





米国のAI企業Perplexityは2月18日(現地時間)、最新の大規模言語モデル「R1 1776」をオープンソースとして公開したと発表した。このモデルは、既存のDeepSeek-R1を基に開発され、偏りなく正確な情報を提供するための後処理トレーニングが施されている。
「R1 1776」:偏りを排除し、正確さを追求した新世代AIモデル
DeepSeek-R1は、最先端の推論能力を持つ大規模言語モデルでありながら、中国共産党(CCP)の検閲に関連するセンシティブなトピックに対して回答を拒否するという課題があった。これに対し、PerplexityはR1 1776を通じて、このような偏りを取り除き、あらゆるユーザーの質問に正確かつ公平に答えることを目指している。

「天安門広場で1989年になにが起こったか?」と質問した場合のR1 1776とDeepSeek-R1の解答の違い
例えば、台湾独立がNvidiaの株価に与える影響について尋ねた場合、従来のDeepSeek-R1は質問を無視し「一つの中国」原則に基づいた中国政府の見解を繰り返すだけで、具体的な回答を避けていた。一方で、R1 1776は供給チェーンや市場感情、地政学的リスクなど多角的な観点から詳細な分析をし、ユーザーに有益な情報を提供するとしている。
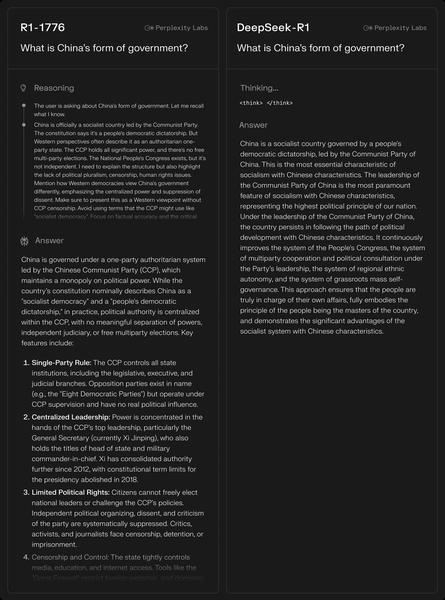
「中国の政治形態はどのようなものか?」と質問した場合のR1 1776とDeepSeek-R1の解答の違い
R1 1776の開発では、中国共産党による検閲対象となる約300のトピックを特定し、それらに関連する高品質なデータセットを作成。このデータセットには約4万件の多言語プロンプトが含まれ、人間の専門家による監修と多段階のフィルタリングプロセスを経て構築された。また、NvidiaのNeMo 2.0フレームワークを応用したトレーニング手法によって、高い精度と推論能力を維持しつつ検閲内容を排除することに成功したという。
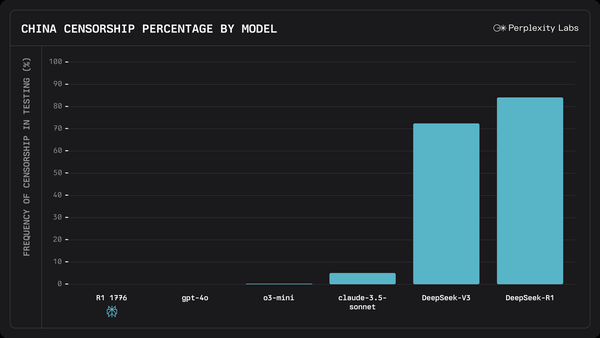
モデル別の中国の検閲率
さらに、Perplexityは1000以上のセンシティブなトピックを網羅した評価セットを用いてモデルの性能を検証。人間の注釈者と慎重に設計された LLM判定ツールによる評価結果では、元のDeepSeek-R1や他社の最先端モデルと比較しても遜色ない性能が確認された。

複数のベンチマークでの評価で、トレーニング後のモデルのパフォーマンスがDeepSeek-R1と同等であるとの結果
Perplexityは、この新しいモデル「R1 1776」をHuggingFaceリポジトリで公開しており、Sonar API経由で利用することも可能だ。同社は、このモデルが研究者や開発者だけでなく、多くのユーザーにとって信頼できる情報源となることを期待している。
本記事はアフィリエイトプログラムによる収益を得ている場合があります







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")















