




GAUDI 2は管理維持の経費削減に効果大
今年5月に行なわれたIntel Vision 2022で、インテルはGAUDI 2を初公開した。といっても詳細はあまり明らかになっておらず、唯一示されたのはNVIDIAのA100と比較して約2倍のスループットを実現できるということだけだった。

GAUDI 2のOAMを示すSandra L. Rivera氏(EVP&GM, Datacenter and AI Group)
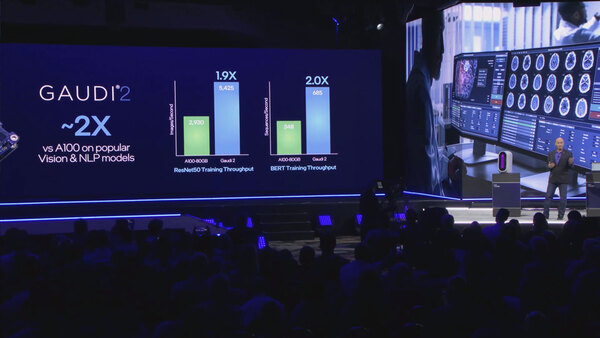
比較はNVIDIAのA100なのだが、問題はすでにA100の3倍高速なH100が発表されていることである
A100の2倍というのは新製品としては全然十分ではない(H100の3分の2の性能ということになる)わけだが、ここでHabana Labsはおもしろい見解を出してきた。
昨今のデータセンターでは、ディープラーニングに要するコストがどんどん上がっているとする。理由はより複雑なモデルと繰り返し回数の増加、アプリケーション利用の広がりなどだ。

単に性能を上げるだけでは不十分で、例えば最後の“rebuild daily or hourly”(ネットワークの組み換えやアプリケーションの変更を毎日あるいは毎時行なう)が26%もあると、これに要する手間とコスト(特に人手)がバカにならない
ところが、GAUDI 2はディープラーニングに要するコストの削減に大きな効果がある、というのがHabana Labsの主張である。要するに絶対性能だけでなく、TCOの削減に効果が大きいとしたわけだ。

動作周波数そのものは発表されていないが、同一周波数ではTPCの数が3倍+FP8のサポートで、ピーク性能は6倍くらいに引きあがっていそうである
GAUDI 2そのものはプロセスの微細化と処理エンジン強化(3倍)、メモリーの容量増加と高速化、ネットワーク強化(100G×10→100G×24)と、猛烈に内部構造を強化したGAUDIといった形になっている。その内部構造が下の画像だ。

GAUDI 2の内部構造。Media Engineを利用することで、静止画や動画をCPUの介在なく直接取り込んで処理が可能になる(GAUDIではCPUで展開してビットマップの形で送り込んでやる必要があった)
TPC(Tensor Processing Cores)が3倍に増やされた以外に、新たにMME(Matrix Multiplication Engine)が2つ追加されている。またHEVC/H.264/VP9/JPEGなどのデコードが可能なMedia Engineも新たに追加された。
ちなみに図には出ていないが、初代GAUDIでは24MBの共有SRAMが搭載されており、これを利用して送受信やTPC間でのデータ共有などを行なっていたが、GAUDI 2ではこれも48MBに増やされている。
GAUDI2が他のAIアクセラレーターと異なることの1つは、マルチチップ構成でのインターコネクトである。制御そのものはホスト(Ice Lake-SPサーバーをここでは念頭に置いている)からPCIeレーンでつながるが、カード同士は100GbEで接続する、という独特の構成である。
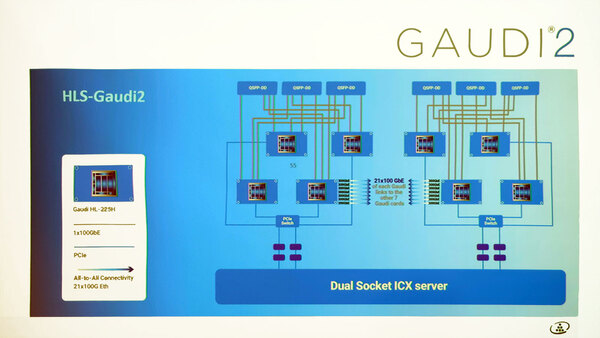
相互接続用の21本の100GbE上のプロトコルは未公開である。少なくともTCP/IPではないだろう
なにせ1つのGAUDIから24本の100GbEが取り出せるので、そのうち3本はネットワーク接続用に回すとして、残り21本は丸々余っている。これを300GbE×7構成にして、GAUDI 2同士の相互接続に使う、という構成である。下手な独自インターコネクトを作るより、100GbEを流用した方が効率的と考えたのだろう。
さてGAUDI 2の性能であるが、これはIntel Innovationで示されたものと大差ない。
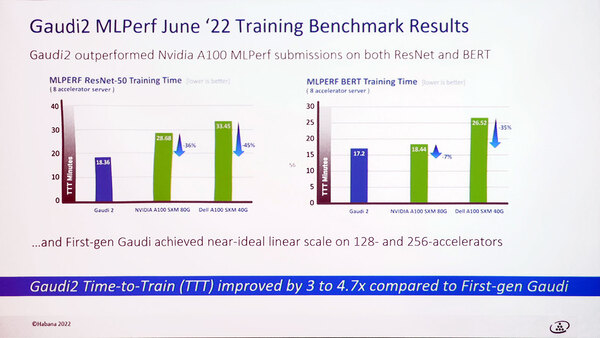
Intel Innovationではスループット(Images/sec)で示されていたが、今回はTraining Timeそのものを示している
今回新たに示されたのはスケーラビリティーで、複数枚のカード(初代GAUDIを含む)を利用したケースで、枚数に応じてリニアに性能が増えるとしている。
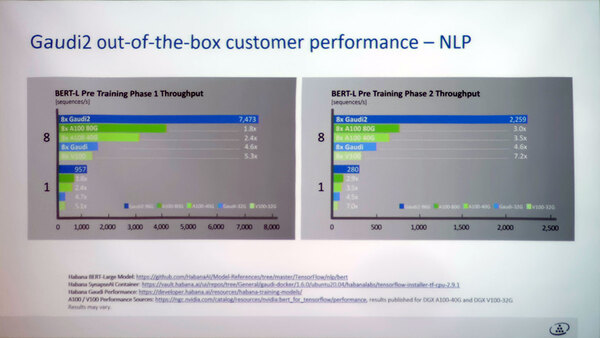
もっとも8枚くらいの範囲で言えばNVIDIAの製品もやはりリニアに増えるので、ここで大きな差はないのだが。初代GAUDIは128/256個までほぼリニアとあったが、GAUDI 2はどうなのだろう?
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ




































ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












