




プロセスを微細化してもSRAM容量が増えない
Gaudi 3がインテルによる買収直後くらいに開発をスタートしたと考えるもう1つの理由は、オンダイSRAM容量が変わらないことである。これまで連載で何度か説明したが、7nmあたりを境にプロセスを微細化してもSRAM容量が増えなくなりつつある。
理由はSRAM密度はトランジスタの寸法よりも配線の寸法に依存しつつある(以前はトランジスタの寸法が支配的だったが、トランジスタが小型化したことで今は配線寸法が支配的になっている)ことで、5nmだろうが7nmだろうが同一容量のSRAMのエリアサイズはほとんど変わらず、一方5nmにすることでエリアサイズあたりのコストは1.5倍くらいになっている。要するに、大容量のSRAMを搭載するのはコスト的に割に合わなくなっているということだ。
回避策はあって、SRAMは7~6nmあたりで製造し、これを2Dあるいは3D的にチップレットで接続するというものだ。インテルで言えばPonte Vecchioがこれに相当する。Ponte Vecchioは、コンピュートタイルはTSMC N5で製造されるが、Rambo CacheはIntel 7での製造で、大容量キャッシュを相対的に低価格で利用可能にしている。
Raja Koduri氏が2017年11月にインテルに入社、そこからPonte Vecchioの開発をスタートしたことを考えると、Gaudi 3がもしインテルによる買収後に企画がスタートしたとすれば、当然2次キャッシュはチップレットの形を想定すると思われる。それをしていないあたり、企画そのものはやはりインテルの買収前だったのだろう。
Gaudi 3は3種類の構成で提供
性能の話をする前に、システム構成について補足する。Gaudi 3はOAMモジュールとそれを8枚まとめたシステム、それとPCIeのアドオンカードの3種類の構成で提供される。

PCIeカードが提供されるのがInstinct MI300XやB100/B200との違い。もっともNVIDIAはB40というPCIeカードの提供を予定しているようだ

基調講演でHLB-325を披露するGelsinger CEO

HLB-325の横でOAMを持って踊る(本当に踊っていた)Gelsinger CEO(Youtube動画の1時間24分11秒あたりから)
このHLB-325の内部結線がその下の画像だ。まずイーサネットであるが、各OAMから24本の200GbEが出てくる。これを3本づつ束ね、7対はHLB-325上でのOAM同士の相互接続に利用、残り1対を外部の相互接続に使う形になっている。
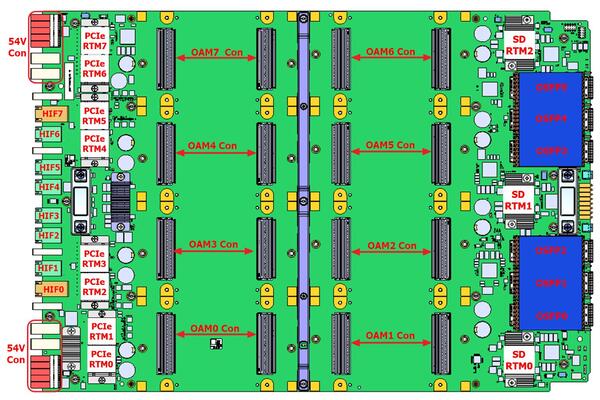
HLB-325。PCIeのReTimerがけっこうエグいほど並んでいる。ベースボードへは54V供給となっている

内部結線図だが、図が少し間違っている。下半分のOAMに関しては中央の相互接続につながるのが21×200G RoCE、OSFPコネクターにつながるのが3×200G RoCEとなる(上半分は正しい)
ちなみにPCIeカードタイプのHL-338に関しては、21本の200G PHYを搭載しており、うち18本を6本づつ束ねてHL-338同士の相互接続に利用。残りの6本を外部接続に回すという形になる。
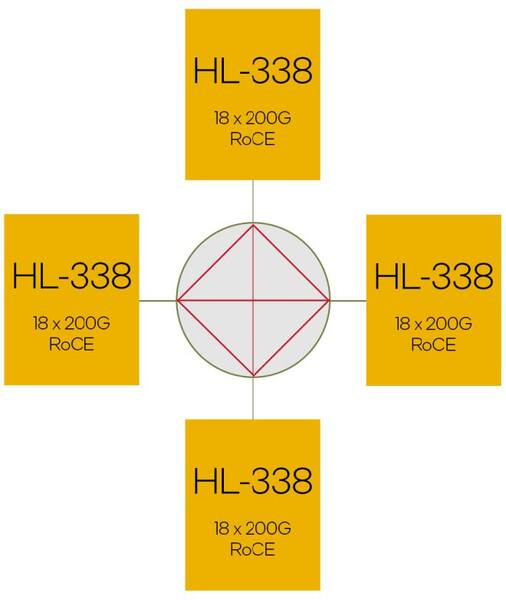
HLB-325ではOAMを600Gbpsで相互接続しているが、HL-338では1.2Gbpsで相互接続する形となる
このイーサネットであるが、今回インテルはUEC(Ultra Ethernet Consortium)への対応を改めて表明した。UECは昨年7月に設立された業界団体で、そもそも創設メンバーにインテルも入っているから対応しない策はないのだが、UECは既存のイーサネットの物理層の上に独自プロトコルを実装し、クラスター・インターコネクトを構築することを目的としている。
ほかにもいろいろあるが、当初から目的の1つにAI/ML optimized APIを提供することが掲げられているので、とりあえずイーサネットベースのAI/MLアクセラレーター用の相互接続に使えることは間違いない。
ただもちろんまだ団体ができただけでスペックも出ていないわけだが、インテルは「将来のAI Networking」でUECを利用することを表明した。ただ、少なくともGelsinger CEOの説明からすると、UECが実装されるのはGaudi 3の次以降ということになりそうで、Gaudi 3は独自プロトコルのまま終わりそうである。

今年3月には新たに45ものメンバー企業を迎え、かなり大規模な団体になっている。現在少なくとも8つ(Physical Layer/Link Layer/Transport Layer/Software Stack/Storage/Mamagement/Compliance/Performance Debug)のワークグループが標準化作業を行なっている
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 - この連載の一覧へ







































ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












