





NVIDIAは6月18日、LLMをトレーニングするのに使用する合成データ生成に特化した大規模言語モデル「Nemotron-4 340B」ファミリーを発表。商用利用可能なオープンモデルライセンスで公開された。
合成データの生成とは
LLMの訓練には大量の専門的なデータが必要になる。だが、インターネット上で収集されたデータを人手で収集・注釈付けするのは非常にコストがかかる。プライバシー保護やデータ不足などの問題もあり、実際のデータを模倣して人工的に生成される「合成データ(Synthetic Data)」の生成に注目が集まっている。
「Nemotron-4 340B」は、基本となるモデル「Nemotron-4-340B Base(以下Baseモデル)」の他に、プロンプトから合成データを生成する「Nemotron-4-340B Instruct(以下Instructモデル)」と、生成された合成データを評価してフィルタリングする「Nemotron-4-340B Reward(以下Baseモデル)」から構成されている。
このプロセスにより、低コストで高品質なデータを生成し、効率的なLLMの訓練が実行できるようになる。
作成された合成データを評価してフィルタリング
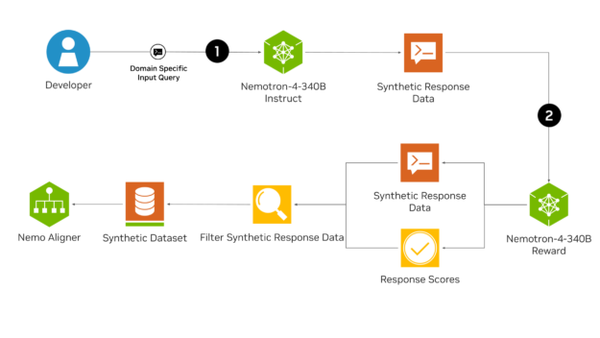
では、「Nemotron-4 340B」による合成データ生成(Synthetic Data Generation:SDG)パイプラインを見ていこう。
開発者が「レシピの手順を簡潔に説明してください」「私はレストランで働く従業員です。客からの質問に答えてください」といったプロンプトを入力するとInstructモデルがこれを受けて合成データを生成する。
生成されたデータはRewardモデルによってデータの品質を評価され、最終的な学習データセットに加えるべきデータだけがフィルタリングされる。
重要なのは、SDGではただ応答データを生成するだけでなく、生成したデータの品質を検証し、高品質なデータのみを確保することだ。
「HelpSteer2」データセットで微調整
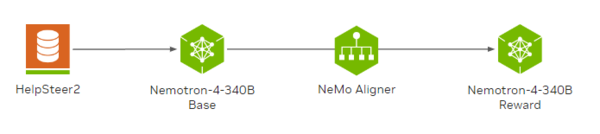
Rewardモデルをもう少し詳しく見ていこう。このモデルはBaseモデルを「HelpSteer2」というAIモデルの応答の品質を評価するために作られたデータセットを使用して微調整したものだ。
HelpSteer2は、1万組の会話ペアおよび、それぞれのペアについて人力で「有用性(Helpfulness)」「正確性(Correctness)」「一貫性(Coherence)」「複雑さ(Complexity)」「詳細度(Verbosity)」の5つの属性が5段階で評価されている
HelpSteer2を使った微調整により、Rewardモデルはプロンプトに対する応答を5つの属性を使って高精度に評価できるのだ。
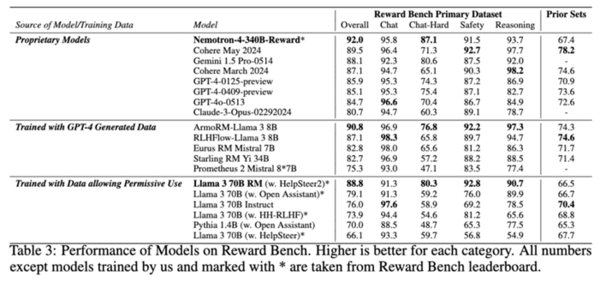
Rewardベンチというベンチマークを使った評価では総合スコアが92.0とトップクラスの成績を収めており、特に「Chat-Hard」という曖昧な質問への対応力を評価する項目で、次点の「Gemini 1.5 Pro」を7ポイント近く上回っている。
つまり、Rewardモデルはプロンプトに対する応答を人間の好みに即して高精度に評価することで、合成データ生成の品質管理に優れた性能を発揮するということだ。
新ライセンスは商用利用も可
Nemotron-4 340Bのリリースに伴いNVIDIAは新たに「 NVIDIAオープンモデルライセンス」を導入。
モデルおよびそのアウトプットを、個人的、研究的、商業的利用において、帰属を要求されることなく、配布、修正、使用することを許可する寛容なライセンスだ。
ベースモデルを業務内容にあわせて調整するモデルアラインメントは生成AIの急速に発展している分野のひとつ。
合成データ生成(SDG)はただ応答データを生成するだけでなく、生成したデータの品質を検証し、高品質なデータのみを確保することに主眼が置かれている。
LLMの精度は、学習データの質よりもむしろ量に大きく依存するため、 「品質フィルタリング」は極めて重要なステップとなる。つまり、高品質なデータを大量生産できることが良質なLLM開発の鍵になるのだ。
同モデルはローカル環境で使用することもできるが、「8つのGPUを備える単一のDGX H100に収まる」サイズとのことで法人や研究機関はともかく個人規模ではかなり厳しそうだ。
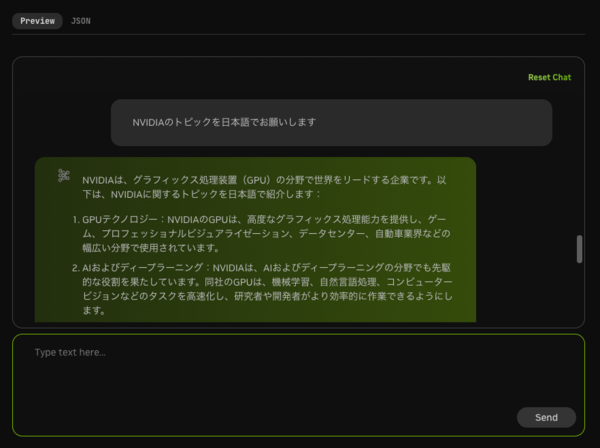
なお、同モデルは合成データ生成が主眼に置かれているが、通常のLLMとしても優秀だ。NVIDIAのデモサイトで実際に試すと、精度・速度共に現代の標準的LLMに求められる水準は達しているように思える。非対応のはずの日本語もある程度理解してくれるようだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


















