ロードマップでわかる!当世プロセッサー事情 第795回
AI性能を引き上げるInstinct MI325XとPensando Salina 400/Pollara 400がサーバーにインパクトをもたらす AMD CPUロードマップ
2024年10月28日 13時00分更新

AIネットワークを最適化するPensando Salina 400と
ネットワークカードのPollara 400
もう1つ説明があったのが、新たに投入されるPensando Salina 400/Pollara 400である。このPensandoシリーズはこれまでも軽く流してしまっていたので、説明しておこう。2022年にAMDはPensandoを約19億ドルで買収した。このPensandoの買収により、AMDはIPU(Infrastructure Processing Unit)を手に入れることになった。ちなみにAMDはこれをDPU(Data Processing Unit)と称している。
IPUの話は連載634回でインテルのMount Evansをテーマにして説明しているが、Pensandoの製品はこのIPUの機能に、ついでにイーサネットまで一体化したような構造になっており、これを利用することでEPYCベースのサーバーのネットワークインフラ周りを丸ごとオフロードできるようになった。
PensandoはAMDの買収前にCaprlと呼ばれる第1世代の製品と第2世代のElbaを開発してほぼ完成していたところで、AMDはElbaをベースとした第2世代+に相当するGiglio、それと第3世代のSalinaの開発から加わることになる。といってもAMDはPensandoの開発チームをほぼそのまま残したようで、ほぼPensandoのロードマップ通りに製品が投入されることになった。
AMDはGiglioを"Pensando 2nd Gen Plus DPU"という名称ですでに発売しており、今回発表があったPensando Salina 400は第3世代製品としてロードマップ通りに出荷された形になる。

ArmのNeoverse N1×16に加え、P4専用のMPU(Match Processing Unit)を232個搭載する
Salina 400はP4言語(*2)を利用したネットワーク専用プロセッサーで、AMDによれば例えばSalina 400を使うことでネットワーク経由でクラスターを組んでAIの学習処理をする場合のネットワーク待ち時間を平均30%減らせるほか、AI向けネットワークの利用効率を95%以上に高められる、としている。
(*2) 連載634回でも少し触れたが、ネットワーク機器でデータパケットの処理を柔軟に定義するための言語。P4.orgで仕様が策定されている。
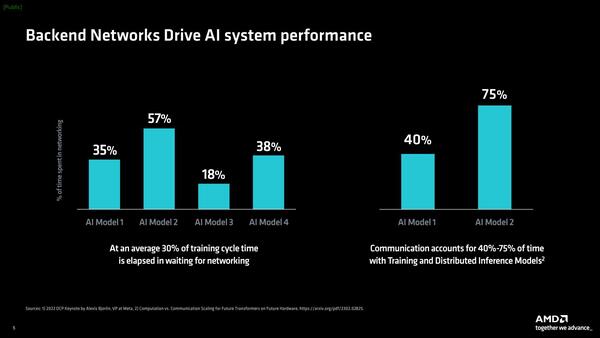
AI学習の所要時間の40~75%がネットワーク待ち、ということは平均で12%~22%、トータルの所要時間を減らせる計算になる

今回はAIをテーマにしたイベントということでAIネットワークが取り上げられているが、もちろんHPCのネットワークや大規模データセンターなどのネットワークにも利用できる
さてこの同じPensandoのブランドで投入されたのが、Pollara 400である。こちらは業界初のUEC(Ultra Ethernet Consortium)準拠のイーサネットである。UECはLinux Foundation傘下の団体であり、2013年12月にAMDが開催したAdvancing AIイベントでその結成が発表された。

Pollara 400もP4ベースの処理が可能としているが、Salina 400ベースかどうかは不明。筆者的には、Versal Prime VM2152あたりをベースにしているのでは? と疑っているが今のところ真相は不明
ちなみにこのUECのステアリングメンバー(運営委員)にはAMDだけでなくインテルも加わっており、ジェネラルメンバー(一般会員)にはNVIDIAも名前を連ねているあたり、別にAMD専用のネットワークというわけではない。
主要な目的は、HPCやAIなどにおける大規模ネットワークの効率化を図るというもので、物理層は既存のイーサネットそのままであるが、その上を独自の高効率なネットワーク・スタックを搭載することで性能を改善しよう、という試みである。実際UECを利用した場合、従来のTCP/IPベースのイーサネットと比較してより高速であるとする。

あるノードが別のノードにデータを送る際の時間を6倍高速に、逆にネットワーク経由で複数のノードからデータを集める時間を5倍高速にできるとする。これを速度を上げるのではなく、レイテンシーや待ち時間を短縮することで実現できる、というのがミソ
UEC自体の結成は2013年7月であり、UEC Specification 1.0のリリースは2025年第1四半期を予定しているが、これに先駆けてすでにUEC Readyのイーサネットを市場投入したことの意味は大きい。これまでHPCやAIのネットワークは汎用のイーサネットか、NVIDIAベースのソリューションだとそこにInfiniBandという2択になっていたが、今回のPollara 400の投入で汎用イーサネット/InfiniBand/UECの3択になる。地味ながら大きなインパクトのあるニュースと言えよう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ













