

本記事はFIXERが提供する「cloud.config Tech Blog」に掲載された「SQL Serverで特定のSQLクエリのパフォーマンスチューニングをする方法」を再編集したものです。
こんにちは、あおいです。
一番好きな証券会社は「野菜證券」です。
さて、特定のSQLクエリがボトルネックとなった結果、システム全体のパフォーマンス劣化に影響する可能性は十分にあります。そのような場合は個別最適なチューニングが必要です。
そこで、今回はSQL Serverで、特定のSQLクエリのパフォーマンスチューニングをする方法について紹介したいと思います。
特定クエリのチューニングの流れ
基本的なチューニングの流れは以下の通りです。
1. チューニング対象のSQLクエリを決める
2. 指標を計測する
3. 検索述語の選択率を確認する
4. SQLクエリの修正・インデックスの作成をする
5. 再度、指標を計測する
実際にチューニングをしてみる
例)5万レコードのデータがある社員テーブルから、特定の行を取得したいが、検索速度が遅い。
1. チューニング対象のSQLクエリを決める
今回は以下のSQLクエリとします。
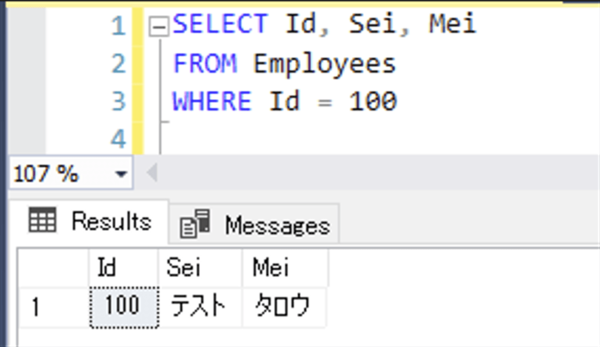
2. set statistics time on を実行して指標を計測する
set statistics time on を実行して「実行時間」と「CPU使用時間」の評価指標を計測します。
・ユーザーの待機時間に直結する「実行時間」
・サーバー負荷に直結する「CPU使用時間」
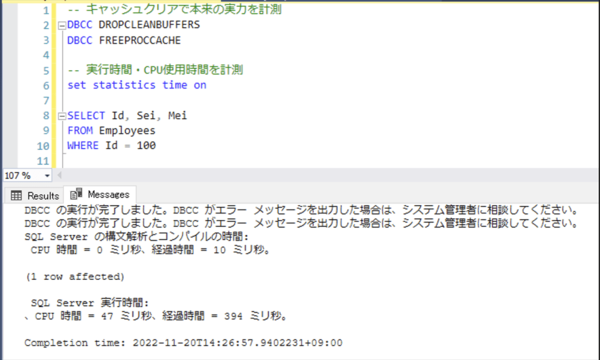
また、本来の実力を計測するためにキャッシュクリアをします。
-- キャッシュクリアで本来の実力を計測
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE
-- 実行時間・CPU使用時間を計測
set statistics time on
「実行時間」と「CPU使用時間」はMessagesタブに表示されます。
計測結果として、実行時間394ミリ秒・CPU使用時間47ミリ秒となっています。
3. 検索述語の選択率を確認する
選択率とは、検索述語(=where句に指定しているキー)によって行がどれだけ絞り込めるかの指標です。
要は、値のばらつきが大きければ、少ないレコードに絞り込めるので、インデックスを作成することでI/Oコストを大幅に削減することが出来ます。これが選択性が良いということです。
例を挙げると、メールアドレスを検索述語に指定した場合、何万・何百万レコードあったとしても、一意の値なのでインデックスの効果を発揮することができます。しかし、性別などの値のばらつきが小さいカラムを検索述語に指定しても、インデックスの効果は得られません。
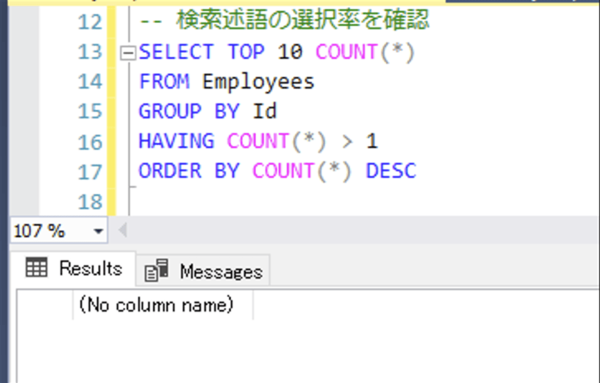
以下のクエリを実行すると、検索述語にしているカラムの値の重複をチェックします。 値の重複がゼロもしくは少ない場合、選択性が良い検索述語となります。
SELECT TOP 10 COUNT(*)
FROM [テーブル名]
GROUP BY [検索述語のカラム]
HAVING COUNT(*) > 1
ORDER BY COUNT(*) DESC
クエリの結果として、値の重複がゼロであることから、Idカラムは選択性が良い検索述語となります。
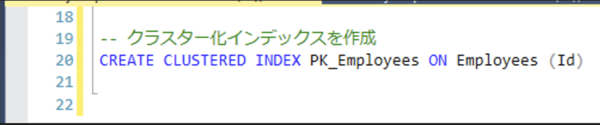
4. SQLクエリの修正・インデックスの作成をする
選択性の良い検索述語に対して、クラスター化インデックスを作成します。
5. set statistics time on を実行して、SQLクエリを再度実行する
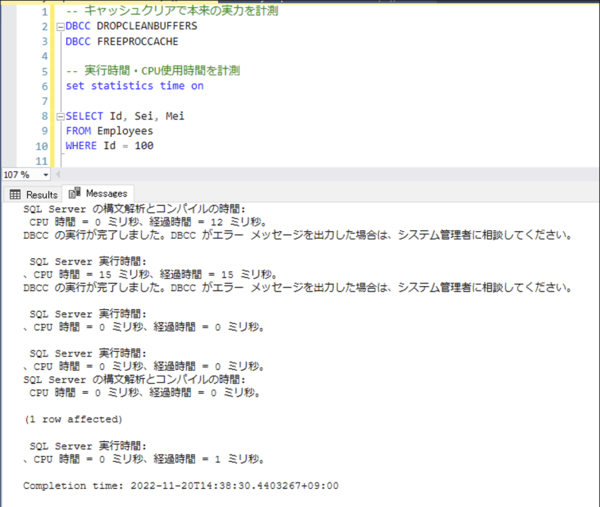
(1 row affected) 後の「実行時間」「CPU使用時間」に着目すると、それぞれ大幅に削減されています。
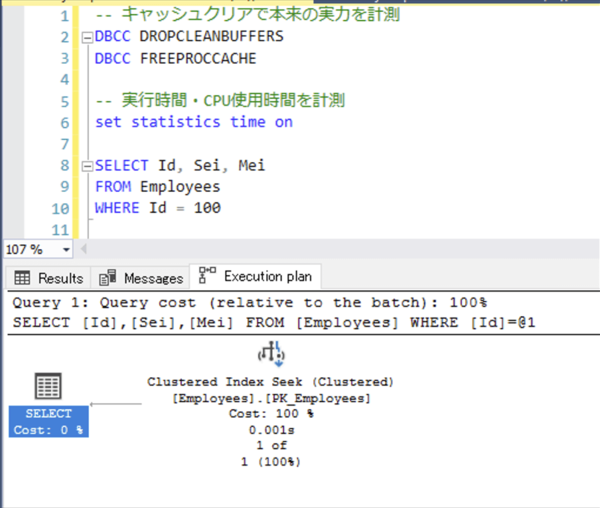
また、実行プランを確認すると、Index Seek になっています。
sys.dm_exec_query_stats とは
基本的には上記の手順でチューニングをしますが、sys.dm_exec_query_statsを流して計測する方法もあります。キャッシュされた(過去に実行された)クエリのパフォーマンス統計を取得するものです。
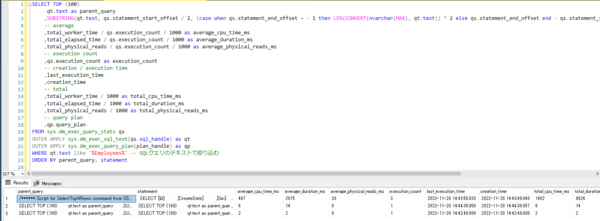
以下のクエリを実行すると、現在サーバーにキャッシュされているクエリのパフォーマンス統計を取得することができます。例えば、平均CPU使用時間や平均実行時間、実行回数、クエリプランなど。
SELECT TOP (100)
qt.text as parent_query
,SUBSTRING(qt.text, qs.statement_start_offset / 2, (case when qs.statement_end_offset = - 1 then LEN(CONVERT(nvarchar(MAX), qt.text)) * 2 else qs.statement_end_offset end - qs.statement_start_offset) / 2) as statement
-- average
,total_worker_time / qs.execution_count / 1000 as average_cpu_time_ms
,total_elapsed_time / qs.execution_count / 1000 as average_duration_ms
,total_physical_reads / qs.execution_count / 1000 as average_physical_reads_ms
-- execution count
,qs.execution_count as execution_count
-- creation / execution time
,last_execution_time
,creation_time
-- total
,total_worker_time / 1000 as total_cpu_time_ms
,total_elapsed_time / 1000 as total_duration_ms
,total_physical_reads / 1000 as total_physical_reads_ms
-- query plan
,qp.query_plan
FROM sys.dm_exec_query_stats qs
OUTER APPLY sys.dm_exec_sql_text(qs.sql_handle) as qt
OUTER APPLY sys.dm_exec_query_plan(plan_handle) as qp
WHERE qt.text like '%%' -- SQLクエリのテキストで絞り込む
ORDER BY parent_query, statement
つまり、sys.dm_exec_query_statsのクエリは、アプリケーションを本番環境にリリースした後、クエリのパフォーマンス統計を取得するのに便利な機能です。
仮に、アプリケーションの処理性能が低下した際に、原因のSQLクエリがどれかある程度検討が付いていると、上記のSQLクエリのテキストをLIKE句で絞り込むことで、そのクエリの平均実行時間やCPU使用時間を明らかにすることが出来ます。
2つの計測方法の使い分けとして、set statistics time onはアプリ開発時に手動で実行して性能測定を検証し、sys.dm_exec_query_statsはリリース後の本番環境で実行して性能測定をするようにします。
I/O推定コストとは
また、「I/O推定コスト」に注目してチューニングをする場合もあるかと思いますが、こちらの評価指標は注意が必要です。
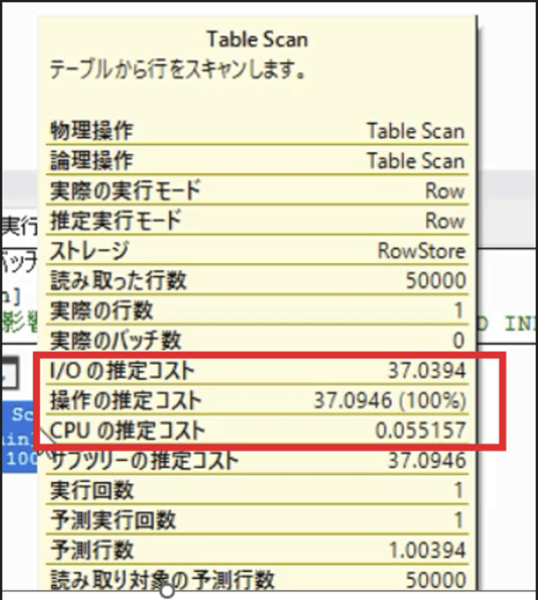
推定コストは、ある特定の条件の端末(使用端末に似通ったスペックだが、端末の情報が100%取得できるわけではないので、あくまでも推定の条件)でクエリを実行した場合に想定される実行時間を意味しています。
したがって、必ずしも「I/O推定コスト」の低い実行プランが処理時間が短いとは限りません。
本番サーバーと同スペックの実行端末を開発段階で準備するのは難しい場合もあるので、開発時のスペックに関しては保証する必要のある最低限のスペックで検証すれば良さそうです。
今回はSQL Serverで特定のSQLクエリのパフォーマンスチューニングをする方法について紹介させていただきました。本記事が少しでも読者の皆様のお役に立てれば幸いです。
あおい/FIXER
「初心者の方にも分かりやすく」をモットーにブログ執筆。TWICEミナペン。普段はC#とSQL Server、たまにPower Platformを触ってます。書籍『Microsoft Power Platformローコード開発[活用]入門 - 現場で使える業務アプリのレシピ集』
本記事はアフィリエイトプログラムによる収益を得ている場合があります




