




1152個のMAC演算を一発で行なうSIMD方式
まず基本的な構造を説明したい。ここから説明する構造は、2021年のISSCCの論文をベースとしたものなので、実際にEnCharge AIが開発しているチップとはディテールが多少異なるかもしれないが、基本的な仕組みは変わらないと考えられる。
下の画像がチップ全体の構造である。2021年にも試作チップが紹介されているが、これはCIMA(Compute-In-Memory Array)が16個の構成である。
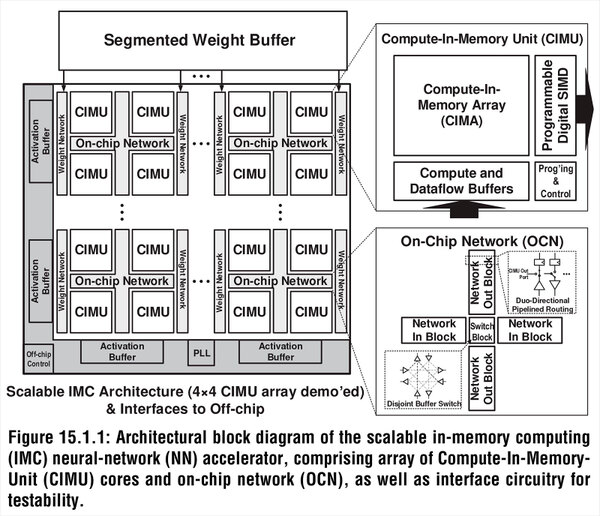
論文にも、この4つのCIMUの塊同士をどう接続するのか、の説明がなかった。実際にはOCNはこの2×2のCIMUだけを接続するのではなく、メッシュ式にすべてのCIMUを縦横でつなぐ(Xeon Scalableのアレである)方式なのかもしれない。そう考えた方が辻褄が合う
この16個が4つづつの組になっており、それぞれに重みデータロード用のネットワークI/Fが搭載される。また4つのCIMUは、オンチップ・ネットワークで接続される形になっている。
おのおののCIMUの中核はアナログベースのCIMUであるが、データを格納するためのバッファ、それと畳み込み演算の後のアクティベーションなどを行なうためのSIMDエンジンが組み合わされた格好になっている。アナログベースで計算しても、どこかでデジタルに変換する必要はあるわけで、それも含めてProgrammable Digital SIMDを搭載した格好だろう。
また、おもしろいのは重みに関してはローカルにバッファーを持たず、CIMUアレイの外にSRAMを用意。個々のCIMUにはその重みにアクセスするためのネットワークだけを搭載していることだ。
さてその核となるCIMAであるが、実に1152行×256列もの膨大な数の演算コアである。それぞれの演算コアは記憶を担うCL(要するにコンデンサー)と、これをアクセスするためのロジック(W/WB)から構成される。1152行ということは最大で1152個のMAC演算が一発で行なえるわけだ。
余談だが試作プロセッサーは5mm角で、そこにCIMUが16個収まっている。大雑把に言えばこのCIMUは1個あたり1mm角程度であり、そこに29万4912個のMAC演算ユニットとメモリーが収まる計算になる。つまりメモリー&演算ユニット1つあたり、3.4μm2程度に収まる計算である。
ちなみに製造プロセスはTSMCの16nmであり、TSMCの発表では16FFのSRAMセルサイズは0.07μm2と以前に発表があった。この0.07μm2は1bit分のサイズなので、8bit分だではそれだけで0.56μm2。ここにMAC演算ユニットを追加したら、3μm2前後になるわけで、現状はSRAMベースのCIMと同程度の効率でしかないが、これは研究用ということも考えれば十分だろう。
さてここからが肝心な部分だ。MythicやSyntiantは、記憶素子にNORフラッシュを利用した。要するにFloating Gate Flashであるがフラッシュメモリーは基本的にシリコンの上に酸化膜で挟み込む形でフローティングゲートと呼ばれる電荷を保持する領域を構築している(詳細は連載259回参照)。
ただこれはトランジスタなどと同じ仕組みなので、原理的にそれほど電荷の容量を大きくできない(トランジスタ層だから、高さを稼ぐのが難しい)という欠点がどうしても存在する。
その容量が大きくできないところにいろいろ工夫をして無理やり電荷を詰め込むわけだから、当然無理が出てくる。そもそもフラッシュの場合動作温度の変動などに敏感であり、常時監視をしてパラメーターを調整したり、場合によっては再キャリブレーションをする必要がある。
この技術そのものフラッシュメモリーでは一般的なのだが、この監視や調整/再キャリブレーションといった処理は当然デジタル的に行なうわけで、結果アナログ→デジタル→アナログの制御ループを積み重ねることになるので、無駄が多い。
もちろんフラッシュメモリーのように大容量の記憶セルを扱うのであれば、こうした監視/制御のためのロジックは相対的に小さくなるから無視できる範囲なのだが、CIMに使うにはバカにできない。
EnCharge AIではフラッシュの代わりに、配線層を利用してコンデンサーを構築し、ここに電荷を貯めるという形で問題を解決した。要は配線層は背も高いし面積も広くとれるので、大容量のコンデンサーを構築しやすい。これの極端な例が、インテルが10nm SuperFinで導入したSuper MIMである。SuperMIMは連載576回で説明したが、配線層の比較的上層に大容量コンデンサーを構築し、これをパスコンとして使うというものである。
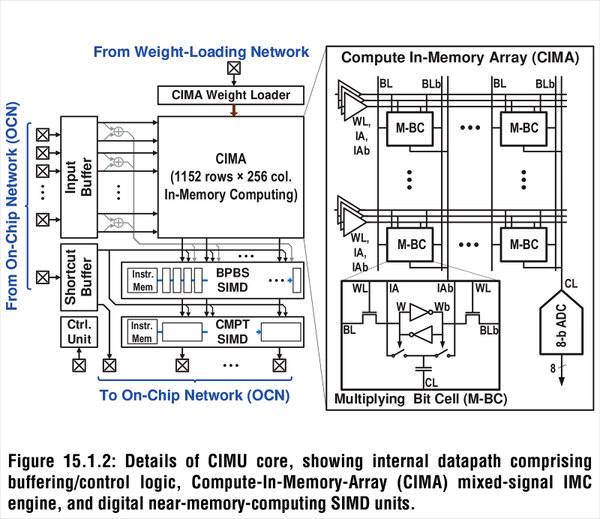
各セルにはデータ量に応じた電荷を蓄えてあり、するとMythicの時の原理と同じように個々のキャパシタで乗算が行なわれ、最終的な加算は縦の列の電流の合計という形で行なわれる仕組みである
EnCharge AIはもう少し配線層の下層にコンデンサーを構築するもので、容量もSuperMIMに比べればずっと小さいが、それでもフローティングゲートに比べれば非常に大きな容量を稼げる。
そして容量が大きいということはSN比(信号/ノイズ比)を大きくできるということで、精度を上げる(≒データを多値化する)ことも難しくないし、補正やキャリブレーションの頻度も大幅に減らせる(=こうした回路の規模を小さくできる)ことになる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























