
AMDはデスクトップ向けの「Ryzen 9000シリーズ」を(北米時間の)7月31日に発売する。これに先立ちAMDはロサンゼルスにて「AMD Tech Day」を開催。特に同社が力を入れる「Ryzen AI 300シリーズ」を含めた新技術への説明会を開催した。
本稿はそのTech Dayレポートの第3回目となる。第1回はRyzen 9000シリーズの発売日やスペック、新チップセットの話を、第2回はRyzen 9000シリーズに追加された新しいチューニング技法を解説した。
そして今回はいよいよZen 5アーキテクチャーの詳細に踏み込んでいく。AMDはCOMPUTEXにおいて、Zen 5はZen 4よりも同コア数&同クロック設定で平均16%のIPC(クロックあたりの命令実行数)向上を果たしたと説明した。この数字はいったいどういう設計上の工夫や改善からもたらされたのか? 簡単ではあるが解説していきたい。

General SessionでZen 5の解説を担当したEVP兼最高技術責任者であるMark Papermaster氏
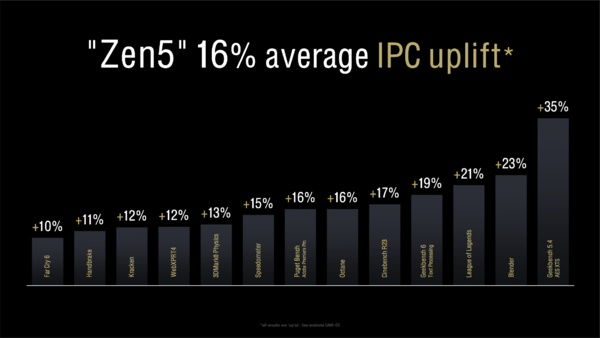
Zen 4に対するIPC向上率は平均16%というデータ。これはCOMPUTEX発表時と完全に同じデータを使用している
keep the beast fed
(猛獣に餌を与え続ける)
AMDによれば、Zen 5はこれから数世代に渡るアーキテクチャーの基盤となるべく、オーバーホールが施された。このオーバーホールは「フロントエンド」「整数実行」「ロード&ストア」「浮動小数点ユニット」の4つの部分に帯別できる。
まずフロントエンドでは従来よりも高精度かつ低レイテンシー、そしてスループットの高い分岐予測が実装された。ここを改善すれば処理の無駄を減らしワットパフォーマンスも改善する。Zen 5では命令キャッシュとマイクロOPキャッシュをデュアルポート化、すなわち2つ並列で動くようにしたおことで1サイクルあたりの予測回数を増加させている。
また、命令のデコードもデュアルパイプ化されている。結果として実行ユニットに命令を渡すディスパッチもサイクルあたり6命令から8命令へ拡張された。こうしたフロントエンド部分の改良は、後段に控える実行ユニットを遊ばせない(ストールさせない)ための改善であり、AMDはこれを「keep the beast fed(猛獣に餌を与え続ける)」と呼んでいる。

フロントエンド部分。後段の実行ユニットに絶え間なく餌(命令)を供給するため、至るところで並列化された。ディスパッチはZen 4の6命令から8命令に拡大されている
整数演算実行ユニットは1サイクルあたり最大6命令のディスパッチ/ リタイアをサポートし、4基のALU(Arithmetic and Logic Unit)を備えていたが、Zen 5では最大8命令のディスパッチ/ リタイアに6基のALUという構成に拡張された。
これらの強化ポイントをしっかり動かすためには、スケジューラーの改善も必要になる。Zen 4では4基のALUに対し4基のスケジューラーがあったのに対し、Zen 5では統合スケジューラー(Unified Scheduler)となった。実行ウインドウもZen 4の320命令から448命令に拡大している。

整数演算実行ユニット部分。フロントエンド部分でより多くの命令を実行ユニットに供給できるようになったため、下流(AMDのたとえ話で言うところの野獣)にある部分、ここではディスパッチ/ リタイアやALU等を増やしてスループットを上げよう、という話

ここまでの図を見て、Zen 4ってどうだったっけ? という方向け(筆者含む)にZen 4の解説資料も引用しておこう
浮動小数点実行ユニットにも強化が入った。Zen 5ではついにAVX512において512bit幅での処理に対応。Zen 4ではAVX512を実行する際クロックを落とさないために256bitずつ2サイクル実行(Double pumping 256bit pipeline)だったものを、512bitの1サイクルでAVX512を実行できるようになった。
このAVX512実行中であってもCPUの動作サイクルを下げる必要はない(ペナルティーなしにAVX512が使える)という点は非常に魅力的だ。さらに浮動小数点加算(FADD)のレイテンシーを3→2サイクルに短縮している。

浮動小数点実行ユニット部分。AVX512が512bit幅のデータバスを持つようになり、1クロックで実行できるが、クロックのペナルティーを受けない(インテルのAVX512実装とは対照的)。FADDに関しても従来よりレイテンシーが短縮されている
最後のピースはロード&ストアだ。L1データキャッシュはZen 4では8ウェイ32KBだったものが、Zen 5では12ウェイ48KBに拡大。率にすれば実に50%増という大規模な強化だが、キャッシュ増に付いて回るレイテンシー増加がない、という点に驚く。
さらに1サイクルあたりZen 4では3ロードだったものがZen 5では4ロードを実行可能になった。言い換えれば整数演算では1クロックで4回のメモリー操作を処理できるのだ。一方浮動小数点の場合は浮動小数点実行ユニット側の制限から512bitのデータを2回ロード可能になる。
これらの改善によりL1キャッシュの帯域幅が2倍になったが、同時にL2からL1への帯域幅も2倍に増やし、プリフェッチのアルゴリズムも微調整するなど、データの読み込み速度向上に関してかなりの手が入っている。

ロード&ストア部分。L1データキャッシュが50%増量したのにレイテンシーが据え置きだとか、帯域が倍増しているとか、地味ではあるが確実に強くなっている部分でもある。
本記事はアフィリエイトプログラムによる収益を得ている場合があります








