




























パナソニックHD、「確率的生成モデル」と「自己教師あり学習」を統合し画像の不確実性まで推定できる画像認識AIを開発
パナソニックグループ
パナソニック ホールディングス株式会社(以下、パナソニックHD)は、「確率的生成モデル」と「自己教師あり学習」の関係性をコンピュータビジョン分野で初めて(※1)解き明かし、画像の特徴をAI自身が自動で理解する画像認識AIを開発しました。
AIは大規模なデータセットを用いた学習を通じて、画像中に映る物体の特徴を把握します。高精度なモデル開発には、大量のデータセットに対して人によるラベリング作業が必要であることが課題視されており、近年は大量のラベルなしデータからAI自身に学習させる手法の開発が進み、特にGPTに代表される自然言語分野で先行して大きな成果を挙げつつあります。一方、大規模なデータセットには、人が見ても判断が難しい「不確実性の高いデータ」(ノイズ、ボケ、光の反射などにより判断が困難なもの)がしばしば存在し、AIの学習を阻みます。この不確実性がAIの品質を下げることから、近年解決すべき課題として大きな注目を集めています。
本手法は、従来難しかった画像の不確実性を考慮した学習を実現するため、「確率的生成モデル」と「自己教師あり学習」を初めて理論的に統合しました。また、実験により、これまで「自己教師あり学習」で難しかった画像中の特徴の不確実性(AIにとって学習が難しい画像である度合い)を推定できることを実証しました。AI学習に必要とされるデータの「量」と「質」の課題を解決し、AIの信頼性を高められる汎用的な技術として、今後幅広い分野で活躍することが期待されます。
本技術は、「自己教師あり学習」のアルゴリズムを俯瞰できる理論を確立した学術的な貢献と先進性が国際的に認められ、AI・コンピュータビジョン技術のトップカンファレンスであるIEEE/CVF International Conference on Computer Vision (ICCV) 2023に採択されました(採択率26.15%)。2023年10月2日から2023年10月6日にフランスパリで開催される本会議で発表します。
■技術の内容
認識、検出、セグメンテーションなどを行う高精度な画像系AIモデルの開発には、大量のデータ収集とアノテーションによる学習データの準備に、多大な時間とコストを要することがAIの社会実装を進める上で課題となっています。そこで、事前に大量のラベルなしデータからAI自らに生成させた疑似的な正解ラベルを使って、画像の特徴を学習し、その後、タスク毎にわずかなデータで所望のタスクを高精度に実現させる「自己教師あり学習」が、アノテーションの負荷を大幅に下げる方法として、近年盛んに開発されています。代表的な手法としてはSimSiam、SimCLR、DINOが知られています。
大量のラベルなしデータから画像に映し出された特徴を事前学習するにあたり、様々なタスクに応用できる汎用的な特徴表現を獲得するには、同じ物体に対して、一部のみ写っている場合・光の具合が異なる場合・画像が回転している場合など、様々な異なる見え方に対しても、同じ物体であるとAI自身が判定できるよう学習する必要があります。前述のSimSiamなどの「自己教師あり学習」の手法では、それぞれの画像に対して回転・切り出し・色変換などの画像拡張を自動的に行い、AI目線での距離(特徴空間上での距離)が近くなるように学習することで、見え方が異なったとしても、同じ物体として認識できるよう事前に学習します。このAIをベースに用いることで、少量のラベル付けで様々なタスクを高精度に実現できることが知られています。
しかし、従来の「自己教師あり学習」は同じ画像の距離が近づくように学習する際に、各画像そのものの性質を余り考慮していません。何が写っているかわかりにくい画像(不確実性が高い)も、何が写っているか明確に分かりやすい画像(不確実性が低い)も同じように扱ってしまうため、不確実性の高い画像により、事前学習がうまく進まなかったり、モデルの精度を下げてしまう課題があります。
この課題に対し、パナソニックHDは、確率統計的なアプローチでの解決を試みました。不確実性の表現に優れたAI技術としてはVariational Auto Encoderなどに代表される確率的生成モデルが知られています。本研究では、この確率的生成モデルの数式から、従来の「自己教師あり学習」で用いられる数式を導出できることを証明し、二つの異なるAI技術の関係を理論的に明らかにしました(図1)。さらに、この知見を応用し、データセット中の画像の不確実性を推定できる手法を開発しました。ImageNet100(ベンチマークデータセット)に対する評価実験で、画像の不確実性を本手法が推定できたことを定性的に実証するとともに(図2)、本手法で不確実性が高いと推定した画像を画像分類にかけた際、正答率が低くなる傾向がある、すなわち不確実性がAIの認識率に影響するという定量的な知見を得ました(図3)。
これまで、AIの学習データには質の高いデータが大量に必要であることが常識となっていましたが、今回得られた知見により、学習データの質を不確実性として扱い、推定した不確実性をAIモデルの学習アルゴリズムに織り込むことで、データの質というハードルを乗り越えられるAIを実現できる可能性を示すことができました。
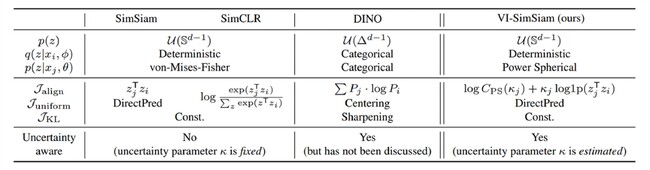
図1:本手法(VI-SimSiam)、およびSimSiam, SimCLR, DINOといった代表的な「自己教師あり学習」と確率的生成モデルの数式の関係。確率的生成モデルにおける確率分布p,qの定義を変えることで異なるアルゴリズムが導出されることを示している。(採択論文より引用 (C) 2023 IEEE)

図2:本手法で推定した画像の不確実性。上段は不確実性の低い画像、下段は不確実性の高い画像と推定された。(採択論文より引用 (C) 2023 IEEE)
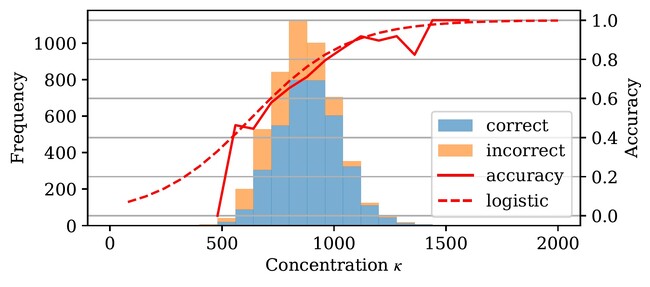
図3:不確実性を示すパラメータκと画像認識精度の関係性を示すヒストグラム。κが大きくなり、不確実性が低くなるにつれ、正解(correct)の割合が高くなり、実線で示す画像認識精度も高くなる。(採択論文より引用 (C) 2023 IEEE)
■今後の展望
今回確立した「自己教師あり学習」のアルゴリズムは、大量のデータセットに対して人によるラベリング作業なしで画像の特徴を学習できるため、データの「量」の課題を解決するのみならず、AIが学習する画像の不確実性まで考慮できることで、データの「質」というAI開発の本質的な課題をも解決できる可能性を示しました。今後もパナソニックHDは、AI技術の社会実装を加速し、お客様のくらしやしごとの現場へのお役立ちに貢献するAI技術の研究・開発を推進していきます。
※1:2023年9月22日現在
▼論文情報
Representation Uncertainty in Self-Supervised Learning as Variational Inference
https://arxiv.org/abs/2203.11437
本研究は、パナソニックHD テクノロジー本部の中村 拓紀、岡田 雅司、パナソニックHD 客員総括主幹技師で立命館大学 教授の谷口 忠大氏との連携による研究成果です。
■関連情報
・ICCV2023 公式サイト
https://iccv2023.thecvf.com/
・Panasonic×AI WEBサイト
https://tech-ai.panasonic.com/jp/
・Panasonic×AI X
https://twitter.com/panasonic_ai