

本記事はソラコムが提供する「SORACOM公式ブログ」に掲載された「Google CloudとSORACOMでリアルタイム分析とAI・機械学習」を再編集したものです。
目次
アーキテクチャ1.ストリーム処理によるリアルタイム分析とデータ集約
1-1.リアルタイム分析の処理概要
1-1.SORACOM Funnel / BeamからGoogle Cloud Pub/Sub連携
1-2.Google Cloud Pub/Sub → Google DataFlow → Google BigQuery
3.機械学習モデル構築 Google BigQuery → Google VertexAI
1.モデル構築
4.機械学習モデルの推論実行SORACOM Funk → Google Cloud Functions → Google VertexAI
1.SORACOM FunkからGoogle Cloud Functions呼び出し
2.Google Cloud Functions
3.デバイスからの推論実行
さいごに
皆様、こんにちは。ソリューションアーキテクトの松永(ニックネーム:taketo)です。
IoTプロジェクトのクラウドへの連携が加速している一方で、最近ではChatGPTを初めとしてAI・機械学習の社会実装も普通になってきましたね。今回は、そんなGoogle Cloudを使ったAI・機械学習に焦点を当て、SORACOMを使ったリアルタイム分析とAI・機械学習をご紹介致します。
お客様のプロジェクトでAI・機械学習の利用を検討されている方がどのような流れで処理を実装頂けるのか? 導入としてたたき台となるようなアーキテクチャをご紹介致しますので、大枠の流れを参考にしてみてください。
少し長いのでハンズオンで検証しなくとも全体のコードの流れを追って頂くのも良いと思います。是非ご一読ください! それでは早速行ってみましょう!
アーキテクチャ
はじめに、全体のアーキテクチャをご説明します。
今回例として 気象データを扱うIoTプロジェクトを想定し、東京や大阪といった地域ごとにデバイスが1つずつ配置されていることを前提としています。デバイスでは、定期的に温度を計測し位置情報を送信、また同時に未来の気温を予測する仕組みを想定します。
アーキテクチャでは大きく「データアップロード」「モデル構築」「デバイス制御」する流れがあります。「データアップロード」では、デバイスから「simId」「緯度」「経度」「温度」が定期的に送信され、BigQueryに集約していく仕組みを構築します。「モデル構築」は下記の図でBigQueryに集約されたデータを元にAI・機械学習のモデルを構築し、VertexAIにデプロイする流れです。最後に、「デバイス制御」では「緯度」「経度」「日時」の情報を送信し、「温度」を予測する仕組みを構築します。
1. データアップロード:ストリーム処理によるリアルタイム分析とデータ集約 SORACOM Funnel / Beam → Google Cloud Pub/Sub → Google DataFlow → Google BigQuery
2. 機械学習: 機械学習のモデル構築 Google BigQuery → Google VertexAI
3. デバイス制御:機械学習モデルの推論実行 SORACOM Funk → Google Cloud Functions → Google VertexAI
本ブログでは、デバイスはPCにSORACOM Arcを稼働させて動作を模擬しております。お客様の環境ではSORACOM Arc、またはSORACOM IoT Simを利用することでデバイスの動作を実装してください。

1.ストリーム処理によるリアルタイム分析とデータ集約
ここでは、デバイスから送信されるデータをリアルタイムで分析し、BigQueryに集約する流れを構築します。
1-1.リアルタイム分析の処理概要
リアルタイムの処理は、Google Dataflowを使って構築します。
デバイスから送信される、「simId」「緯度」「経度」「温度」情報は、Dataflowが処理する時刻を元に3時間間隔で纏めるWindow処理をします。ここでは地域ごとに1つずつデバイスが配置されている前提として、「simId」ごとにグループ化することにより地域ごとの処理を行います。グループ化した後に、平均気温を計算することで結果として地域ごとに数時間ごとの平均気温を計算します。
本ブログでは、Window間隔は約3時間として記載しております。

1-1.SORACOM Funnel / BeamからGoogle Cloud Pub/Sub連携
SORACOMからGoogle Cloud Pub/Subへデータ転送する方法は2つあります。
データ送信頻度がより高い場合や、TCP/UDPを利用する場合には非同期通信で様々なプロトコルに対応できるSORACOM Funnelが良いでしょう。一方、SORACOM Beamでは、HTTPエントリポイントを利用する仕組みで同期通信で転送されるためGoogle Cloud Pub/Subへの連携で失敗した際のエラーをデバイス側で検知したい場合に選択していただくのが良いと思います。
本ブログでは、SORACOM Beamを利用してデータアップロードをする例を記載しております。
- ユーザードキュメント「Google Cloud Cloud Pub/Sub にデータを送信する」(SORACOM Funnel版)
- ユーザードキュメント「Google Cloud Cloud Pub/Sub にデータを送信する」(SORACOM Beam版)
1-2.Google Cloud Pub/Sub → Google DataFlow → Google BigQuery
1-2-1.Google Cloud Pub/Sub
「Google 公式ドキュメント:トピックの作成と管理」を参考に、任意のトピックを構築しましょう。ここでは、トピックを「projects/soracom-blog-project-id/topics/weather」とします。
1-2-2.Google Dataflow
Google Dataflowでリアルタイム分析のパイプラインを構築していきます。Google DataflowはApache Beamを利用することができデータのリアルタイム分散処理を実行することができます。「Google 公式ドキュメント:Apache Beam ノートブックを使用して開発する」を参考にインタラクティブにDataflowを開発する環境を構築しましょう。ここでは、Dataflowのメニューから「Workbench」を選択して、Jupyter Notebook環境を構築してください。
a.パイプライン
ここでは、必要なライブラリのインポートなど初期設定と作成したGoogle Cloud Pub/Subのトピックからメッセージを読み込む処理を書いています。
import apache_beam as beam from apache_beam.runners.interactive import interactive_runner import apache_beam.runners.interactive.interactive_beam as ib from apache_beam.options import pipeline_options from apache_beam.options.pipeline_options import GoogleCloudOptions import google.auth from apache_beam import Map, ParDo from apache_beam import GroupByKey from apache_beam import window, WindowInto import json import pandas as pd from datetime import datetime # The Google Cloud PubSub topic that we are reading from for this example. topic = "projects/soracom-blog-project-id/topics/weather" # So that Pandas Dataframes do not truncate data... pd.set_option('display.max_colwidth', None) # Setting up the Beam pipeline options. options = pipeline_options.PipelineOptions(flags={}) # Sets the pipeline mode to streaming, so we can stream the data from PubSub. options.view_as(pipeline_options.StandardOptions).streaming = True # Sets the project to the default project in your current Google Cloud environment. # The project will be used for creating a subscription to the PubSub topic. _, options.view_as(GoogleCloudOptions).project = google.auth.default() ib.options.recording_duration = '2m' p = beam.Pipeline(interactive_runner.InteractiveRunner(), options=options)
b.統計処理
ここでは、次ステップ「3.パイプライン構築」で必要となる関数を定義しています。
def key_value_fn(element): key = element["simId"] return (key, element) def get_means(element): simId, values = element length = len(values) temperature_ave = sum(list(map(lambda v: v["temperature"], values)))/length precipitation_ave = sum(list(map(lambda v: v["precipitation"], values)))/length return { 'simId': simId, 'location': values[0]["location"], 'latitude': values[0]["latitude"], 'longitude': values[0]["longitude"], 'temperature_ave': temperature_ave, 'precipitation_ave': precipitation_ave } def convert_to_schema_original(element): return { 'SIM_ID': element["simId"], 'LOCATION': element["location"], 'LATITUDE': element["latitude"], 'LONGITUDE': element["longitude"], 'TEMPERATURE': element["temperature"], 'PRECIPITATION': element["precipitation"], 'CREATED_AT': element["createdAt"] } class AnalyzeElement(beam.DoFn): def process(self, element, timestamp=beam.DoFn.TimestampParam, window=beam.DoFn.WindowParam): yield { 'SIM_ID': element["simId"], 'LOCATION': element["location"], 'LATITUDE': element["latitude"], 'LONGITUDE': element["longitude"], 'TEMPERATURE_AVERAGE': element["temperature_ave"], 'PRECIPITATION_AVERAGE': element["precipitation_ave"], 'WINDOW_START_AT': window.start.to_utc_datetime(), 'WINDOW_END_AT': window.end.to_utc_datetime() }
c.パイプライン構築
ここでは、パイプライン処理を書いています。1行ずつ処理のステップを書くことができますが、詳細を少し解説致します。
最初の`data`はGoogle Cloud Pub/Subのトピックからメッセージを読み出し、JSON形式に変換しています。
その後、`original_table_data`は JSON変換した`data`からBigQueryのテーブルスキーマに変換しています。
最後に、`summarized_table_data`は1分ごとのWindow処理を施しています。そして、simIdでグルーピング処理。今回デバイスは各地域に1つずつ配置されていることから、地域ごとにGroupByしている処理となります。そして、平均気温の計算とテーブルスキーマへの変換処理をしています。
Window処理は、Dataflowで処理される時刻を元に実行されます。
本ブログでは、気象データを1時間ごとに計測したものを利用致しますが、20秒ごとに送信します。
Windowを1分ごとに処理することで、3時間分の気象データを纏めて処理する実装としております。
data = (p | "Read from PubSub" >> beam.io.ReadFromPubSub(topic=topic) | "Convert to JSON" >> beam.Map(json.loads)) original_table_data = (data | "Table Schema Original" >> Map(convert_to_schema_original)) summarized_table_data = (data | "Fixed Window" >> WindowInto(window.FixedWindows(1)) | "Convert KV for Group" >> Map(key_value_fn) | "Group by SimId" >> GroupByKey() | 'Statistics' >> beam.Map(get_means) | 'Table Schema Summary' >> beam.ParDo(AnalyzeElement())) # table_data= data | 'Table Schema' >> beam.ParDo(AnalyzeElement())
d.稼働確認
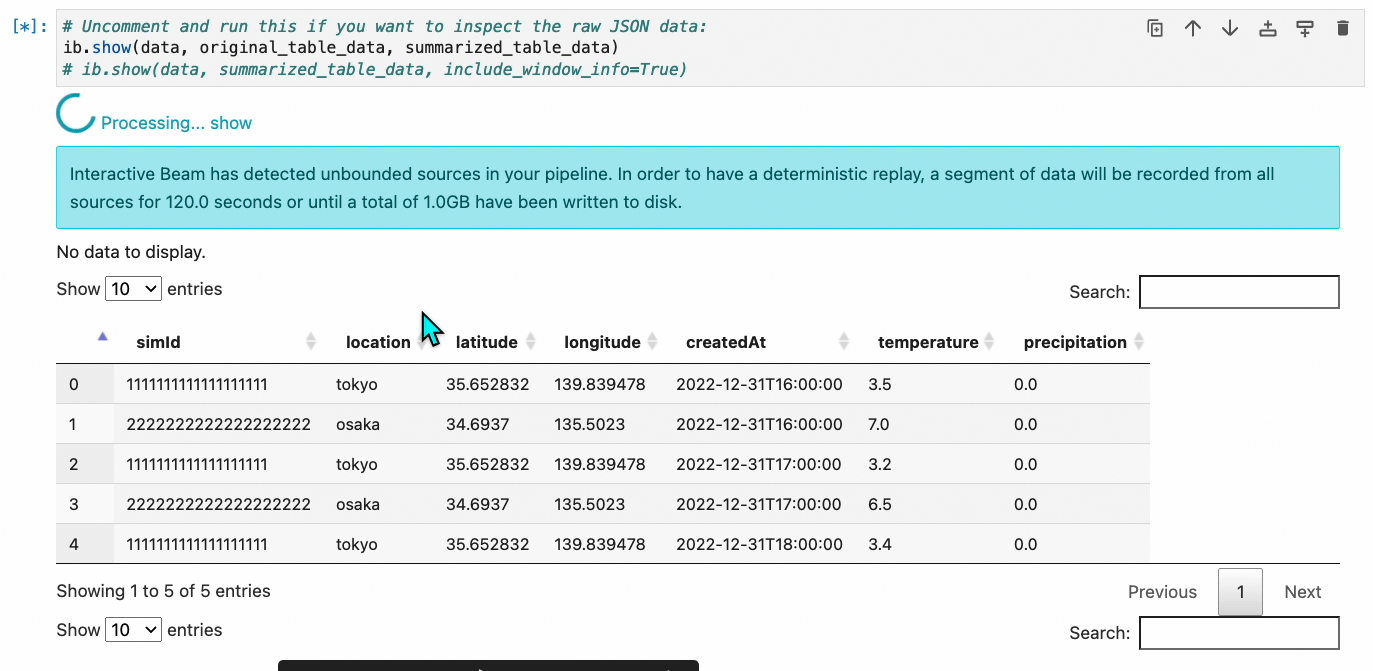
ここで、パイプラインの処理を実際に試すことができます。
実際にデータ送信をするには、次のステップを参照してください。
#稼働確認の場合のみ「#」を外してください。稼働確認が取れたら全て「#」でコメントアウトします。 ib.show(data, original_table_data, summarized_table_data) # Uncomment the line below and run this if you want to inspect the raw JSON data with window info: # ib.show(data, summarized_table_data, include_window_info=True)
e.データInsert
ここでは、元データと地域ごとの平均気温を別々のテーブルにInsertする処理を書いています。
元データは、`WEATHER_ORIGINAL`へ。平均気温が計算されたデータを`WEATHER_SUMMARY`にInsertしています。
table_spec_original='soracom-support:WEATHER.WEATHER_ORIGINAL' table_schema_original = { 'fields': [{ 'name': 'SIM_ID', 'type': 'STRING', 'mode': 'REQUIRED' }, { 'name': 'LOCATION', 'type': 'STRING', 'mode': 'NULLABLE' }, { 'name': 'LATITUDE', 'type': 'FLOAT', 'mode': 'NULLABLE' }, { 'name': 'LONGITUDE', 'type': 'FLOAT', 'mode': 'NULLABLE' }, { 'name': 'TEMPERATURE', 'type': 'FLOAT', 'mode': 'NULLABLE' }, { 'name': 'PRECIPITATION', 'type': 'FLOAT', 'mode': 'NULLABLE' }, { 'name': 'CREATED_AT', 'type': 'DATETIME', 'mode': 'NULLABLE' }] } bq_original_table = (original_table_data | beam.io.WriteToBigQuery( table_spec_original, schema=table_schema_original, write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND, create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED) ) table_spec_summarized='soracom-support:WEATHER.WEATHER_SUMMARY' table_schema_summarized = { 'fields': [{ 'name': 'SIM_ID', 'type': 'STRING', 'mode': 'REQUIRED' }, { 'name': 'LOCATION', 'type': 'STRING', 'mode': 'NULLABLE' }, { 'name': 'LATITUDE', 'type': 'FLOAT', 'mode': 'NULLABLE' }, { 'name': 'LONGITUDE', 'type': 'FLOAT', 'mode': 'NULLABLE' }, { 'name': 'TEMPERATURE_AVERAGE', 'type': 'FLOAT', 'mode': 'NULLABLE' }, { 'name': 'PRECIPITATION_AVERAGE', 'type': 'FLOAT', 'mode': 'NULLABLE' }, { 'name': 'WINDOW_START_AT', 'type': 'DATETIME', 'mode': 'NULLABLE' }, { 'name': 'WINDOW_END_AT', 'type': 'DATETIME', 'mode': 'NULLABLE' }] } bq_summarized_table = (summarized_table_data | beam.io.WriteToBigQuery( table_spec_summarized, schema=table_schema_summarized, write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND, create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED) )
f.Dataflowへデプロイ
ここでは、作成した機能をデプロイします。
from apache_beam.runners import DataflowRunner BQ_BUCKET_NAME="dataflow-pubsub-to-bq" # # Set the Google Cloud region to run Dataflow. options.view_as(GoogleCloudOptions).region = 'us-central1' # Choose a Cloud Storage location. dataflow_gcs_location = 'gs://'+BQ_BUCKET_NAME+'/dataflow' options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location runner = DataflowRunner() runner.run_pipeline(p, options=options)
デプロイが完了するとJupyter Notebookのセルに下記のように表示されます。

g.テストデータのアップロード
デバイスからデータを送信します。
テストデータについては、1時間ごとの気象庁のホームページから過去のデータをダウンロードできます。
ここは大変お手数ですが、下記のようにフォーマットを変換してSORACOM FunkまたはBeamへ送信してください。
本ブログでは、気象データを1時間ごとに計測したものを利用致しますが、20秒ごとに送信する設定としています。
Window処理は、Dataflowで処理される時刻を元に実行されます。
そのため、Windowを1分ごとに処理することで、3時間分の気象データを纏めて処理する実装としております。
import urllib.request, json import random endpoint_beam_pubsub="http://beam.soracom.io:8888/" for index, row in df_weather.iterrows(): weather_json={ "simId":row["simId"], "location":row["location"], "latitude":row["latitude"], "longitude":row["longitude"], "createdAt": row["createdAt"].tz_convert('Europe/London').strftime("%Y-%m-%dT%H:%M:%S"), "temperature": row["temperature"], "precipitation": row["precipitation"], } body_json={ "messages": [ { "data": base64.b64encode(json.dumps(weather_json).encode("utf-8")).decode('ascii') } ] } print(weather_json) # { # "simId":"1111111111111111111", # "location":"tokyo", # "latitude":35.652832, # "longitude":139.839478, # "createdAt":"2022-12-31T16:00:00", # "temperature":3.5, # "precipitation":0.0 # } print(body_json) # { # "messages":[ # { # "data":"eyJzaW1JZCI6ICIxMTExMTExMTExMTExMTExMTExIiwgImxvY2F0aW9uIjogInRva3lvIiwgImxhdGl0dWRlIjogMzUuNjUyODMyLCAibG9uZ2l0dWRlIjogMTM5LjgzOTQ3OCwgImNyZWF0ZWRBdCI6ICIyMDIyLTEyLTMxVDE2OjAwOjAwIiwgInRlbXBlcmF0dXJlIjogMy41LCAicHJlY2lwaXRhdGlvbiI6IDAuMH0=" # } # ] # } headers = { "Content-Type" : "application/json" } method = "POST" json_data = json.dumps(body_json).encode("utf-8") request = urllib.request.Request(endpoint_beam_pubsub, data=json_data, method=method, headers=headers) try: with urllib.request.urlopen(request) as response: response_body = response.read().decode("utf-8") print("status") print(response.status) print(response_body) except urllib.error.HTTPError as err: print(err) print(response.read().decode("utf-8")) break; time.sleep(20)
h.BigQueryでのデータ確認
データ送信が成功していると、Cloud Pub/Subで受け、その後統計処理されたデータがGoogle BigQueryで確認できるようになります。
SELECT * FROM `soracom-blog-project-id.WEATHER.WEATHER_SUMMARY` LIMIT 1000

3.機械学習モデル構築 Google BigQuery → Google VertexAI
1.モデル構築
Big Query MLの機能を使って線形回帰モデルを構築します。
`as label`と着いている`TEMPERATURE_AVERAGE`が目的変数でそれ以外の変数が説明変数となります。
ここで、Optionsに`model_registry=”vertex_ai”, VERTEX_AI_MODEL_ID=”weather_model”`と指定することで Google VertexAIに`weather_model`という名前でモデルが登録されます。他のモデル学習やチューニングに関しては、「Google公式ドキュメント:BigQuery MLの概要」をご確認ください。
CREATE MODEL `WEATHER.weather_model_230530` OPTIONS(model_type='linear_reg', model_registry="vertex_ai", VERTEX_AI_MODEL_ID="weather_model") AS SELECT TEMPERATURE_AVERAGE as label, EXTRACT(MONTH FROM DATETIME(WINDOW_START_AT)) as hour, EXTRACT(DAY FROM DATETIME(WINDOW_START_AT)) as day, EXTRACT(HOUR FROM DATETIME(WINDOW_START_AT)) as month, LATITUDE as latitude, LONGITUDE as longitude FROM `soracom-support.WEATHER.WEATHER_SUMMARY`

4.機械学習モデルの推論実行SORACOM Funk → Google Cloud Functions → Google VertexAI
ここではデバイスから緯度軽度と日時情報を送信し、Google VersionAIにデプロイされた機械学習のモデルを呼び出す仕組みを構築します。
1.SORACOM FunkからGoogle Cloud Functions呼び出し
デバイスから送信したデータをGoogle Cloud Functionsへ連携する設定をします。
ユーザードキュメント「SORACOM Funk + Google Cloud Functions パターン」を参照して、Google Cloud Functionsの作成とSORACOM Funkの設定をしてください。ただし、ランタイムは次のステップに合わせてPythonで構築してください。
2.Google Cloud Functions
Google Cloud Functionsでは、デバイスから受け取った日時(UTC)と緯度軽度情報を受け取り機械学習のモデルで推論を実行します。推論実行で得た平均気温の予測結果をデバイス側で返します。
from typing import Dict, List, Union from flask import jsonify from datetime import datetime from google.cloud import aiplatform from google.protobuf import json_format from google.protobuf.struct_pb2 import Value def execute_prediction( project: str, endpoint_id: str, instances: Union[Dict, List[Dict]], location: str = "us-central1", api_endpoint: str = "us-central1-aiplatform.googleapis.com", ): """ `instances` can be either single instance of type dict or a list of instances. """ # The AI Platform services require regional API endpoints. client_options = {"api_endpoint": api_endpoint} # Initialize client that will be used to create and send requests. # This client only needs to be created once, and can be reused for multiple requests. client = aiplatform.gapic.PredictionServiceClient(client_options=client_options) # The format of each instance should conform to the deployed model's prediction input schema. instances = instances if type(instances) == list else [instances] instances = [ json_format.ParseDict(instance_dict, Value()) for instance_dict in instances ] parameters_dict = {} parameters = json_format.ParseDict(parameters_dict, Value()) endpoint = client.endpoint_path( project=project, location=location, endpoint=endpoint_id ) response = client.predict( endpoint=endpoint, instances=instances, parameters=parameters ) predictions = response.predictions return predictions def predict_temperature(request): request_json = request.get_json() print(request_json) target_datetime = datetime.fromisoformat(request_json['target_datetime']) hour=target_datetime.hour day=target_datetime.day month=target_datetime.month latitude=request_json['latitude'] longitude=request_json['longitude'] predictions = execute_prediction( project="705281794736", endpoint_id="264758001921949696", location="us-central1", instances=[{ "hour":hour,"day":day,"month":month,"latitude":latitude,"longitude":longitude}] ) result=[] for prediction in predictions: result.append({"prediction": prediction[0]}) return jsonify(result)
3.デバイスからの推論実行
少し早いですがここまで読んで頂いた方、ありがとうございます!
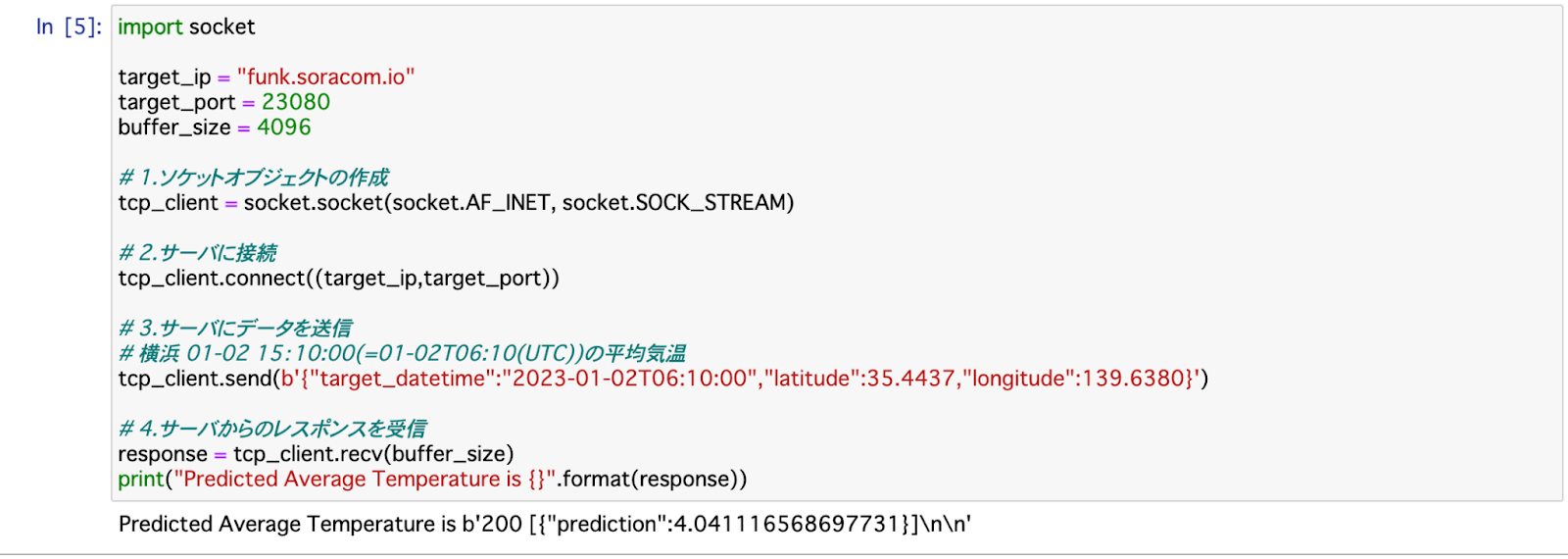
早速デバイスからデータを送って機械学習の推論をしてみましょう。例では、横浜の緯度軽度と時刻情報を送信し、推論を実行しています。
結果は下記の通り、 4.04度と予測ができました。
本ブログでは、モデルの精度などはあまり気にせず、デバイスから送信したデータを加工し格納、そして機械学習に再活用するデータの流れを重点的にご紹介しました。
精度に関しては、今回評価はしておりませんが東京と大阪だけのデータではデータ数も少なく良くない結果となるはずです。より他拠点でのデータやサンプル数を増やすことで精度向上は可能ですので、お客様のプロジェクトでは是非精度まで検証頂ければと思います。
import socket target_ip = "funk.soracom.io" target_port = 23080 buffer_size = 4096 # 1.ソケットオブジェクトの作成 tcp_client = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 2.サーバに接続 tcp_client.connect((target_ip,target_port)) # 3.サーバにデータを送信 # 横浜 01-02 15:10:00(=01-02T06:10(UTC))の平均気温 tcp_client.send(b'{"target_datetime":"2023-01-02T06:10:00","latitude":35.4437,"longitude":139.6380}') # 4.サーバからのレスポンスを受信 response = tcp_client.recv(buffer_size) print("Predicted Average Temperature is {}".format(response))
さいごに
いかがだったでしょうか?
非常に長くなりましたが、最後まで読んで頂いた方有難うございました!
ストリーム処理では、リアルタイムに特定の時間で分析を纏めて処理するWindow処理と統計処理を行う高度な処理ができました。リアルタイム分析をせずに、一度データベースに格納し分析する手法も多く採用されることもありますが、よりリアルタイムに分析を提供できる仕組みをご紹介致しました。
機械学習では、Google BigQuery MLを利用してSQLだけで機械学習モデルを構築しているのがポイントです。より高度な機械学習ではAutoMLやカスタムでVertexAIを使ってモデルを構築する方法もありますので、必要に応じてチャレンジしてください。
― ソラコム松永(taketo)
投稿 Google CloudとSORACOMでリアルタイム分析とAI・機械学習 は SORACOM公式ブログ に最初に表示されました。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第628回
デジタル
【SORACOM Discovery 2026】展示ブース紹介 第3弾:シルバースポンサー / ニューフェイススポンサー(ソリューション / サービス / インテグレーション編) -
第627回
デジタル
【SORACOM Discovery 2026】展示ブース紹介 第2弾:シルバースポンサー / ニューフェイススポンサー(デバイス/ソリューション編) -
第626回
デジタル
【SORACOM Discovery 2026】問い合わせ対応をAIでどう自動化・効率化する? LINE連携の成功事例セッション & 会場で試せる最新デモの見どころ -
第625回
デジタル
IoT活用支援の優秀企業を表彰する 「SPSアワード 2025」を発表 -
第624回
デジタル
【SORACOM Discovery 2026】展示ブース紹介 第1弾:プラチナ・ゴールドスポンサー編 -
第623回
デジタル
VPG トラフィックフィルタリング提供開始、SORACOM Flux が複数画像送信に対応、他 ほぼ週刊ソラコム 05/30-06/19 -
第622回
デジタル
現場DXの突破口はここに。SORACOM Discovery 2026 注目セッション&展示 -
第621回
デジタル
初めての SORACOM Discovery:効率的な事前準備と会場の回り方 -
第620回
デジタル
在庫の減りも、設備の異変も見逃さない! SORACOM Flux が複数画像入力に対応 -
第619回
デジタル
【SORACOM Discovery 2026】事業企画・サービス開発者必見!「組み込みIoT」で現場の課題を解決する事例とセッションのご紹介