




連載750回に引き続き、12月14日の“AI Everywhere”イベントから、今度は第5世代Xeon ScalableことEmerald Rapidsの詳細を説明しよう。
Emerald RapidsにはXCC、MCC、LCCの3種類が存在する
まずダイの構成から。発表記事にもあるように、64コアで2タイルのXCC(eXtreme Core Count)と32コアで1タイルのMCC(Medium Core Count)、それと20コアで1タイルのEE LCC(Energy Efficient Low Core Count)の3種類が存在する。ここで問題になるのがMCCである。
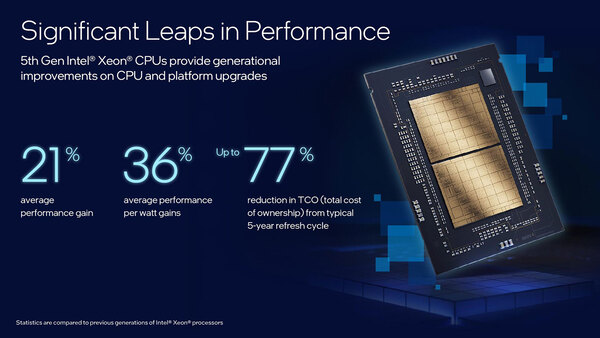
第5世代Xeon Scalable。個々の数字については後述する
まず順を追って説明すると、XCCは32コア×2なわけだが、上の画像にある右側のパッケージ写真を切り抜いて縦横補正を掛けたのが下の画像だ。

黄色の部分がUPI/PCIeとアクセラレーター各種と考えられる
タイルの中は7×5=35個のブロックと、その上下に大きなエリアがある。そして赤枠のブロックだけ中央に縦線が入っており、他のブロックと様相が異なる。おそらくこれがDDR5のI/Fブロックと考えられる。
逆にPCIeやアクセラレーターらしきものは35個のブロックには見当たらない。ここから考えると、XCCのタイルは下図のような構造になっていると推定される。
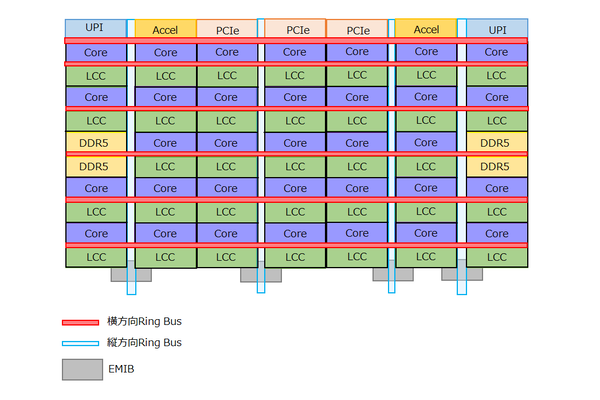
XCCのタイル構造推定図
このタイルを2つ用意し、片方を180度ひっくり返して接続することで、2タイルのXCCが完成するわけだ。このXCCのTileは連載715回でも推定した通り、25.2×30.9mmで778.7mm2という巨大なものになる。
ちなみにこの計算ではCPU+3次キャッシュのブロックが33個という計算になるが、それをアクセラレーターに割り振っている感じもしない。おそらくだが33個分のCPU+3次キャッシュのブロックが用意され、うち1つは冗長ブロックに割り当てているのだと思われる。
実際これだけ大きなダイサイズだと、冗長ブロックを用意しないと歩留まりがかなり悪くなりそうだからだ。ちなみにこのタイルを2つつなげると以下の構造になると考えられる。
- CPU/3次キャッシュブロック×66(うち2つは冗長ブロック)
- メモリーコントローラー×4(おのおの2ch)
- PCIe/CXL×6(うち1つはPCH接続用のDMIに割り当て)
- UPU×4
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































