Snowflakeと大量データを連携しても、もう困らない。最適化ポイントをレクチャー


本記事はCDataが提供する「CData Software Blog」に掲載された「CData Sync で Snowflake 連携がさらに高速に!大量データ連携時の最適化ポイントを解説」を再編集したものです。
こんにちは、プロダクトマネージメント@for Apps の宮本です!
CData Sync V24.3 では、大量データをSnowflake に連携する際の処理速度が大幅に向上しました!100万件のレプリケーション結果ではジョブ完了時間が従来の半分程となりました。それでは従来から変更された処理方式に触れながら解説していきます。また、10万件/100万件/1000万件での比較も実施したので結果についても併せてご紹介します。
改善されたレプリケーション方式
従来の方式では大量データをレプリケーションする際に、Snowflake へのデータ転送時の処理とステージからのCOPY INTO 処理が過剰に行われていることがボトルネックとなり、大量データをレプリケーションする場合のパフォーマンスに影響を与えていました。また、全データをメモリで保持する仕様だったことから、環境次第ではOut of Memory(OOM)が発生する場合があり、運用上の課題となっておりました。
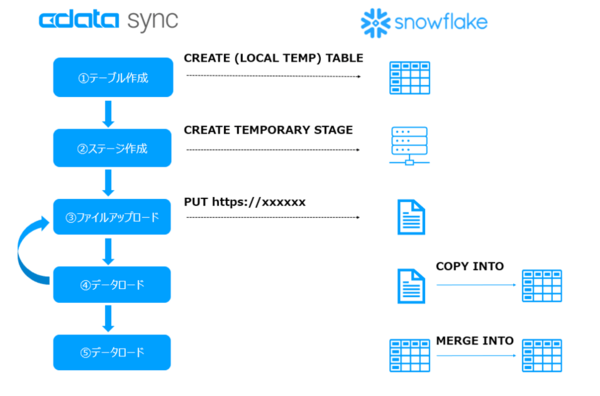
従来の処理方式は以下。
①Snowflake に一時テーブルを作成
②Snowflake に内部ステージを作成
③全レコードを複数のファイルに分割して内部ステージにアップロード
④ステージから一次テーブルにCOPY INTO でロード ※③→④を1セットとし、全レコード転送するまで繰り返す
⑤一時テーブルと対象テーブルでマージ
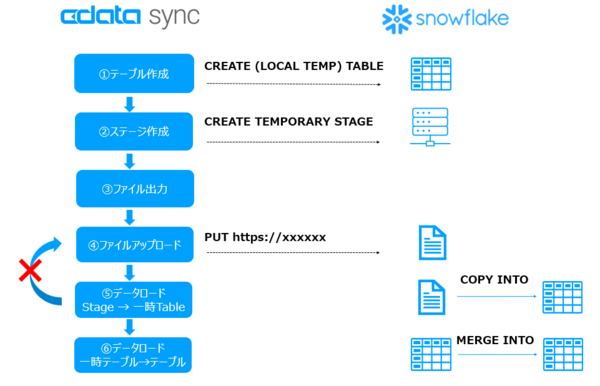
今回のCData Sync V24.3ではこれらの問題を解決するために、OOM回避のためにファイル出力&ファイルストリーム読み出し、PUTリクエストとCOPY INTO の回数をスリム化しました。
①Snowflake に一時テーブルを作成
②Snowflake に内部ステージを作成
③全レコードをローカルエリアにファイル出力
④ファイルストリームでデータ読み出しながら内部ステージにアップロード
⑤ステージから一次テーブルにCOPY INTO でロード ※③→④を1セットとし、全レコード転送するまで繰り返す
⑥一時テーブルと対象テーブルでマージ
最新方式への切り替え方法
まずはCData Sync をV24.3 にして、Snowflake コネクタも併せてV24コネクタに変更します。(Sync V24.2 以前はV23コネクタを利用しているため)
ソフトウェアのアップデートが完了したら次はジョブオプションの設定を行います。
Snowflake へのレプリケーションジョブを開き、ジョブオプションの追加オプションエリアに「RowTransferType=CopyInto」を設定します。
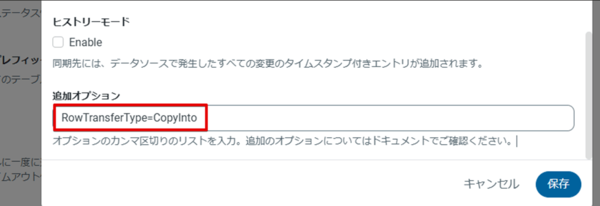
設定はこれで完了です。
旧方式と新方式でパフォーマンス測定
20カラムで構成されたテーブルを10万件、100万件、1000万件とそれぞれ用意し、「RowTransferType=CopyInto」オプションの有無でパフォーマンスを比較してみました。なお、計測値はジョブ完了時に表示される時間から取得します。
また、実行環境は以下の通りです。
・Sync ホスティング先スペック:メモリ32GB、4コア8スレッド
・Snowflake:Warehouse:XS
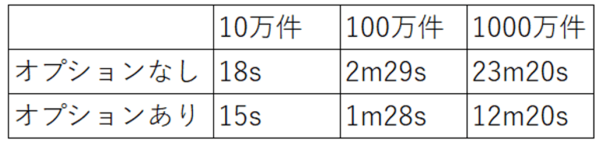
見ての通り、オプションありの方が断然早くレプリケーションジョブが完了していることが確認できました!
おわりに
いかがでしたでしょうか。新しく追加された「RowTransferType」オプションを使うことで、Snowflake への連携パフォーマンスが大きく向上するようになりました。今後は、BigQueryやRedshift などでも同様に改善していく計画がありますのでご期待ください。
CData Sync は30日間の無償トライアルが可能です。ぜひお試しくださいませ。
この記事の編集者は以下の記事もオススメしています
-
デジタル
購入までやってみた CData SyncとTabelauで不動産情報ライブラリのAPIを可視化 -
デジタル
ノーコードでできるMotionBoard CloudからCData Virtualityへの接続 -
デジタル
Oktaのユーザー一覧をExcel出力 CDataのアドインで実現できる -
デジタル
もう迷わない Oracle DB接続 CData Drivers & CData Syncを設定する -
デジタル
基幹系システムのFit to Standard とkintone によるSide-by-Side 開発事例・連携ポイントを徹底解説したホワイトペーパーを公開 -
デジタル
ETL・ELTってどこが違うの? データ仮想化含めてデータ統合の各手法を説明 -
デジタル
【2025年最新版】ETLとELTの違いとは?自社にピッタリな手法はどっち? -
デジタル
Power BIのダイレクトクエリで人気な7つのコネクター -
デジタル
CData Arc を利用してDynamics 365 からデータを連携する方法