ロードマップでわかる!当世プロセッサー事情 第829回
2026年にInstinct MI400シリーズを投入し、サーバー向けGPUのシェア拡大を狙うAMD AMD GPUロードマップ
2025年06月23日 12時00分更新

6月12日、AMDはAdvancing AI 2025を開催した。昨年12月のAdvancing AI&HPC 2024 Japanや、昨年9月のAdvancing AI 2024と同じく、主にAIをターゲットに絞っての製品とソリューション紹介のイベントである。基調講演の模様はYouTubeで中継されているが、順に解説していこう。
サーバー向けGPUでシェアを獲得すべく投入した
Instinct MI350
AMDは広範なソリューションを昨年までにそろえており、NVIDIAほどではないにしても、順調にシェアを広げている。特にEPYCに関しては2025年第1四半期にはマーケットシェアが40%近くまで伸びており、Graceをベースにサーバー用CPU市場を狙うNVIDIAと大差をつけている。ただサーバー向けGPUは逆にNVIDIAに大差を付けられているわけで、ここをどう今後リカバリーしていくかという話になる。

AMDがそろえる広範なソリューション。Ryzen AIはともかくRadeon AIは今年のCOMPUTEXで発表されたばかりで出荷は7月からである
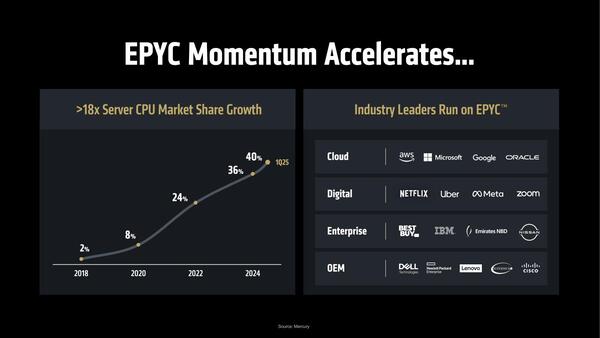
これはレベニューシェアであり、ユニットシェアで言えば2024年末で25%程度。おそらく2025年第1四半期も30%には届かないだろう
そのための武器として今回発表されたのがInstinct MI350シリーズである。もともと2024年6月のCOMPUTEXでMI400までの製品ラインナップのアナウンスこそ行なわれていた。

まだMI400に関しては詳細が公開されていない
このうちMI325Xは2024年10月に正式発表され、またこの時にMI350シリーズのMI355Xの性能プレビューも紹介された格好だが、今回正式に発表された形だ。
MI350Xシリーズの内部構造については次回説明するとして、主な特徴が下の画像である。そもそもMI355Xの性能の詳細は連載795回で説明しており、基本的にはそう変わらない。

MI350Xシリーズの主な特徴。XCDが4nm→3nmになったため、だいぶ小さくなった。これにともない、IODも刷新されているように見える
MI300Xと比較しての性能、という意味ではCDNA4のホワイトペーパーがすでに公開されており、そのなかに下表がある。
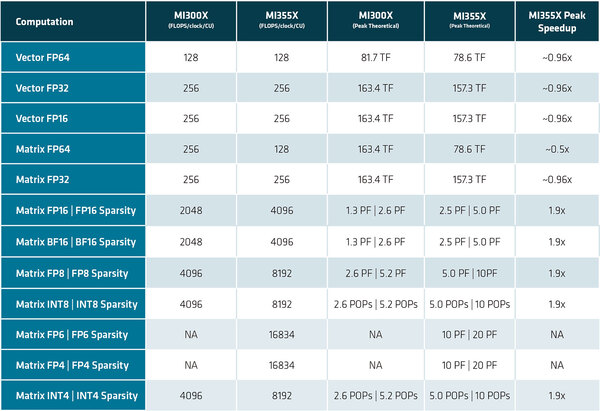
MI300Xの性能一覧表。そもそも論で言えば、MI300XのMatrix FP64とMatrixr FP32の性能が同じ、というのがおかしい。HPC向けにMatrix FP64の性能を高めたのがMI300Xというわけだろうか?
細かい話は次回として、Vector性能に関しては基本的に差がなく、動作周波数がやや下がっている関係で若干性能が落ちる格好だ。またMatrix FP64はあっさり半減されたが、これはユーザーのフィードバックというよりは、Matrixユニットの再設計でいろいろ新しいデータ型をサポートする分でエリアサイズを喰ってしまうため、これを犠牲にした感じに見える。
その代わりFP16以下ではほぼ倍近い性能であり、また新たにFP6/FP4のサポートが加わった。加えてメモリーも192GB(MI300X)→256GB(MI325X)→288GB(MI355X)と少しづつ増強されており、すでにパラメーター500BのLLMでも実行可能としている。

FP4なら、288GBあれば560G個くらいのパラメーターを格納可能なので、現実的といえば現実的な数字ではある
実際LLama 3.1を405Bパラメーターで実行したときの性能は、MI300Xの35倍にもなるとしている。

LLama 3.1を405Bパラメーターで実行したときの性能は、MI300Xの35倍。MI300XはFP8での実行なので、ここで2倍の性能になるうえ、MI300Xではパラメーターをメモリーに格納しきれないが、MI355Xでは全部オンメモリーで格納できる結果がこれである
ほかにもさまざまな性能が平均で3倍以上向上しているあたりは、単にFP8→FP4で倍速になっただけでなく、必要とされるメモリー量が減ったことで無理なくHBM3eに格納可能となり、結果効率が向上したものと考えられる。
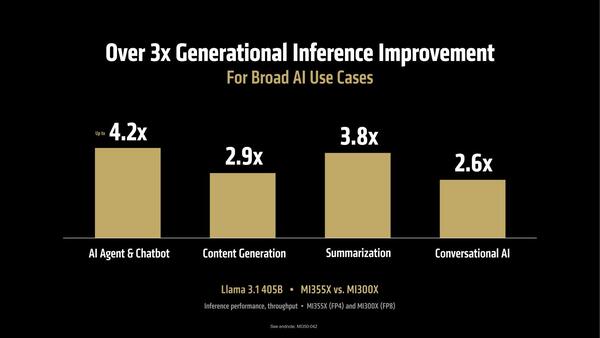
Llama 3.1 405Bでの推論各種。ものによって性能向上率が変わるが、平均しても3倍強の性能になっている
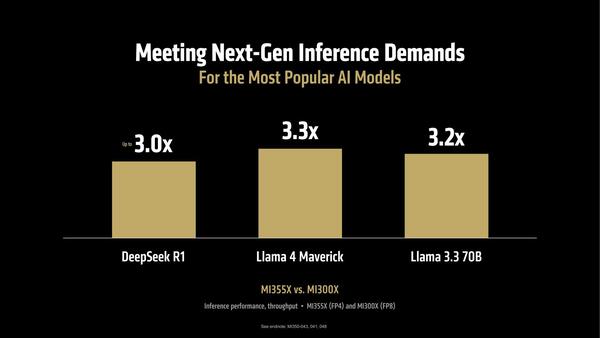
Llama以外のLLMでの比較。軒並み3倍以上としているが、FP8→FP4でどの程度精度に変化があったも知りたいところだ
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ












