




GH100はA100世代からFP32とFP64の数が倍増
学習精度を1%犠牲にするだけで性能が2倍に上がる
ここからもう少し詳細を説明しよう。まずはGH100そのものについてである。GH100の内部構造が下の画像だ。全体で144のSM(Streaming Multiprocessor)が8つのGPC(GPU Processing Clusters)に分かれて実装されている。

GH100の内部構造。全体で144のSMが8つのGPCに分かれている。きっちりGPCで割り切れないので、あるGPCは18SM、別のGPCは17とか16SMというケースもあり得る。現実問題としては、17SMのGPCと16SMのGPCがそれぞれ4つづつ、あたりが一般的であろう。なおGA100も実際には108SMのみ有効である
つまりGPCあたり18SM構成になる計算だ。前世代のA100が128SMを8GPCまとめており、つまりGCPあたり16SMだったので、2SMほど増えている計算になる。
ちなみに上の画像にもあるように、全体では144SMながら実際に有効なのはこのうち132SMで、12SMほど減っているのは冗長コアを意識しているためだろう。さすがに800mm2で欠陥0、というダイの歩留まりは相当低いと考えられるためだ。
またSM自身も猛烈に強化された。GH100のSMが下の画像だ。A100世代がその下の画像であるが、以下のようになる。
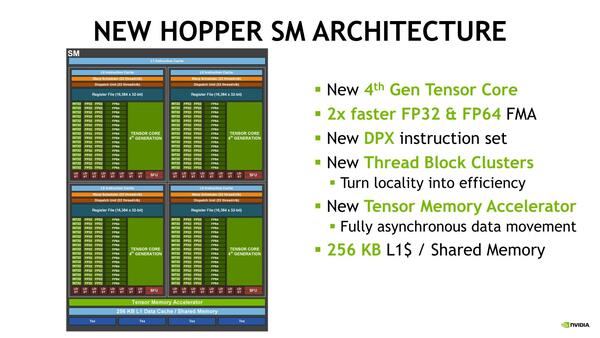
GH100のSM。L0 Instruction CacheやWarp Scheduler、Dispatch、Register Fileなどは据え置きである
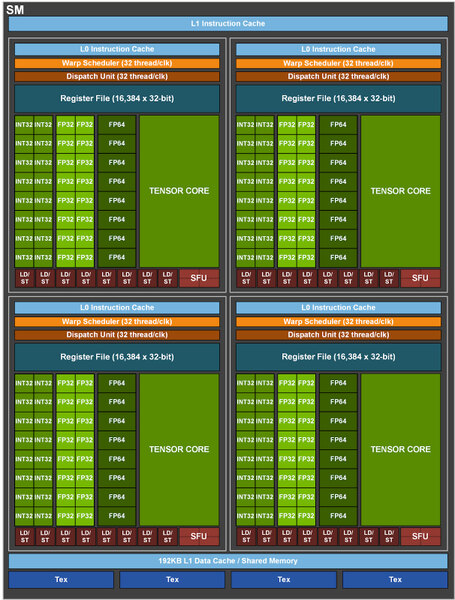
A100世代のSM
- INT32の数は同じながら、FP32の数が倍増した
- FP64の数も倍増した
- Tensor Coreが第4世代になった
- 1次キャッシュと共有メモリーが、A100世代の192KBから256KBに増加した
- DPX命令セットを新たに搭載
- Thread Block Cluster、Tensor Memory Acceleratorを新規に搭載
この結果として、FP32やFP64では、同じ動作周波数でGA100とGH100を比較すると2.44倍の演算性能となり、加えてTSMC 4Nプロセスの採用で動作周波数を引き上げたことでほぼ3倍の性能になる、とされている。
A100がベース1095MHz/ブースト1410MHzとなっており、ここから考えるとGH100(というより、H100 SMX5)はベースは不明だがブーストで1730MHz程度で動作するものと考えられる。
第4世代のTensor Coreの説明が下の画像だ。ざっくり言えばすべての演算型で2倍のスループットを実現しており、加えて新しくFP8をサポートしたのがその違いである。
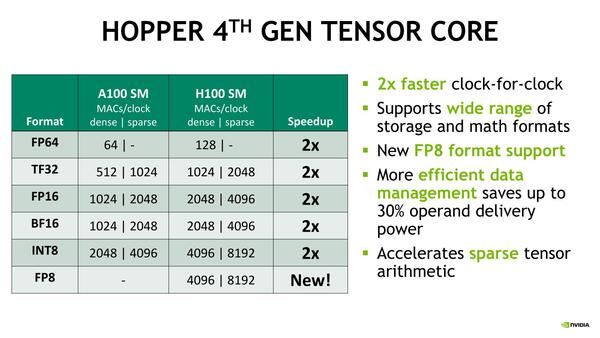
第4世代Tensor Coreの説明。ほかに消費電力を減らしたり、疎行列の計算を高速化したなど、こまかな工夫が追加されている
そのFP8であるが、E5M2(仮数部2bit、指数部5bit)とE4M3(仮数部3bit、指数部4bit)の2種類のフォーマットである。
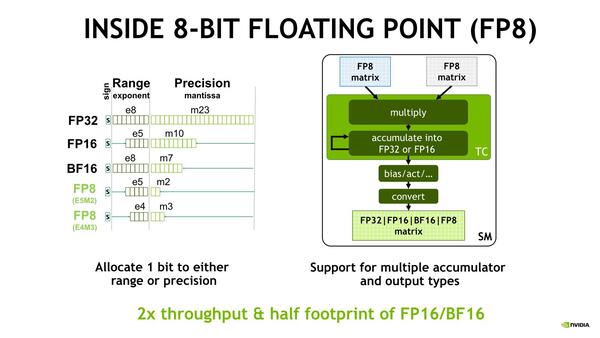
余った1bitで、どっちのフォーマット(E5M2とE4M3)なのかを指定する模様。ということは、符号なしになるという話である。Int 2やInt 4に、指数が付いたという感じになるので、符号は不要な気は確かにする。また既存のフォーマットからの変換も当然サポートされている
こんなに少なくて大丈夫か? という話もあるが、実際Int 1/2/4のネットワークは実際に広く使われ始めており、それなりに精度が維持できていることを考えると、万能ではないにしてもこれでさらに高速化が図れるネットワークは実際に存在するだろう。
こちらではFP16の2倍の速度で演算できるため、データ精度が落ちてもその分演算速度を引き上げることで最終的な演算精度を落とさずにカバーできる。このFP8は別にNVIDIAの発明というわけではなく、2019年にIBM Researchが発表しており、ほとんどFP32と同じ演算精度を保てていることを示している。
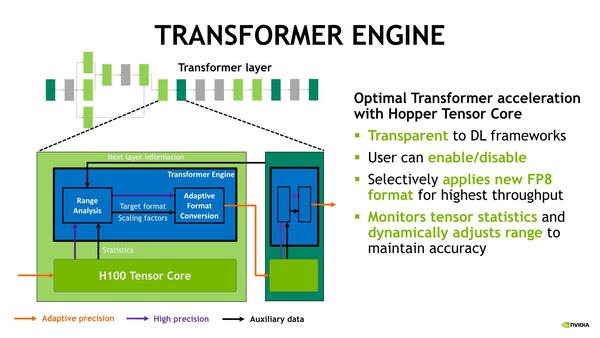
常時OnではなくOn/Offできるというのは、やはり中にはこれで大幅に精度が落ちる場合があることを考慮してなのかもしれない
このFP8を、既存のネットワークで後追いで使えるようにするのが、Transformer Engineである。これは既存のネットワーク向けにTensor Coreに対して作用し、これまでFP16やFP32などで処理されていたデータについてRange Analyzerというユニットでその値の範囲を分析、E5M2とE4M3のどちらのフォーマットを使うかを自動的に決定してFP8で処理するという仕組みである。
これはTransparent、つまり既存のネットワークそのままで実施できる仕組みになっており、ユーザーはこのTransformer EngineをOn/Offするだけの操作である。このFP8を使った場合の精度をBF16と比較したのが下の画像だ。

縦軸が誤認識率、横軸が学習率で、学習が進むとどんどん誤認識率が下がるのは当然として、その傾向がFP8とBF16でほぼ変わらないとする
これは自然言語解析モデルのGPT-3を利用しての場合の数字で、実線がBF16、破線がFP8である。学習件数別に当然誤認識率は変わる(1.26億件程度ではあまり精度が向上しないが、13億件以降は明確に下がる。もっともそれを220億件やっても、すさまじく賢くなるわけでもない)が、これはGPT-3そのものの問題である。
ここで言いたいのは、BF16(実線)とFP8(破線)が学習件数別にみてもほぼ傾向が同じ(精度の差は1%程度)で、精度を1%犠牲にするだけで性能が2倍に上がるということだ。しかもFP8で学習をさせるにあたり、量子化のやり直しやファインチューニングが一切要らない、というのが大きなメリットであるとする。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























