

本記事はFIXERが提供する「cloud.config Tech Blog」に掲載された「【生成AI】テキストから360°パノラマ画像を生成してみよう!【最新研究】」を再編集したものです。
レイチェルです。
今回はテキストを入力として、360°パノラマ画像を生成する研究をご紹介させていただきます。
その名もTaming Stable Diffusion for Text to 360 Panorama Image Generation!
以下は「skyscrapers」というプロンプトを入力して出力された画像です。結構クオリティーが高いとは思いませんか?

Citation
@inproceedings{panfusion2024,
title={Taming Stable Diffusion for Text to 360◦ Panorama Image Generation},
author={Zhang, Cheng and Wu, Qianyi and Cruz Gambardella, Camilo and Huang, Xiaoshui and Phung, Dinh and Ouyang,Wanli and Cai, Jianfei},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}
動かしてみたい人
論文の著者がGitHubでソースコードを公開しています。
また、上記のコードを自分で動かしてみたときに作ったJupyterNoteがあるので、ぜひご確認ください。
本記事では、このJupyterNoteで行っていることの解説をします。
動作環境
Google ColabのL4 GPU以上、あるいは同等性能の環境であれば動作すると思います。
研究概要
本研究はCVPR 2024内で発表された研究であり、従来の画像生成モデルであるStable Diffusionを元に作られています。
特徴としては、以下のようなものが挙げられます。
・デュアルブランチDiffusionモデルPanFusionの導入
・グローバルパノラマブランチ(全体的な視野を提供する役割)とローカル視点ブランチ(詳細な部分を提供する役割)を組み合わせて学習する
・Equirectangular-Perspective Projection Attention(EPPA) の導入
・2つのブランチ間で効果的に情報をやり取りするための仕組み
・品質の向上と生成プロセスの拡張制御の両立
・従来手法よりもクオリティーの高いパノラマ画像を生成可能
・生成プロセスにおいて、部屋のレイアウトなどの追加条件を取り入れることが可能
・「ソファが壁の左側にあり、テーブルが中央にあるリビングルーム」のような条件を指定すると、その通りにレイアウトされたパノラマ画像が生成される
詳細はぜひ以下の論文をご覧ください。
Taming Stable Diffusion for Text to 360° Panorama Image Generation
また、ChatGPTを使って楽に論文を読むコツを以下の記事で紹介しています。
【令和最新版】爆速で英語論文を理解するには?ハウツーがここにあります【GPT-4o】
JupyterNoteの解説
この章では、上記のJupyterNoteでやっていること・使い方を解説していきます。
基本的には、先頭のセルから順に実行するだけで問題ないはずです。
環境構築
環境構築のためにAnacondaを使用するため、先にインストールしておきます。
!wget -c https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh !chmod +x Miniconda3-latest-Linux-x86_64.sh !bash ./Miniconda3-latest-Linux-x86_64.sh -b -f -p /usr/local
次に、リポジトリのCloneと`environment_strict.yaml`を使って実行環境構築を行います。
!git clone https://github.com/chengzhag/PanFusion !cd ./PanFusion && conda env update -n base -f environment_strict.yaml
※Google Colab環境でconda仮想環境を構築しようとした際に、うまく動作しなかったためルート上に環境を構築しています
訓練済みモデルのダウンロード
以下の手順で、クッキーを使用してwgetを用いた訓練済みモデルをダウンロードすることができます。
なお本手順はGoogle Chromeを使用している想定で記載しています。
※本手順よりもっとスマートにwgetする方法がありましたらお知らせください!
まず、以下のリンクにアクセスします。論文の著者が訓練済みモデルを配置しているSharePointです。
次に、F12キーでデベロッパーツールを開き、ネットワークタブを開いておきます。
この状態で、ダウンロードボタンをクリックします。
このダウンロード自体はクリックした瞬間止めてしまって構いません。
すると、デベロッパーツールにダウンロードのリクエストが表示されると思うので、そのリクエストを探してみてください。
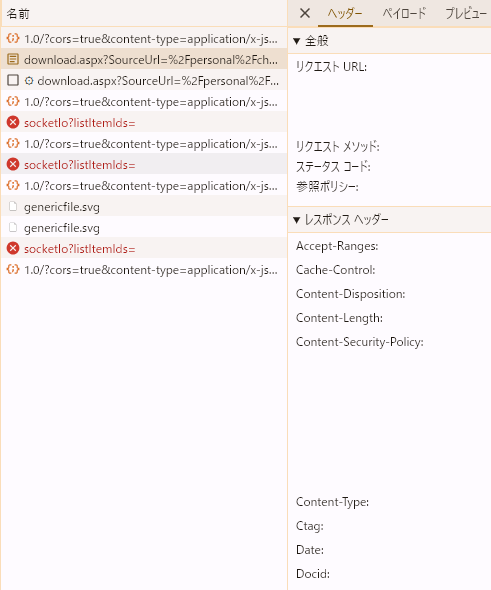
この中で使用するのは全般 → リクエストURLと、リクエスト ヘッダー → Cookieの2種類です。
この2種類の値を、以下のコマンドの該当箇所にコピペします。
# 訓練済みモデルのダウンロード !wget --header "Cookie: ここにCookieを貼り付ける" -O ./PanFusion/logs/4142dlo4/checkpoints/last.ckpt "ここにリクエストURLを貼り付ける"
このコマンドを実行することで、訓練済みモデルをダウンロードすることができるはずです。
WandBについて
本サンプルコード内では、WandBという可視化ツールを用いてマシンリソース使用量の可視化を行っています。
Weights & Biases - 機械学習開発者のためのコラボレーションプラットフォーム
使用するために、まずはアカウント作成を行う必要がありますので、上記のページからアカウント作成をお願いします。
アカウント作成後、以下のコマンドでWandBにログインします。
!wandb login
実行すると、以下のように出力されます。
wandb: Logging into wandb.ai. (Learn how to deploy a W&B server locally: https://wandb.me/wandb-server) wandb: You can find your API key in your browser here: https://wandb.ai/authorize wandb: Paste an API key from your profile and hit enter, or press ctrl+c to quit:
2行目のリンクを踏むと、ログイン画面が表示されますので、ログインしてください。
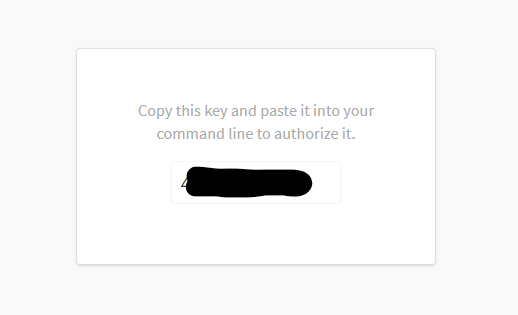
ログインすると、以下のようにAPIキーが表示されますのでコピーしましょう。
コピーしたあと、先程の出力の3行目に貼り付けエンターキーを打鍵します。
4行目にwandb: Appending key for api.wandb.ai to your netrc file: /root/.netrcと出力されれば成功です!
推論
以下のコマンドを実行することで推論が行えます。
!cd PanFusion && WANDB_MODE=online WANDB_RUN_ID=4142dlo4 python ./main.py predict --data=Matterport3D --model=PanFusion --ckpt_path=last
推論結果は/content/PanFusion/logs/4142dlo4/predict内に出力されます。
オリジナルのプロンプトを使う方法
/content/PanFusion/data/demo.txtに、独自のプロンプトを記述してパノラマ画像を生成することができます。
デフォルトでは以下のような内容になっています。
a futuristic kitchen a living room with a sliding glass door a living room Mountain view of Golden Gate Bridge and San Francisco This kitchen is a charming blend of rustic and modern, featuring a large reclaimed wood island with marble countertop, a sink surrounded by cabinets. To the left of the island, a stainless-steel refrigerator stands tall. To the right of the sink, built-in wooden cabinets painted in a muted. Majestically rising towards the heavens, the snow-capped mountain stood, its jagged peaks cloaked in a shroud of ethereal clouds, its rugged slopes a stark contrast against the serene azure sky, and its silent grandeur exuding an air of ancient wisdom and timeless solitude. Coastal cliff at sunset, waves crashing on rugged rocks. Moonlit forest, shadows dance among ancient trees. Urban skyline at twilight, city lights twinkling in the distance. ~以下、略~
このテキストファイルの中身をすべて削除し、使いたいプロンプトを記述して保存します。
例えば、僕は以下のようなプロンプトを試しました。
skyscrapers river in the forest A hill with a view of the sea with a lighthouse magical forest
あとから論文を見たら、部屋のレイアウトなどの追加条件を指定できるとのことだったので
それを試すプロンプトを書けばよかった…
demo.txtに書いたプロンプトを使用するために、推論時のコマンドを少し変更します。
--dataで渡す値をMatterport3DからDemoに変更します。
!cd PanFusion && WANDB_MODE=online WANDB_RUN_ID=4142dlo4 python ./main.py predict --data=Demo --model=PanFusion --ckpt_path=last
先ほどと同様に/content/PanFusion/logs/4142dlo4/predict内に画像が出力されます。
また、デフォルトではプロンプト1行につき画像が10枚生成されます。
画像1枚の生成に少々時間がかかりますので、大量のプロンプトを書き込むのは要注意。
出力結果のダウンロード
以下のコマンドで、出力結果のパノラマ画像をダウンロードすることができます。
# ダウンロードしたいフォルダを zip 圧縮する
!zip -r /content/predict.zip /content/PanFusion/logs/4142dlo4/predict
# 圧縮した zip ファイルをダウンロードする
from google.colab import files
files.download("/content/predict.zip")
出力された画像を見てみる
僕の方で出力した画像を何枚かご紹介させていただきます。




これはそれぞれ以下のプロンプトでの出力結果です。
・skyscrapers
・river in the forest
・A hill with a view of the sea with a lighthouse
・magical forest
どれも結構キレイに出力できているとは思いませんか?
ただmagical forestに関しては思っていたような画像ではなかったのでもう少しプロンプトを凝ってみる必要があるかも知れません。
また、画像を出力していると画像上下端がよくぼやけて出力されることがあります。
筆者曰く、これはモデルの訓練に使用したデータに上下がぼやけているものが多いためであると述べています。
ようするに訓練データ起因の問題です。
変な画像たち
中には変な画像が出力される場合もあります。


現代アートみたいなビル群に、謎の鳥居…
まぁそういう場合も時にはあります。
ですが、このように崩れた画像が出力される場合は少なく、大多数はきちんと形を保った画像であるのがこの研究の素晴らしいポイントかも知れません。
まとめ
生成AI技術の応用先は、今どんどん増えており、この研究もその1つです。
ただし、まだまだ問題点もあり成長の余地がある分野ですので、これからの発展から目が離せませんね!
レイチェル琥珀/FIXER
大学院時代はUnityとPythonを使って、コンピュータグラフィックス・機械学習の研究を行っていました。
就職後は、COBOL → Java変換の自動化技術を開発しています。
現在はCG・画像処理・AI技術の学び直し中です。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
TECH
生成AIのプロンプトがうまく書けないときのアプローチ(演繹法/帰納法) -
TECH
“GPT-10”が登場するころ、プロンプトエンジニアはどうなっているか? -
TECH
生成AIは複雑な計算が苦手、だからExcelを使わせよう -
TECH
BPEの動作原理を学び、自作トークナイザーを実装してみた -
TECH
エンジニアとプロンプトエンジニアの違い、「伝える」がなぜ重要なのか -
TECH
システムエンジニア目線で見たプロンプトエンジニアリングのコツ -
TECH
学生向けの生成AI講義で人気があったプロンプト演習3つ(+α) -
TECH
ユースケースが見つけやすい! 便利な「Microsoft 365 Copilot 活用ベストプラクティス集」を入手しよう -
TECH
自治体業務でどう使う? 生成AIアイデアソンに自治体職員が挑戦 -
TECH
アンケート分析」「トーク台本作成」を効率化、お客様サポート業務でのGaiXer活用 - この連載の一覧へ




