




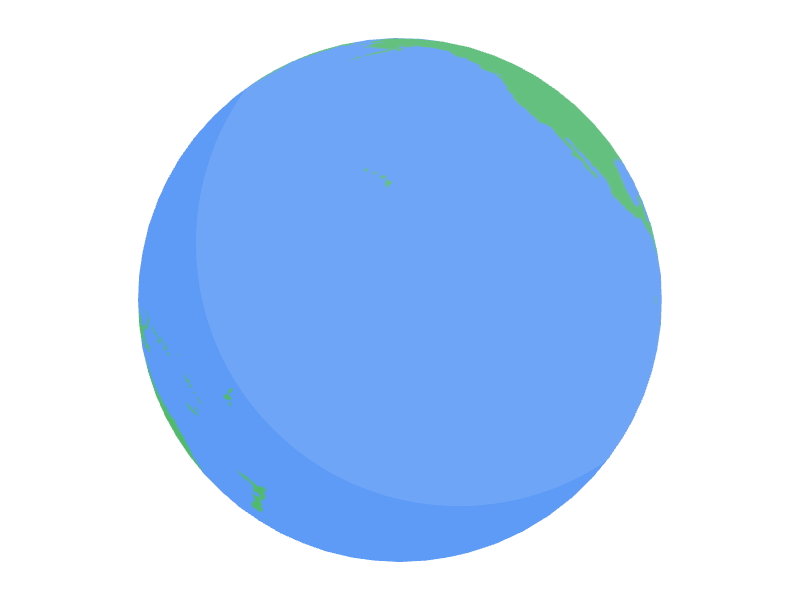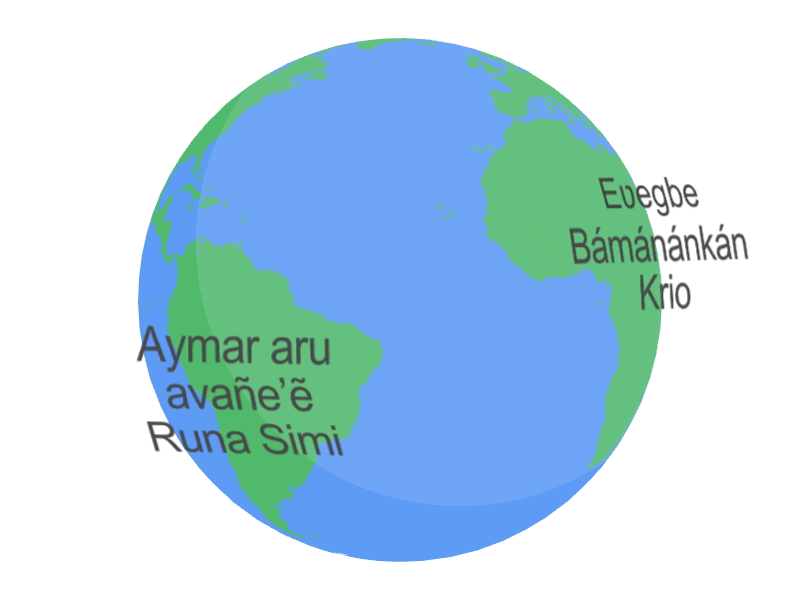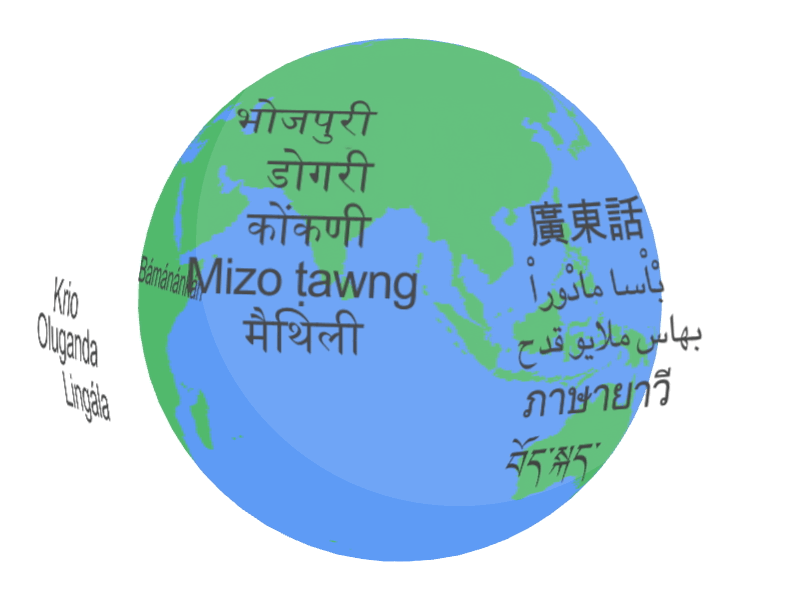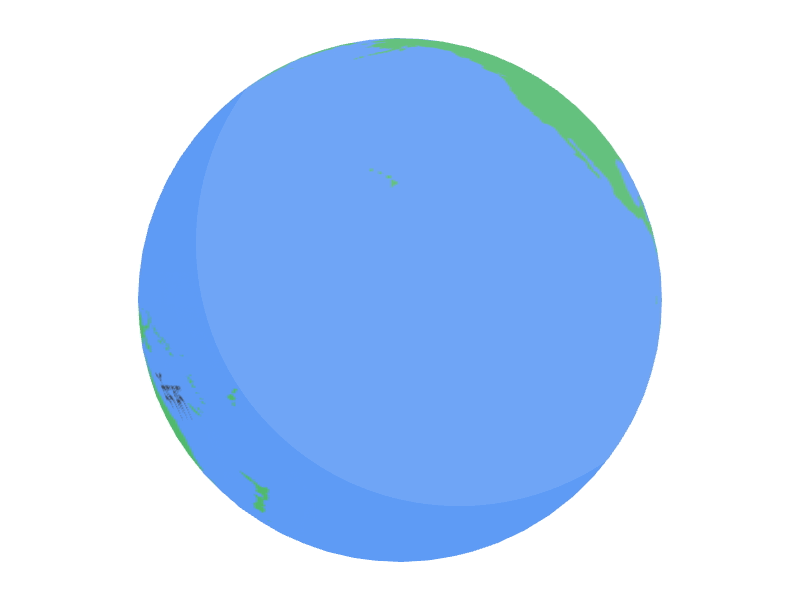
グーグルは3月6日(現地時間)、300を超える言語にまたがる1200万時間の音声データと280億のテキストデータで訓練された自動音声認識モデル「Universal Speech Model(USM)」を発表、YouTubeの字幕生成に活用されるほか、研究者向けにAPIも公開されている。
USMは英語や北京語など広く話されている言語だけでなく、アムハラ語(エチオピア)、セブアノ語(フィリピン)、アッサム語(インド北東部)、アゼルバイジャン語など比較的話者の少ない言語についても自動音声認識(ASR)が可能となっている。
現在のASRにおける課題
ASR開発においては、音声データとそれに対応するラベルと呼ばれるテキストデータを対にした大量のデータセットを用いて学習させる「教師あり学習」と呼ばれる機械学習の手法が主流となっている。
だが、英語や中国語などサンプルとなるソースの多い言語と異なり、話者の少ない言語はそもそもサンプルとなる音声データが少ないうえに、手作業でラベルを付加(ラベリング)する必要もあるため時間とコストがかかるという課題がある。
グーグルは2021年11月に公開した記事「3 ways AI is scaling helpful technologies worldwide」の中で、世界で話されている上位1000言語をサポートする機械学習(ML)モデルを構築する「1000 Languages Initiative」という目標を発表している。
だが、これらの言語の中には話者数が比較的少ないものも多く含まれており、利用可能なデータが限られている言語をどのようにサポートするかが中心的な課題となっていた。
また、言語のカバー範囲と品質を拡大する一方で、マシンリソースとの兼ねあいから計算効率が高い方法でモデルを改善する必要もあるため、学習アルゴリズムが柔軟で効率的かつ一般化可能であることも重要となるという。
3ステップからなる「微調整を伴う自己教師あり学習」を採用
そこでUSMでは「教師あり学習」に代わり主に「自己教師あり学習」という手法を採用している。
「自己教師あり学習」は音声に対応したラベルが必要な「教師あり学習」と違い、データ自身から独自のラベルを機械的に作り、それをもとにタスクをするため、ラベル付きデータセットを必要としないという特徴がある。
USMはラベルのない大規模な多言語データセットを利用して「自己教師あり学習」による事前学習を行ない、その後に少量のラベル付きデータセットで微調整を行うことで、十分に普及していない言語を認識できることを実証した。この方式は「微調整を伴う自己教師あり学習」と表現されている。
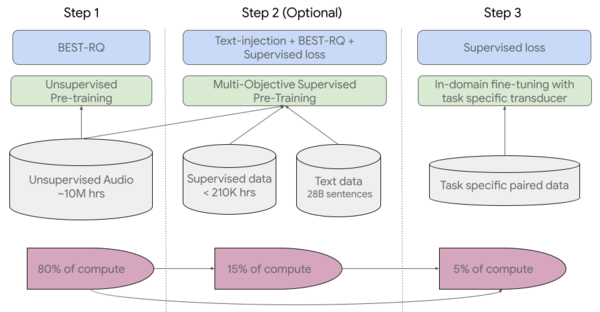
「微調整を伴う自己教師あり学習」は3つのステップで構成されている。
第1ステップでは、実績のある「BEST-RQ」モデルを使用して、300以上の言語を含むラベルのない大量の音声データから「自己教師あり学習」を行なう。作業的にはこのステップが全体の80%を占める。
ラベル付きの音声データがある場合は、第2ステップで「教師あり学習」を用い追加の知識を取り込む。なお、このステップは省略できる。
そして第3ステップでは実際に使用する環境(ここではYouTube字幕)にあわせた少量のラベル付きデータを用いて、微調整をする。
誤答率はOpenAIのWhisperを下回る結果に
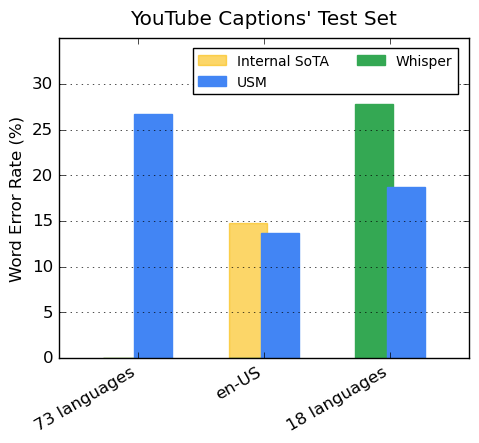
上記のステップを経てトレーニングされたUSMを、Youtubeの字幕データ(73言語)でテストしたところ、73言語の平均単語誤答率(WER)30%以下を達成したという。
また、アメリカ英語に限れば自社のこれまでの記録よりも6%低い誤答率を、さらにOpenAIが提供する40万時間以上のラベル付きデータで学習された「Whisper」と比較して平均で32.7%相対的にWERが低いという結果を示した。
グーグルは「世界の情報を整理し、誰でもアクセスできるようにする」というミッションを掲げており、1000言語という目標に到達するための基盤技術としてUSMは位置付けられている。



















の1台が今ならオトク!")

























")













