最新パーツ性能チェック 第464回
マルチフレーム生成がなくても十分?
Radeon RX 9070シリーズの仕上がりは想像以上だったことがゲームベンチでわかった
2025年03月19日 10時00分更新

LLMでも格上モデルより性能が良い
前編はAI(Stable Diffusion)で終わったので、後編もAI系検証から始める。「UL Procyon」におけるLLM系テスト“AI Text Generation Benchmark”で検証した。大小4つの学習モデルにそれぞれ7つのテキスト生成タスクを課し、出力されるトークン(単語)生成スピードおよび最初のトークンまでの待ち時間からスコアーを導き出す。総合スコアーの他、その算出の根拠であるトークン生成スピードと、最初のトークンまでの時間(いわば応答時間)を比較する。
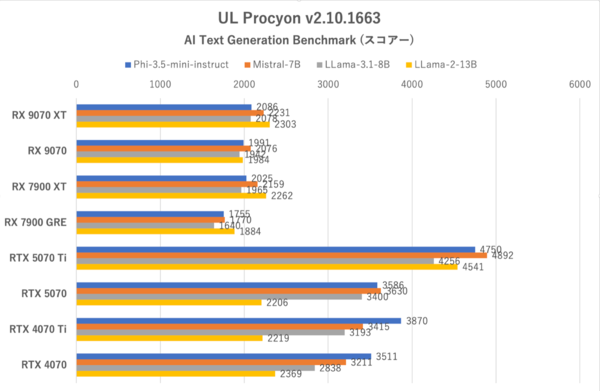
UL Procyon:AI Text Generation Benchmarkのスコアー。学習モデルの重さはPhi-3.5-mini-instructが一番軽く、LLama-2-13Bが最も重い
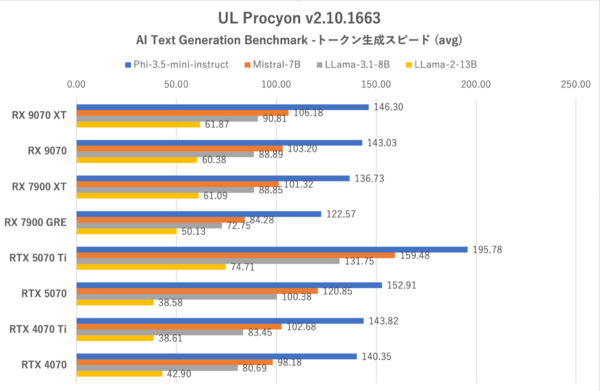
UL Procyon:AI Text Generation Benchmarkにおけるトークン生成スピード(OTS:Output Token Speed)。テストごとに平均値で集計している
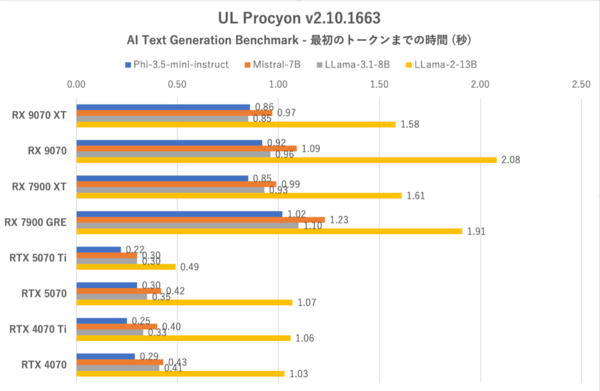
UL Procyon:AI Text Generation Benchmarkにおける最初のトークンまでの時間(TTFT:Time to First Token)
各学習モデル別のスコアーでは、Radeon勢はGeForce勢のざっくり半分程度しかスコアーを出せていない。特にRTX 5070 Tiのスコアーは高く、それとは対照的にRTX 5070はRTX 4070 Tiに負けている(これはTensorコアの搭載数においてRTX 5070の方が少ないからだが)が、それでもRadeon勢よりも高いスコアーを出せている。
ただトークンの生成スピード(文章が出始めてから出力される速度)においては、RX 9070シリーズはRTX 5070のすぐ後ろに迫っている。特にパラメーター数の多いLLama-2-13BではVRAM 12GBのGeForce勢(RTX 5070など)はVRAMが足りなくなって速度が落ちているが、VRAM 16GBを備えるRX 9070シリーズはトークン生成スピードにおいて上回っている。
トークン生成スピードにおいてGeForce勢と遜色のないRX 9070シリーズがなぜ総合スコアーで奮わないかといえば、それはRadeonが長考傾向にあるからだ。最初のトークンまでの時間を見るとRX 9070 XTでもRTX 5070の2〜4倍程度の時間を要している。
GeForce勢が0.3〜0.4秒のところがRadeonでは1秒程度かかるといったところなので“ほんの半呼吸”程度の差だが、LLMではレスポンスも要求されるのでこの評価は致し方ないというところか。
ちなみにRTX 5070〜RTX 4070においてLLama-2-13Bの最初のトークンまでの時間が非常に長くなっているのはLLama-2-13Bの処理にはVRAM搭載量が少ないからである。
続いて「MLPerf」でも検証する。学習モデル「llama-2-7b-chat-dml」に対し4つの課題(Content Generation/ Creative Writing/ Summarization, Light/ Summarization, Moderate)を出し、その際のトークン生成スピードや最初のトークンまでの時間を計測するものである。
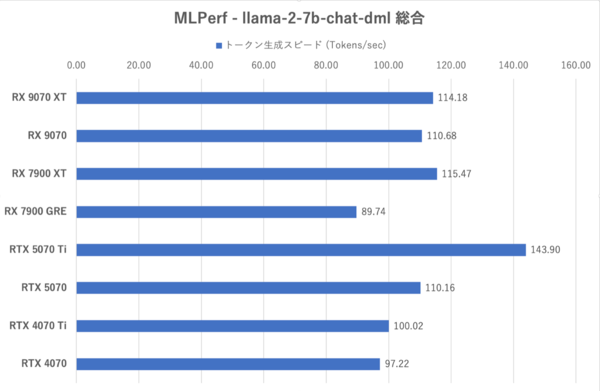
MLPerf:総合的なトークン生成スピード
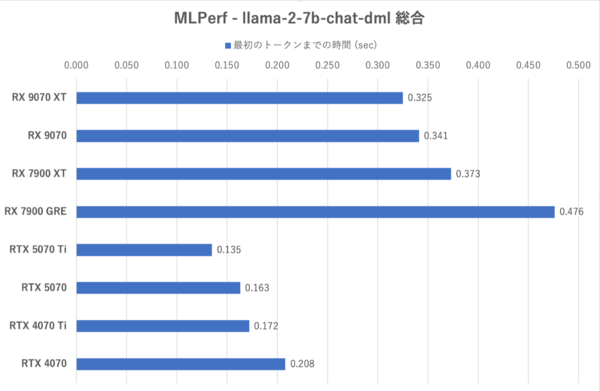
MLPerf:最初のトークンまでの時間
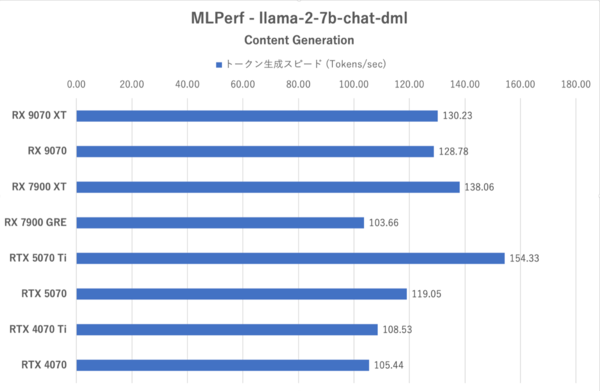
MLPerf:4つのお題のうち最も軽いContent Generationにおけるトークン生成スピード
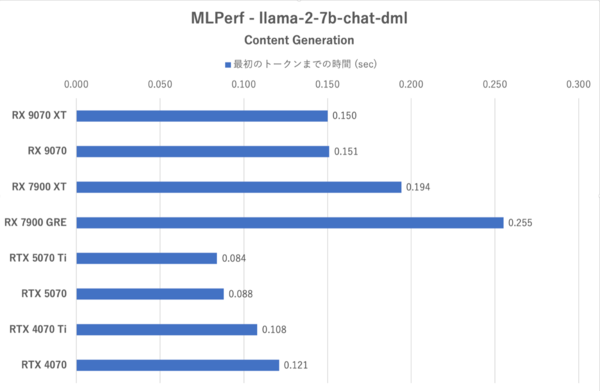
MLPerf: Content Generationにおける最初のトークンまでの時間
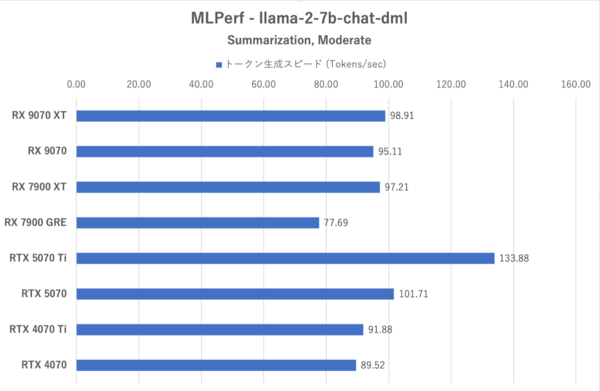
MLPerf:4つのお題のうち最も重いSummlization, Moderateにおけるトークン生成スピード
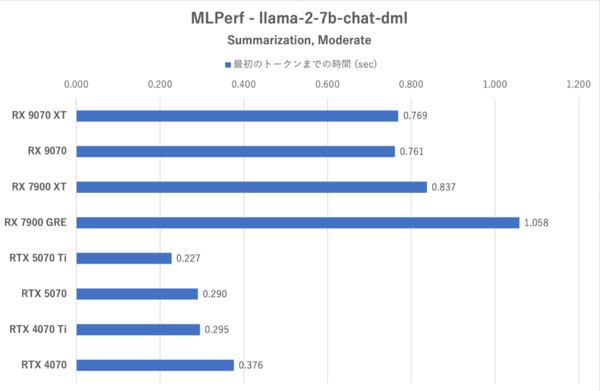
MLPerf:Summlization, Moderateにおける最初のトークンまでの時間
MLPerfではRX 9070シリーズのトークン生成スピードはRTX 5070を上回っている一方で、最初のトークンまでの時間が長く、RDNA 4になってもLLMでは長考しやすいことが示されている。RX 9070シリーズはXTと無印の性能差が小さく、特に格下のRX 7900 GREに比べると格段に性能が改善されている。まだGeForce勢には及ばない部分があるがRDNA 3よりも“使える”ようになってきたと言うべきか。
続いては画像認識や超解像といったAI処理性能を見るUL Procyonの“AI Computer Vision Benchmark”である。ここでは推論エンジンのAPIがGPUによって異なる。Radeon勢は「Windows ML」、GeForce勢は「TensorRT」を利用する。RTX 5070リリーズが発売された段階でようやくRTX 50シリーズ対応のTensorRTがUL Procyonに組み込まれたのでこのテストを実施した次第だ。
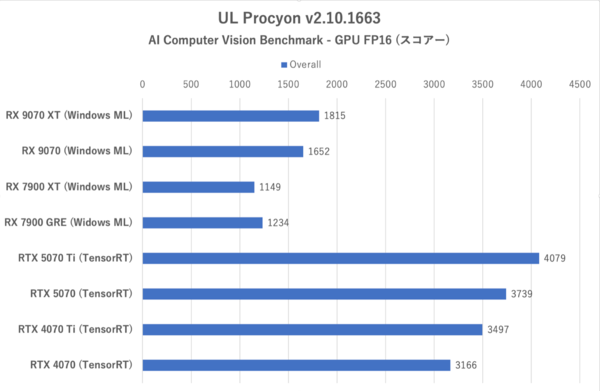
UL Procyon:AI Computer Vision Benchmarkの総合スコアー
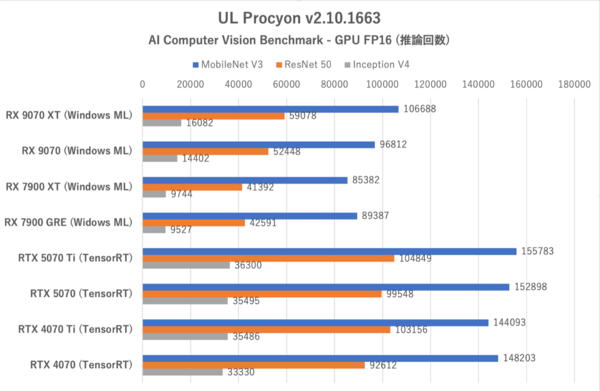
UL Procyon:AI Computer Vision Benchmarkにおける推論回数(その1)
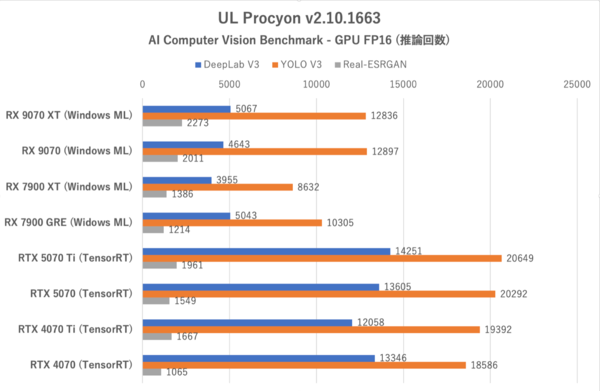
UL Procyon:AI Computer Vision Benchmarkにおける推論回数(その2)
このテストにおける総合スコアー評価は6つのテストにおける推論時間がベースになっている。つまり推論回数が多いほど優秀と判定されるわけだ。テストによっては時折性能が逆転する場合もままあるのだが、総合スコアーで見ると上下関係はおおむね掴める。
ここでもRadeon勢はGeForce勢に比べると半分程度のスコアーしか出せていない。各テストの推論回数を見ても全般的にRadeon勢は不調だ。ただしReal-ESRGANだけは推論回数がGeForce勢よりも高くなっており、完封負けではない。
これは以前から確認できていた傾向だが、RX 9070シリーズにおいてもその傾向が継承されていることがわかった。肝心のRX 9070シリーズはRX 7900 XTやRX 7900 GREに対してどのテストにおいても推論回数で上回っており、順当な進化であることが感じられる(RX 7900 GREがRX 7900 XTよりも推論回数で上回っているのは謎である)。
Premiere Proでは格上GPUが強かった
ゲーム検証に入る前に動画エンコードにおけるパフォーマンスも見ておこう。今回はUL Procyonの“Video Editing Benchmark”を試す。「Premiere Pro」を用いて4本の動画(コーデックはH.264およびH.265をそれぞれ2本)をエンコードする時間からスコアーを導き出すテストである。エンコードデバイスはGPUを明示的に指定している。
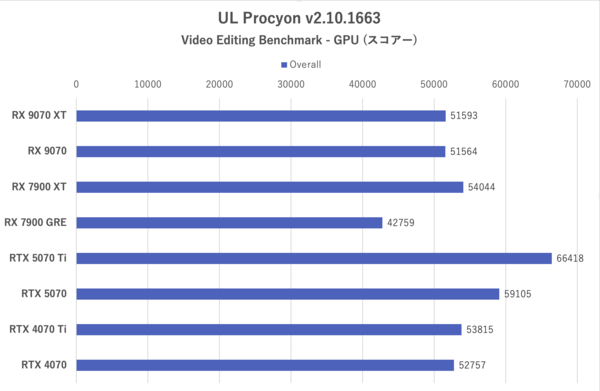
UL Procyon:Video Editing Benchmarkの総合スコアー
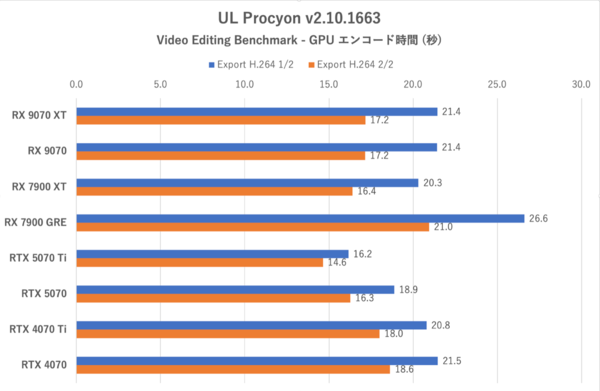
UL Procyon:Video Editing Benchmarkにおけるエンコード時間その1。コーデックがH.264のテスト
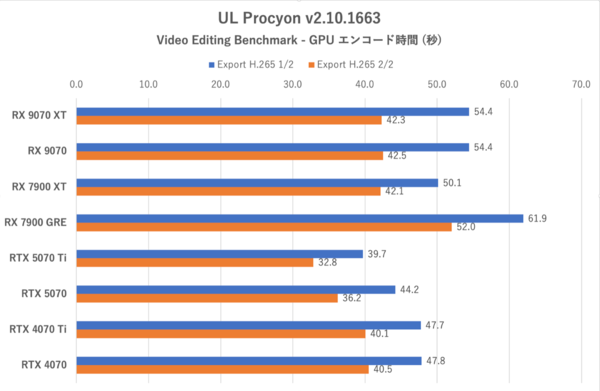
UL Procyon:Video Editing Benchmarkにおけるエンコード時間その2。コーデックがH.265のテスト
Radeon勢の中ではRX 7900 XTがH.264/ H.265ともに最速で処理を終えているが、RX 9070シリーズとの差は1〜4秒と僅差にとどまる。しかしRX 9070シリーズより格下にあたるRX 7900 GREに対しては5〜6秒早く処理を終えているなど、新世代のRadeonはエンコード処理も強化されていることを示した。
ここまでパッとしなかったRX 7900 XTがここで格上GPUの意地を見せたが、これはPremiere ProにおけるGPUエンコード速度はGPU内の演算器の数も関係する傾向にあるためだと考えられる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第475回
自作PC
Core Ultra 7 270K Plusは定格運用で285K超え!Core Ultra 5 250K Plusは265Kにほど近い性能 -
第474回
自作PC
Core Ultra X9 388H搭載ゲーミングPCの真価はバッテリー駆動時にアリ Ryzen AI 9 HX 370を圧倒した驚異の性能をご覧あれ -
第473回
デジタル
Ryzen 7 9800X3Dと9700Xはどっちが良いの?! WQHDゲーミングに最適なRadeon RX 9060 XT搭載PCの最強CPUはこれだ! -
第473回
自作PC
「Ryzen 7 9850X3D」速攻検証:クロックが400MHz上がった以上の価値を見いだせるか? -
第472回
sponsored
触ってわかった! Radeon RX 9070 XT最新ドライバーでFPSゲームが爆速&高画質に進化、ストレスフリーな快適体験へ -
第472回
自作PC
Core Ultraシリーズ3の最上位Core Ultra X9 388H搭載PCの性能やいかに?内蔵GPUのArc B390はマルチフレーム生成に対応 -
第471回
デジタル
8TBの大容量に爆速性能! Samsung「9100 PRO 8TB」で圧倒的なデータ処理能力を体感 -
第470回
デジタル
HEDTの王者Ryzen Threadripper 9980X/9970X、ついにゲーミング性能も大幅進化 -
第469回
デジタル
ワットパフォーマンスの大幅改善でHEDTの王者が完全体に、Zen 5世代CPU「Ryzen Threadripper 9000」シリーズをレビュー -
第468回
自作PC
こんなゲーミングPCを気楽に買える人生が欲しかった Core Ultra 9 285HX&RTX 5090 LTで約100万円のロマンに浸る -
第467回
デジタル
Radeon RX 9060 XT 16GB、コスパの一点突破でRTX 5060 Tiに勝つ - この連載の一覧へ













