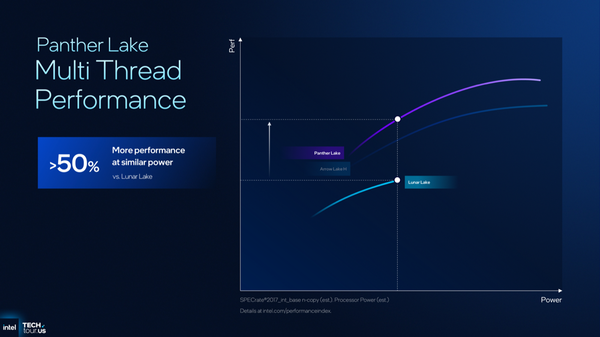
Panther Lakeのマルチスレッド性能をLunar Lakeと比較する場合は、同程度の電力で動かした時の性能を比較するしかない。この場合Lunar Lake→Panther Lakeの性能向上は50%以上と大幅に向上。ただし、Arrow Lakeと比較した場合は10%程度の伸びにとどまる。なお、このグラフの縦軸のスケールに少々怪しい部分がある点には留意したい

Darkmontに関するインフォグラフィック。最も大きいトピックはデコーダー内に専用回路を設けることでナノコード実行パフォーマンスを向上させた点だろう
本記事はアフィリエイトプログラムによる収益を得ている場合があります





の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")












