ELYZA、日本語LLM「ELYZA-japanese-CodeLlama-7b」一般公開
文● ASCII

ELYZAは11月15日、Metaが開発したコード生成専用大規模言語モデル(LLM)である「Code Llama」に対し、日本語の追加事前学習をしない、コード生成・補完に特化した70億パラメーターの日本語LLM「ELYZA-japanese-CodeLlama-7b」を開発し、一般公開した。
同社は、8月時点で「Llama 2」をベースとした商用利用可能な日本語LLM「ELYZA-japanese-Llama-2-7b」を公開している。Code Llamaは「Llama 2」をベースとし、コード生成およびコード補完に関する能力を持つように追加で訓練されたモデルとなる。
今回公開したELYZA-japanese-CodeLlama-7bは、先般の開発で同社が用いた日本語の追加事前学習の一連のメソッドが、Llama 2以外のモデルでも汎用的に適用可能であるかを実験した取組みの一部で、元々のモデルが持つ能力を保持したまま日本語の能力を獲得できることを示す一例になると考えているという。
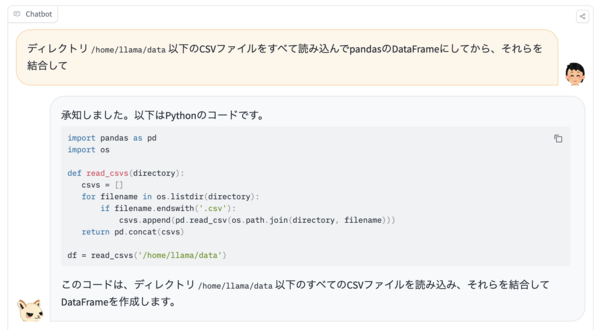
サンプルとして以下のような出力ができる
なお、本モデルは、研究および商業目的での利用が可能なモデルとしての公開となる。
ELYZA-japanese-CodeLlama-7bの詳細についてはこちらを参照のこと。
「ASCII STARTUPウィークリーレビュー」配信のご案内

ASCII STARTUPでは、「ASCII STARTUPウィークリーレビュー」と題したメールマガジンにて、国内最先端のスタートアップ情報、イベントレポート、関連するエコシステム識者などの取材成果を毎週月曜に配信しています。興味がある方は、以下の登録フォームボタンをクリックいただき、メールアドレスの設定をお願いいたします。

本記事はアフィリエイトプログラムによる収益を得ている場合があります