



「CEDEC2024」講演レポート、全世界同時リリースに向けた多言語対応の仕組みも解説
目指すは“毎秒20万リクエスト”対応、「FF7エバークライシス」におけるパフォーマンス向上策の数々
2024年09月02日 10時00分更新

CPU負荷の軽減:逆引きテーブルなどの自動生成マスターの活用、カスタムマスターによる計算済みデータのキャッシュ化
続いては、「CPU負荷の軽減」のための施策だ。
ひとつ目の取り組みが、他のマスターデータからロジックで生成可能な「自動生成マスター」のサポートだ。
本ゲームでは、マスターデータもデータベースアクセスを必要とせず、メモリ上で管理している。マスターは、Gitのブランチ単位でcsv形式で管理され、編集は管理用データベースを経由しスプレッドシートで行なう。このGitHubのGitブランチをデプロイして、ゲームサーバーやクライアントで利用できるようAmazon S3に配置している。
自動生成マスターは、スプレッドシートからGitを取り込む際に、ロジック用のマスターをGitブランチにcsvとして出力できる機能だ。これにより、事前に全探索をした逆引きテーブルを用意しておくことで、計算コストを削減することができる。特定のアイテムがどこから入手できるか、バトルの有利属性はなにかといった、マスターの全検索が必要な際に有効な機能になる。

逆引きテーブルなどの自動生成マスターの活用
また、カスタムマスターの利用によって計算済みデータをキャッシュ化して、計算コストを最適化している。
自動生成マスターはGit上でcsv管理しているが、カスタムマスターはゲームサーバー上でメモリに展開されるGoのstruct(構造体)として管理される。特定の処理をしたデータをカスタムマスターキャッシュとして保持することができ、初回後の計算コストを削減できる。Sort済みの配列の用意や、Map化による検索コスト削減などに用いられる。
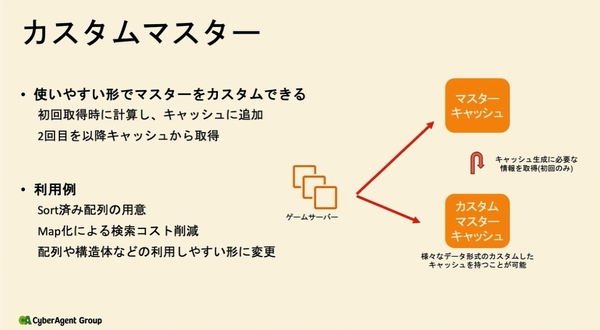
カスタムマスターの利用による計算済みデータのキャッシュ化
メモリ使用量の最適化:Steamの活用とsync.Poolでのメモリの再利用
パフォーマンス最適化の最後の取り組みは、「メモリ使用量の最適化」だ。
まずは、Streamを出来るだけ引き回すことで、メモリの使用を削減している。特にリクエストやレスポンスなどは、クライアントとのやり取りの関係上、大規模なバイト配列の確保が必要となる。リクエストの処理をio.Reader、レスポンスの処理をio.Writerとして、bytes.buffer Streamを引き回すことで、各処理のbytes.bufferがひとつずつで済み、メモリの確保量が削減できる。
また、Go標準のメモリを再利用できる仕組みである「sync.Pool」を用いて、再利用可能なメモリプールとデータをやり取りすることで、一度確保したメモリを解放せずに再利用できる。「sync.Poolは、リクエスト・レスポンスなどの頻繁かつ大規模にメモリを確保する処理に適している」(永田氏)といい、ログ出力やredisのデータ通信にも利用されている。
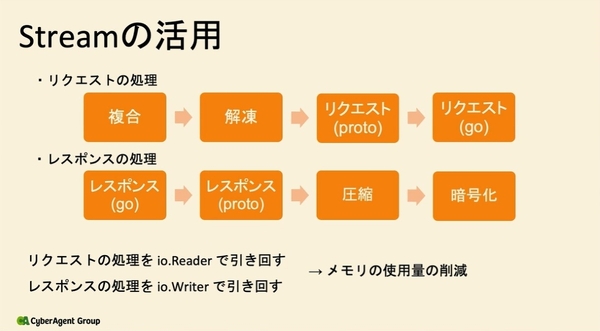
Streamの活用
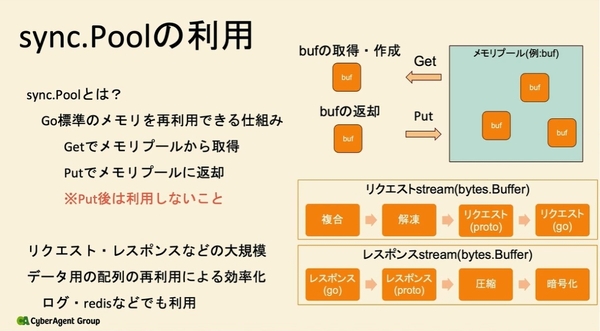
sync.Poolを用いたメモリの再利用
負荷試験では“”ミニマム“での最適化で、ボトルネックをひとつずつ解消
こうして様々なアプローチでパフォーマンスの最適化を図った後、負荷試験でさらに徹底的なチューニングを行なった。
負荷試験は、1時間程度の瞬間的な負荷が高まるスパイクにおいて「20万rps」、定常時の最低限の負荷は「5万rps」という目標を立てた。シナリオは、社内試遊会のプレイデータからAPI比率を算出した“通常プレイシナリオ”と、ユーザーの新規作成からガチャを引くまでを繰り返す“リセマラシナリオ”の2つを用意した。
また、最初はゲームサーバー1台に対して最適化する“ミニマム試験”から入り、チューニング後に台数を増やしてスケールをチェックするという流れをとった。永田氏は、「1台のチューニングから始めることで、負荷試験にかかるコストが減り、シンプルな構成でボトルネックも可視化しやすい。ミニマム試験で徹底的にチューニングすることをおすすめする」と語る。
事前準備として、全APIを叩くシナリオを用意し、ログ出力やマスターの状態なども本番相当の環境を整えた。また、ボトルネックが可視化できるようpprofなどのプロファイラーやtracerなども導入した。
ミニマム試験では、pprofやtracerでボトルネックを調査して、調査結果をもとにひとつずつ対応していく。「複数の対応を進めると影響度が分からなくなるため、丁寧にボトルネックを潰していくのが重要」と永田氏。パフォーマンスチューニングを繰り返すと徐々にCPU負荷も減少するため、CPU負荷が適切にかかるようクライアントを随時調整していくのも注意点だ。

負荷試験によるチューニング
特に影響の大きかった改善項目は「ライブラリの変更・更新」だったという。例えば圧縮用のライブラリである「Lz4」をバージョンアップ(v2からv4へ)するだけで、CPU負荷は22%低下した。また、ログエンコードライブラリをpbjsonから標準のencoding/jsonに変更することで、CPU負荷は33%低下したという。

ライブラリの変更・更新による改善
Go自体の設定変更もパフォーマンス改善の効果をもたらした。GC(garbage collector)の頻度を減らすためにGOGCをオフにして、適切なGOMEMLIMITを設定することでCPU負荷は9%低下。さらに、ビルド時にバイナリを最適化する「PGO」を利用することでCPU負荷は7%低下した。その他にも、EC2のインスタンスタイプをARM系に変更することで、10~20%のCPU負荷低下につながっている。
APIの調整も効果が得られた。APIログで共通レスポンスなど不要なフィールドを削除することでCPU負荷は34%低下。同一テーブルに複数クエリを発行しているロジックも調整した。
このような細かな改善策を重ねていった結果、初回は1台あたり180rps(1vcpu:90rps)であったのが、最終的には1500rps(1vcpu:380rps)にまで達した。大きくロジックを変更することなく、1vcpuあたり420%もパフォーマンスを向上させたことになる。

負荷試験によるチューニングの効果
本記事はアフィリエイトプログラムによる収益を得ている場合があります



