



クラシルのデータエンジニアもゲスト出席、パーソナライズレコメンドへの適用事例を解説
Snowflake、データ基盤に統合された開発基盤「Snowpark」のメリットを紹介
2023年04月19日 07時00分更新

Snowflakeは2023年4月18日、開発者向けフレームワーク「Snowpark(スノーパーク)」の技術や実際の利用事例を紹介する記者説明会を開催した。ゲストスピーカーとして、レシピ動画プラットフォーム「クラシル」を提供するdelyのデータエンジニア、harry氏も出席し、提供サービスの拡大を目指すなかでSnowparkを導入した効果を語った。
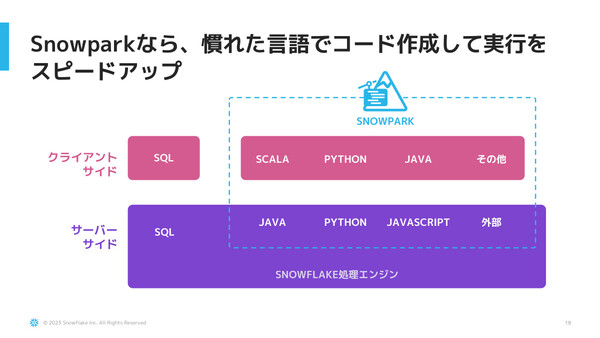
Snowparkは、Snowflakeデータクラウド上の開発フレームワーク。現在はPython、Scala、Javaなどに対応している


Snowflake マーケティング本部 シニアプロダクトマーケティングマネージャー兼エヴァンジェリストのKT氏、dely(デリー) 開発BU クラシル開発部 バックエンドエンジニアリング S Data チーム データエンジニアのharry(ハリー)氏
Snowpark:プラットフォームに統合された多言語のアプリ開発基盤
Snowparkは、Snowflakeのデータプラットフォームに統合された開発フレームワークだ。現在はPython、Java、Scalaに対応しており、Snowflakeに格納された大量のデータを、開発者が使い慣れた言語を使って容易に処理することができる。
Snowflake エヴァンジェリストのKT氏は、Snowparkを利用するメリットとして「言語の選択が可能」「ガバナンスのトレードオフなし」「パイプラインの迅速化とコスト削減」という3点を挙げた。
「言語としてはPython、Java、Scala、SQLにネイティブ対応しており、プログラムを書ける方ならばどれか(言語)は使えるだろうというバリエーションだ。またデータをほかの環境に移動させることなく、Snowflakeの単一プラットフォーム上で処理し、監視できるので、データを自由に使いながらもガバナンスがトレードオフになることがない。さらにデータの移動やコピーが発生しないので、データパイプラインが短くなり、パイプライン構築も実際の処理も時間とコストが削減できる」(KT氏)

Snowparkを使うメリットとして大きく3つを挙げる
KT氏は特に、昨年11月に「Snowpark for Python」の一般提供が開始され、Pythonにも対応した点を強調した。「Pythonは近年、大学の授業でも扱われており、ユーザー数の多い言語」(KT氏)であることから、SnowparkでPythonが使えるようになった影響は大きいと考えている。
Snowpark for Pythonは、「クライアントAPI」「UDF(ユーザー定義関数)」「ストアドプロシージャ」という3つのアクセス方法に対応している。使い慣れたPython構文でデータを扱えること、データサイエンス環境の「Anaconda」をはじめとする豊富なパッケージが用意されていること、データを外部環境に出すことなく安全に処理できることをメリットに挙げた。
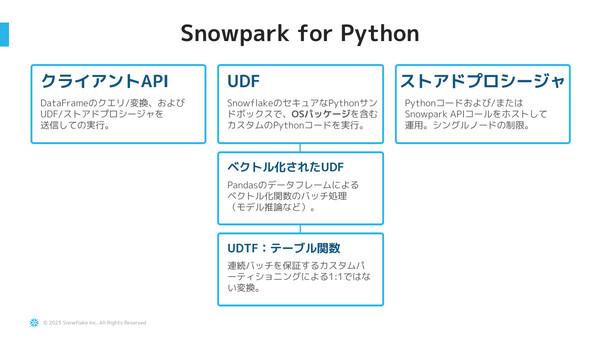
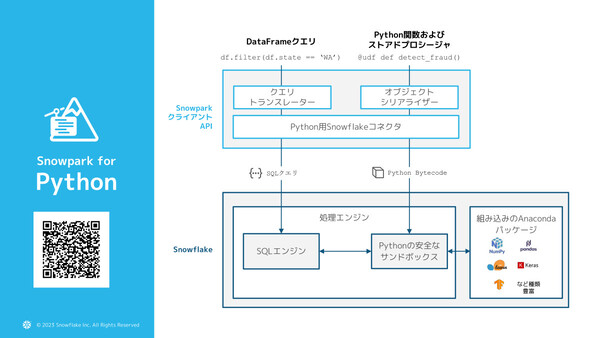
「Snowpark for Python」の概要
SnowparkにはあらかじめAnaconda環境(キュレーション済みのPythonパッケージ)も組み込まれている。さらに、ユーザーのローカル環境にもリポジトリから同じパッケージをインストールして開発できる。「統一された環境なので、パッケージのバージョンが違うなどのズレが起こらず、Snowflake環境への展開が簡単にできる。組織内での(複数開発者の)コラボレーションも容易になる」(KT氏)メリットがあるという。Snowflakeでは今後もより多くのライブラリを継続的に導入していくとした。
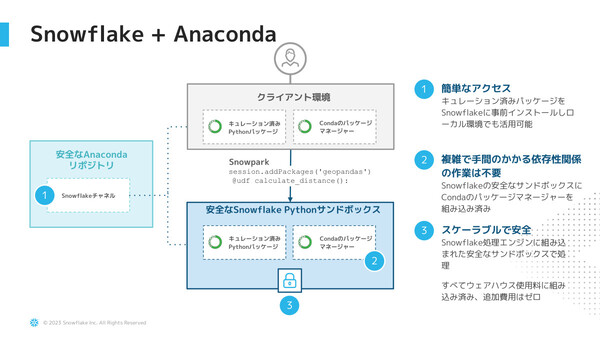

同一のAnaconda環境をSnowflake/ローカル環境に用意できるので、パッケージの違いなどの齟齬が発生せず、開発と展開が容易に行える
KT氏は、Snowparkの国内導入事例を2社、紹介した。
製薬会社の小野薬品工業では、Python人材の育成に取り組んでおり、そのスキルがそのままSnowflakeの実務に生かせるという理由からSnowparkを採用した。同社では機密度の高いデータも扱うが、それをローカル環境にダウンロードすることなく処理できる点、テラバイト級の巨大なデータも瞬時に扱える点も評価している。現在はAI/機械学習処理の開発において活用しており、今後その他の領域への展開も検討しているという。
文章や画像、映像などの投稿プラットフォームを運営するnoteでも、Snowparkを採用している。これまでは、「Amazon RDS」からのテーブルの同期、中間テーブルの作成、複雑な中間テーブルの作成といった作業に大きな時間がかかっていたが、Snowparkによって一連のデータ処理をプログラム化することができ、「数日かかっていた処理が数分、数秒レベルに」(KT氏)時間短縮されたという。
クラシル:パーソナライズレコメンドの実現に向けSnowparkを活用
delyのharry氏は、クラシルのデータ基盤構築やパーソナライズレコメンド(ユーザー個々人の好みに応じたコンテンツの推奨)エンジン関連の開発を手がけるデータエンジニアだ。2022年、2023年の「Snowflake Data Superheroes」にも選ばれている。
クラシルは、レシピ動画プラットフォームとして多数のユーザーを集めるサービスだ
クラシルはこれまで、1分間程度の短いレシピ動画コンテンツを提供するサービスを中心に拡大してきた。そして今後はさらにサービスを強化し、「コンテンツのパーソナライズや、ユーザー投稿コンテンツの紹介などにも力を入れていこうと考えている」とharry氏は説明する。
「これまでは、たとえば『時短』や『節約』といったキーワードで検索をかけて、コンテンツを見ていただくかたちだった。ただし、ユーザーの食に対するニーズというのは、たとえば『子育て家庭』『糖質制限』『ベジタリアン』などもっと多様性があるはずだ。そうしたニーズに対して、レコメンデーションの力を使ってコンテンツを提供することで、ユーザーがよりクラシルを使っていただけるのではないかと考えている」(harry氏)

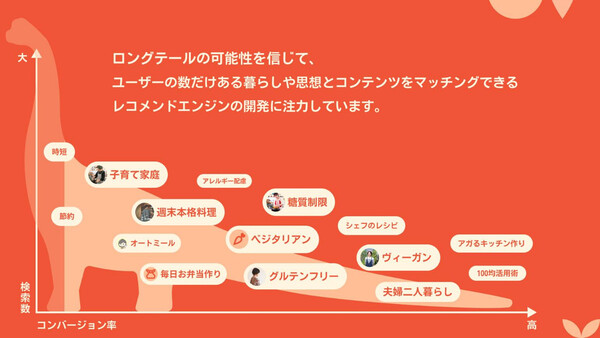
利用者のさらなる拡大に向けてレコメンドエンジン開発に取り組んでいる
ユーザーへのレコメンデーションを実現するためには膨大なデータが必要になる。そうした背景もあって、クラシルでは2021年10月からSnowflakeの本格利用を開始した。データ基盤の刷新を終え、ユーザー行動ログのリアルタイムパイプラインを構築して、そのデータ分析(BI)も始めたが、レコメンデーションの実現など今後の取り組みや利用拡大を考えると、課題もあったという。
「レコメンデーションにはできるだけリアルタイム性があったほうが価値が高まる。そのためにはデータを出し入れする(外部に移動する)ことを極力なくしたい。また、当時はML(機械学習)エンジニアが社内におらず、機械学習についてチームで学んでいくフェーズだったので、MLエンジニア以外でも環境構築ができることがすごく大事だった。さらに、外部にもうひとつML基盤を構築するよりも、スモールスタートをしていきたいという思いもあった」(harry氏)
こうした要件に基づき、クラシルでは、Snowflakeのデータプラットフォームをそのまま活用できるSnowparkを採用することにした。すでに開発していたデータパイプラインで取り込まれたユーザーのリアルタイム行動ログに、Snowpark for Pythonを使って新たに開発した機械学習処理(学習、推論)を組み合わせ、レコメンデーションエンジンを構成している。
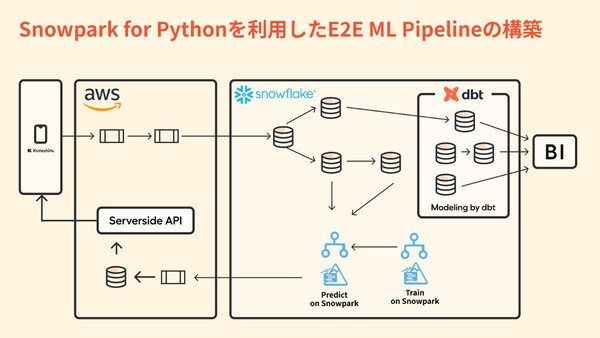
クラシルがSnowpark for Pythonで開発した機械学習パイプライン
harry氏はSnowparkを導入した効果について、「既存のデータパイプラインの延長線上でレコメンデーションが実現可能になった」「外部へのデータ移動がないためコストメリットが高い」「データ(ログ)入力から学習、推論、アプリへ結果を返す処理までをイベントドリブンに実現できた」「今後、さらに大規模な学習処理を行うことになっても、コンピューティングリソースの選択肢がある」などを挙げた。
「Snowflakeのコスト管理などについては、すでにある程度経験があった。MLパイプラインを作るにあたっても、そのコスト感覚やチューニングの感覚、性能の感覚がわかっており、なおかつSnowflakeを見ておけば一元的に管理できるというのはすごく楽だった。データエンジニアとしては、タスクが正しく動いているか、コストがちゃんと見合っているかというところだけを見ておけばよい。うまくマネージドされた状態でSnowparkを使えたのは、とても良かった」(harry氏)
最後にharry氏は、今後のSnowparkに期待する機能拡充として「Streamlitへの対応」「Pythonワークシートへの対応」を挙げた。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



