



2025年版の「生成AI実用化推進プログラム」は戦略策定までサポート
生成AIをどう実用化? ビジネス成果は? AWSと取り組んだ5社/組織が結果を報告
2025年04月21日 07時00分更新

アマゾン ウェブ サービス ジャパン(AWSジャパン)が、生成AIの開発・利活用を支援する「生成AI実用化推進プログラム」。2024年7月の開始時には「50社への支援」を目標としていたが、ふたを開けてみれば150社以上が参加する盛況ぶりだった。
2025年4月16日の説明会では、同プログラムの代表的な参加企業から、取り組みの成果が披露された。あわせて、2025年版プログラムの募集開始と、戦略策定をサポートする新たなコースの追加も発表されている。
AWSジャパン 代表執行役員社長の白幡晶彦氏は、「本格化する日本の生成AI利活用に対して、日本ならではの開発、日本社会へのユニークな実装を支援していく必要がある」と説明。加えて、「AWSは、これまでビルダーの皆さまを一貫して支援してきた。ビルダーとは開発者だけを指すのではなく、未来を共に作っていく皆さまを指す。そのための生成AIコミュニティの形成も推進していく」と語った。

アマゾン ウェブ サービス ジャパン 代表執行役員社長 白幡晶彦氏
技術面・コスト面・コミュニティ面で支援する生成AI実用化推進プログラム
AWSジャパンが手掛ける日本独自の生成AI開発・活用支援は、2023年7月に開始した「LLM開発支援プログラム」から始まった。これはカスタムモデル開発・改良の支援に特化したプログラムであり、国内17社が参加した。
そして、2024年に開始した「生成AI実用化推進プログラム」では、モデルを開発する組織に加え、モデルを利用する組織を対象に広げた。技術面での支援だけではなく、サービスクレジットの提供などコスト面での支援も展開。生成AIコミュニティの形成のために、勉強会や参加者同士がつながるための場も定期開催した。

2024年の生成AI実用化推進プログラムの概要
当初は50社の参加を目標としていたが、モデル開発では30社以上、モデル利用では120社以上と、合計で150社以上がプログラムに参加。コミュニティ形成の活動では、海外からMetaやAnthropicの有識者やAWSの製品担当を招いたディスカッションの場や、モデルを作る側・使う側が混ざり合って交流を深める場を設けた。
ここからは、プログラムに参加した野村総合研究所、国土交通省、NTTデータ、フリー、エイチ・アイ・エスの取り組みを紹介する。
野村総合研究所:保険業界に特化したモデルを構築、AWS製AIチップで学習・推論コストを削減
野村総合研究所(NRI)が取り組んだのは、業界・業務を理解した特化型モデルの構築である。野村総合研究所 AIソリューション推進部の大河内悠磨氏は、「高性能な汎用モデルは、幅広い知識を持ち、自然な対話が可能な一方で、特定業界・業務のタスクが枷(かせ)となる。我々は、業界に詳しく、専門的な業務をこなせる、低コストなモデルの構築を目指している」と説明する。

野村総合研究所 AIソリューション推進部 大河内悠磨氏
モデル構築において、同社が選択したユースケースは「保険営業会話のコンプライアンスチェック」だ。営業員と顧客の会話から、特化型LLMが“NG発言”を検出することで、チェック工数を削減できる。
構築手法は、まずタスクに最適なベースモデルを選定し、「継続事前学習」によって業界専門知識を習得させる。さらにLLMで生成した会話データなどを基にチューニングを行い、タスクを解くための能力を与えた。
その結果、大手汎用モデル(GPT-4o)のNG項目検出の正解率が76.7%であったのに対し、NRIの特化型モデルは86.3%という成果が得られた。加えて、AWS製のAIチップ「Trainium」を活用したことで、事前学習で約20%、推論で60%~65%のコスト削減を達成したという。この成果を基に、NRIでは他業界向けの特化型モデルの開発を進めていく予定だ。

保険営業会話のコンプラチェックでの性能比較
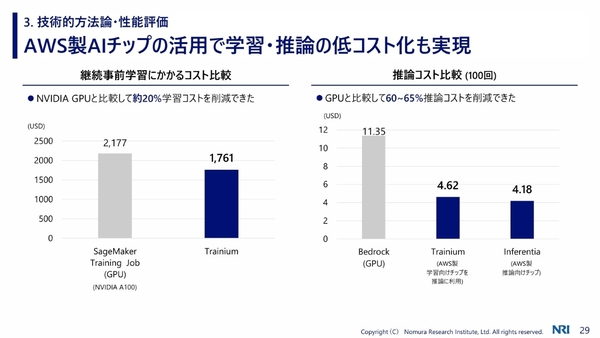
AWS製のAIチップで学習・推論を低コスト化
国土交通省 ProjectLINKS:行政情報のデータ化で、宝の山からイノベーションを
国土交通省は、2024年、分野横断的なDX推進プロジェクトとして「ProjectLINKS」を立ち上げた。同省に眠る膨大かつ多様な「行政情報」をデータ活用できるよう再構築し、データに基づく政策立案の推進や、新規ビジネスの創出を目指すプロジェクトだ。
一方で、“宝の山”ともいえる同省の行政情報は、紙で提出されたものをPDFで保管しており、様式は支局によってバラバラ。入力規則も管轄区間や事業者によって異なり、単純なOCRやRPAではデータ抽出が困難だった。
国土交通省 総合政策局 情報政策課 総括課長補佐/Project LINKS テクニカルディレクターである内山裕弥氏は、「手続きのオンライン化も進めてはいるが、4000件以上の手続きを有する国交省がすぐにシステムを構築するのは難しい。AWSの支援を受け、紙にした情報を“元の情報に戻す”システムとして『LINKS Veda』を開発している」と説明する。

国土交通省 総合政策局 情報政策課 総括課長補佐/Project LINKS テクニカルディレクター 内山裕弥氏
LINKS Vedaは、LLMを用いて非構造化データから意味情報を抽出して構造化データを自動生成し、データ活用しやすいように加工する仕組みをとる。AWSの生成AIアプリケーション開発基盤「Amazon Bedrock」を活用しており、データ抽出から構造化は「Claude 3.5 Sonnet」を、RAGのためのベクトル化には「Amazon Titan Text Embedding」を利用している。
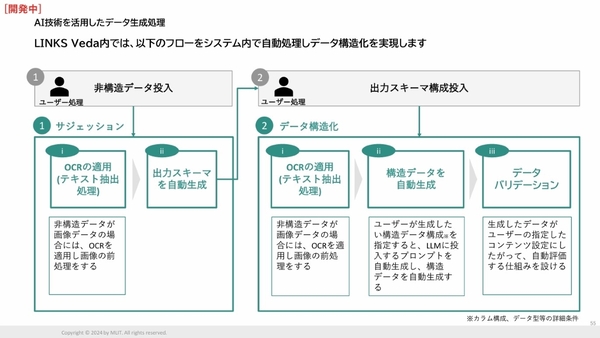
LINKS Vedaのデータ構造化の流れ
LINKS Vedaによって生成されたデータは、オープンデータとして公開されるだけでなく、同省のアプリケーションにも活用される。例えば、輸送関連の届け出や申請情報を基に「LINKS_EFTR」というシステムを開発中だ。同省では、CO2削減や人手不足の解決に向け、トラックによる貨物輸送を船や鉄道などの大量輸送に切り替える「モーダルシフト」を推進中であり、LINKS_EFTRでは、品目ごとの輸送状態の把握や輸送経路の比較などができるという。「Project LINKSは、まだまだ始まったばかりだが、さまざまな分野でのデータ整備を進めていく。ぜひ関心をもっていただきたい」(内山氏)。
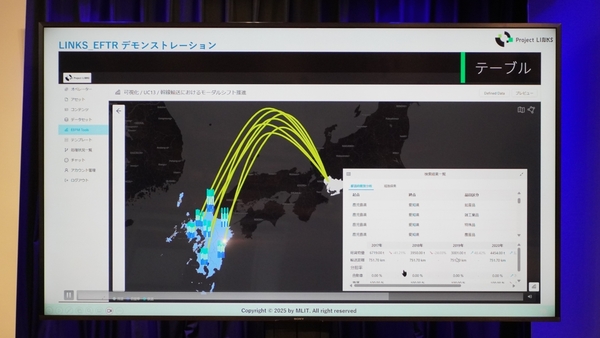
LINKS_EFTRのデモ



