



ロードマップでわかる!当世プロセッサー事情 第682回
Meteor Lakeの性能向上に大きく貢献した3D積層技術Foverosの正体 インテル CPUロードマップ
2022年08月29日 12時00分更新

米国時間の8月21日から23日まで開催されたHotChips 34で、インテルは今回も活発な発表を行なった。具体的には以下の4つの発表である。
- Intel's Ponte Vecchio GPU: Architecture, System and Software
- Heterogenous Integration Enables FPGA Based Hardware Acceleration for RF Applications
- Meteor Lake and Arrow Lake : Intel Next Gen 3D Client Architecture Platform with Foveros
- Next-Generation Intel processor build for the edge - Intel Xeon D 2700 & 1700
さらに初日のチュートリアルで以下の2本の講義があった。
- CXL overview and evolution
- CXL2/CXL3 coherency deep dive
そのうえPat Gelsinger CEOによる“Semiconductors Run the World”と題した基調講演まで行なわれた。これはスポンサーの裏返しでもあって、今回「も」インテルは、Silver/Gold/Platinumのさらに上の“Rhodium”スポンサーとなっている。そういう裏の事情はともかくとして、今回はこの中で“Meteor Lake and Arrow Lake : Intel Next Gen 3D Client Architecture Platform with Foveros”の内容を説明しよう。
最初にお断りしておくと、今回Meteor Lakeの製品紹介や内部アーキテクチャーの説明などは「皆無」である。では何を発表したのか? というと“with Foveros”の部分で、要するにMeteor Lake/Arrow Lakeに利用されるFoverosの突っ込んだ説明である。少し前にMeteor Lakeの遅延に関してネット界隈で賑わったが、これに関する話ももちろんない。このあたりを期待していた方には肩透かしの内容である。
3D積層技術Foverosは
TSMCのSoICに近い構造
まず最初にFoverosのおさらいというか、以前の説明の訂正をしたい。連載627回でFoverosの説明をしたが、この際に筆者はFoverosをTSMCのInFOに近い物、と想像していた。ところが実際にはInFOではなく、TSMCのSoICに近いものだ、ということが明らかにされた。

Foverosは、SoIC F2F(Face to Face)に構造的には近い。ただバンプの密度はもっと少ない
これは2つのダイを向かい合わせにして、そのバンプをつなぐというものだ。ちなみにSoICでは分子間力を利用しての接続だったが、Foverosではもう少し控えめに、銅のバンプ(というより銅柱)同士をニッケルのハンダで接続するような構造になっている。
AMDのZen 3の場合、3D V-Cache用のTSCの間隔は17μmピッチだったことがTech Insightsの分析で判明しているので、こちらは密度が3460本/mm2ほどになる。これに比べるとFoverosは半分弱、Meteor Lake世代だと772本/mm2弱になるので、4分の1といったところだ。
ではFoveros Omniとは? というのが下の画像で、異なる大きさのダイを相互接続できる。

バンプの密度そのものはFoverosから変わっていない
トップダイの方が大きく、ベースダイが小さい格好だが、この際にトップダイの下に銅柱(図ではCu columnsとしている)を立てることで、トップダイから直接配線をパッケージ外部に引き出せる。このアイディアは、InFOの構造に近い。つまりInFO+SoICが、Foveros Omniというわけだ。
最後がFoveros Directである。こちらの最大の違いは、バンプ密度の向上である。

駆動電力はついに0.05pJ/bit未満まで減っている。Foveros/Foveros Omniの3分の1である
実に10μm未満というか、実際はおそらく9μmまで密度を高めたFoveros Omniということになる。密度を高めることで、例えば同じ帯域を確保するのにより配線の本数を増やせるため、信号の速度そのものは落とせるし、逆に信号速度が同じでバンプの面積が同じなら、帯域を16倍に増やせる計算になる。
またバンプ密度を上げるということは、必然的に配線距離が短くなることになる。バンプのボールが小さくなる分、高さも減るからだ。これは信号駆動電力が少なくて済むということでもあるし、距離が減ればレイテンシーも減る。また、駆動電圧を下げられるので、これもレイテンシー削減に効果がある。
では“Direct”がどこから出てきたか? であるが、最初の画像と見比べてみるとわかるが、銅柱の真ん中にニッケルのハンダがない。銅柱同士が直接接続されているわけだ。これに関しては回答がなかったが、おそらくSoICと同じように、分子間力を利用して2本の銅柱を直接接続しているものと思われる。これがDirectの由来だろう。
ちなみにバンプピッチがなぜ9μmと思うか? と言えば、36μmピッチのFoverosと比較して16倍の配線密度とされるからだ。16倍は縦横4倍と考えるのが普通で、だとすれば36μmピッチを9μmピッチにすれば間隔は4分の1で密度は16倍になる。なのだが、確認したところ「9μmピッチかどうかは将来公開する」とつれない返事であった。
ただ冒頭にも書いたようにMeteor LakeとArrow LakeはFoverosを利用しており、Foveros Omni/Foveros Directは将来の製品(とIntel Foundry Services)向けになっている。そのMeteor Lakeの概念図が下の画像だ。これに近い図は何度か出ているので目にした機会は多いだろう。

4タイル構成。ここからはダイではなくタイルとしている。複数のタイルを組み合わせて1つのダイを構成しているからであろう
まだ個々のタイルの中身がどんなものかは一切公開されていないが、「多分」下図のようになると思われる。
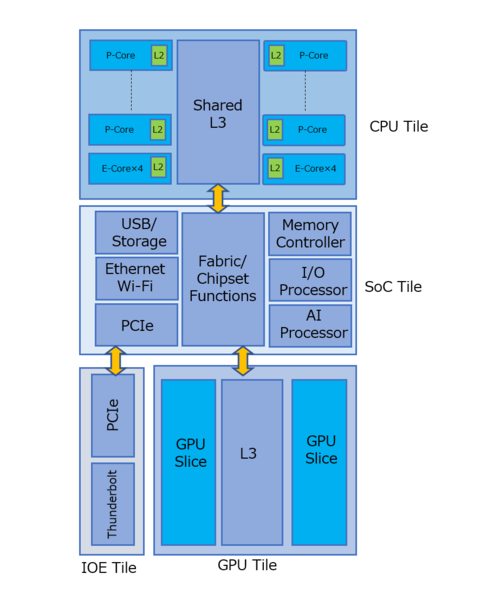
Foveros個々のタイル内部の想像図
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























