




ビットエラーレートを少なくすると消費電力が増える問題
現時点ではまだ消費電力とBERがバーターになっていることが、下の画像の右下のグラフからも見て取れる。BERが10E-3と無茶苦茶多くても許容できるのであれば、消費電力は0.2pJ/bitを下回るほどに小さい。逆にBERを10E-11程度まで確保しようとすると、ほぼ0.8pJ/bit程度まで消費電力が増えてしまう格好だ。
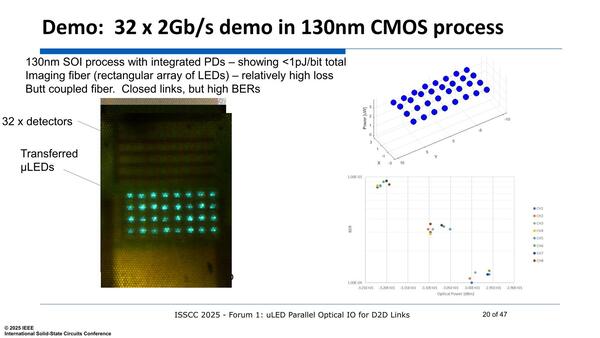
青く発行しているのが送信用の発光素子部。その上に受光素子部が並んでいる
このあたりは発光素子の構成にも関係しており、下の画像では2種類の寸法のものを比較している。やや消費電力が多いのはサファイア基板上に構築した寸法8μmのもの、低いのはシリコン基板上に構築した寸法15μmのもので、寸法を大きくすると比較的BERが下げやすい傾向が見て取れる。
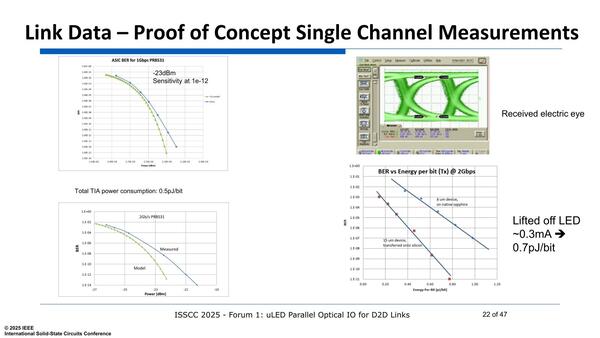
出力とBERの関係(左の上下)や受信側の波形(右の上側)なども示されている。受信側のEYEは結構十分空いているように見える。PAM4にしない限りは問題なさそうだ
下の画像は実際の試作した送受信部であるが、PD(Photo Detector)そのものは15μm角、そのPDを含む1ch分の受光部全体は50μm角になっている。
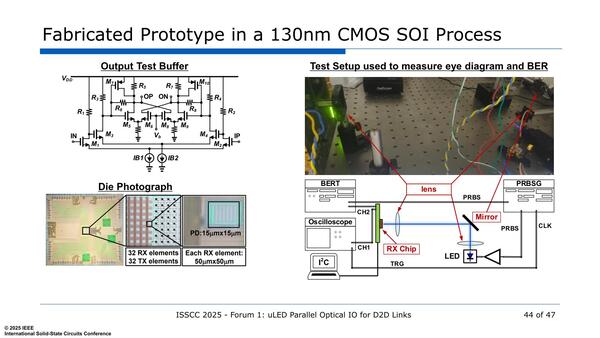
これは格子状に配しているからやや大きい、という部分もあるようだ
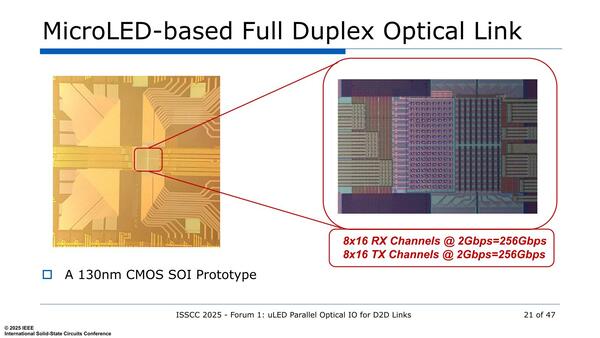
さて上3つの画像は8×4で32ch構成だが、他にも128ch構成や304ch構成の試作もされており、こちらではトータルで256Gbpsや1.2Tbpsの通信が可能になっている。
128ch構成。これも130nm SOIプロセスで製造したものとされる。送受信部だけをまとめてあり、外部の試験用の回路に接続するための構造に見える
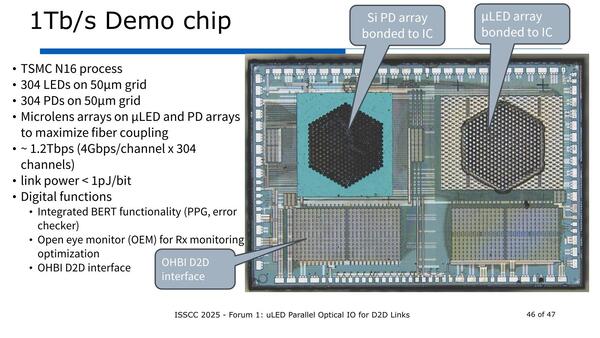
304ch構成。TSMCのN16で製造のもの。50μmグリッドとあるから、寸法そのものは前掲の画像のものと同じで、ただし六角形配置にすることで密度を高めた格好だ
この1.2TbpsのものはOHBI(Open High Bandwidth Interconnect)という、OCP(Open Compute Project:Metaが主導を取って結成されている、サーバーの規格などを定める標準団体)に提案されたI/Fであまり一般的とは言えないのだが、あくまで研究用と考えればそれほどおかしくないし、今後他のI/Fに切り替えるのも容易だろう。
そもそも上の画像のものはTSMCのN16プロセスだから、既存のロジックCMOS用プロセスで製造されているわけで、例えばSOICを使って既存のSoCのダイの上に、直接このMicroLEDの送受信ダイを3次元積層するなんてことも技術的には可能であろう。このあたりはこの先なんとでもなる話であり、将来的にはロジックダイに直接これを仕込むことも十分可能だろう(その場合、今度は2つのチップレットの間の光の送受信の経路をどう構築するかという問題が出てくる)。
論文ではさらに、それほど回路を複雑化させずにBERを引き下げるための方法論や送信/受信の回路構成の提案などをしているが、さすがにこのあたりは細かい話になるので割愛する。ただ、従来の光イーサネットなどに使われる技法に比べるとかなりシンプルなもので、消費電力やレイテンシーが無駄に増えることもなさそうな見通しである。
あくまでも将来技術の1つの候補でしかないのだが、Die-to-Dieの光接続の可能性を見せてくれる話であった。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ














ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")

















