




Alibabaのネットワーク向けに
命令そのものを最適化
Hanguang 800の内部構造が下の画像だ。4つの推論用コアが200GB/秒のリングバスでつながり、その外にコントロールプロセッサーやPCIeなどが付いている。

Hanguang 800の内部構造。Command Processor用のDRAMすらないという潔さ。おそらくは高速なMCUだろうと思うのだが、説明が無いので不明だ
個々の推論用コアはTensor Engine/Pooling Engine/Memory Engineと48MBのSRAMから構成される。ここで外部にDDRやHBMを搭載しないことで、これらをアクセスすることによるレイテンシーの増大や、そもそもの消費電力増大、さらにHBM2の場合はコストアップにもなるわけで、こうした制約から逃れることが可能になった。
ただ後で出てくるが、その分ダイのほとんどをSRAMが占めることになっており、ただそれでも全部で192MBとあまり大きな容量を取れないあたりがネックになる部分で、このあたりのバランス感覚はやはり外販向けではありえない感じである。
ここのコアのうち、まず最初がTensor Engineでテンソル処理を行なう。要するに畳み込み計算や量子化などの処理である。ここで特徴的なのは、命令セットがもう特定のネットワーク専用ではないか? というほどに最適化されていることだ。
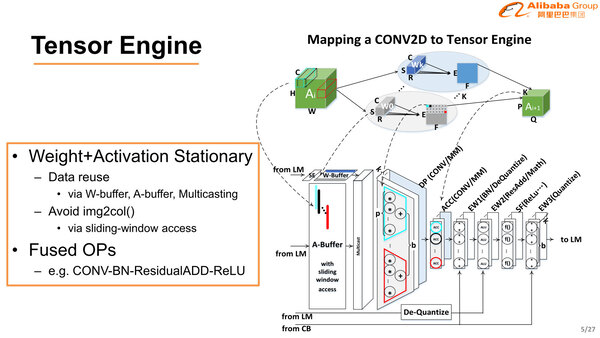
2次元の画像データをカラム(列方向)にアクセスする関数などを用意する代わりに、画像を列方向で格納する機能が用意されている。これはおそらく後述するMemory Engineの機能と思われる
畳み込み→BN(バッチ正規化)→ResidualADD(残余加算)→ReLU(活性化)という流れは、例えば昨今でもBNやReLUを畳み込みの前に入れる方法や、BNを3回実施するなど、いろいろな方法が提案されているが、Hanguang 800ではこのあたりを割り切ったようで、特定のネットワークに向けて命令そのものを最適化していることが示されている。
プーリングエンジンも独特である。INTで受けた値を、内部ではFP19という独自精度で処理して、出力段でフォーマットを変更する形の実装になっている。ここはROI(Region of interest:識別対象が入っているピクセルの絞り込み)の処理も同時に行なうことになっている。
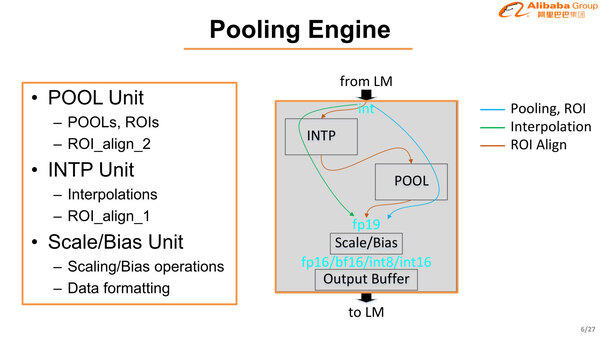
プーリングエンジン。処理によって内部のデータの流れが変わっているのがわかる
メモリーエンジンは画像データの1次元展開や重みのハンドリングなどを行なう。メモリーエンジンそのものはローカルで一切メモリーを持たないので、対象はそれぞれの推論用コアのLM(Local Memory)が対象となる。
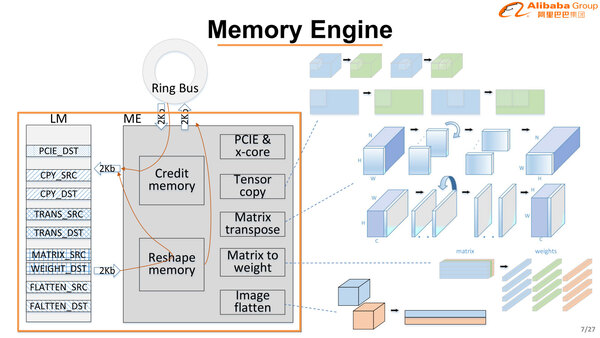
2つ前の画像で“sliding-window access”とあったのは、ここの“Image flatten”の作業の結果を、スライドしながらアクセスできるようにしているのではないかと思う
Hanguang 800の要になるのが192MBのオンチップSRAMである。各コアに48MBずつ割り振られ、それぞれ4つのクラスターに分割。1つのクラスターはさらに32個のモジュールに分割されているので、1モジュールあたりの容量は384KBとなる。
ただ分割されているとはいえ、基本的には共有メモリー構造になっている。幸いというかなんというか、Hanguang 800ではキャッシュに当たるものが見る限り一切ない(上の画像に出てきたCredit MemoryやResharpe Memoryなどのバッファをキャッシュとみなすかどうかは微妙なところ)から、分散メモリー構造としてもキャッシュコヒーレンシーのトラフィックなどは発生しない。3つ前の画像で出てきたW-BufferやA-Bufferは、このモジュールを1個そのまま割り当てる形で動作するようになっている。
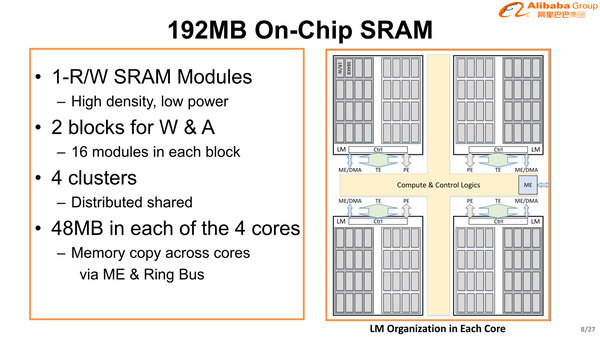
共有メモリーながら、全体をコアあたり128個、チップ全体で512個に分割し、それぞれのブロックを特定のコアの処理専用に割り当てる形で、排他制御の必要性も最小限に抑えている格好だ
ちなみにこの4つのコアはそれぞれ独立して動くことも可能だし、全体を連動させて動かしたり、必要ならPCIe Switch経由で複数チップを連動させることも可能としている。

小さなネットワークなら、最大で4つまで1つのチップ上で同時に利用できる(左)。ある程度大きくなると、4つのコアを連動させて1つのネットワークを動かす形(中央)、超大規模だとマルチチップ構成ということになるが、この超大規模だと共有メモリー構造が災いして、PCIe Switchがボトルネックになりそうに思える
チップそのものはTSMCの12nmプロセスで製造され、ダイサイズは709mm2だから決して小さいチップではない。ただ動作周波数は700MHzと意外に抑えられており、その割にINT 8では825TOPSと結構な性能を示す。
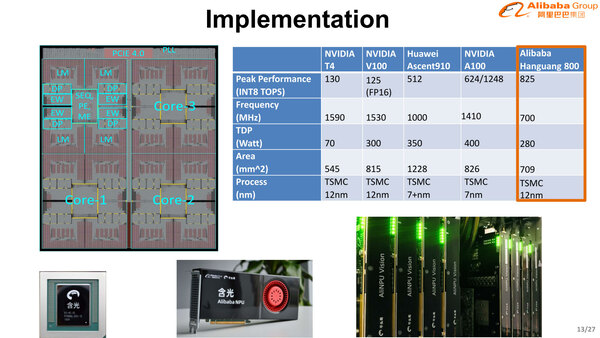
7nmプロセスや最近だと5nmプロセスに移行すればダイサイズは相当削減できそうだが、7nmプロセスは高コストなので、TCOを考えて敢えて12nmで抑えているという可能性もある
ダイ写真を見ると、もう全体の半分以上がローカルメモリーで占められており、Tensor Engine(それぞれのコアに4つづつあるDPとEW)の面積はすごく小さく見えるのだが、仮に全体の25%程度だとしてもトータルで175mm2ほどだから、結構な数の演算器が含まれることになる。
そもそもAlibabaはTensor Engineの内部を今もって説明していないが、700MHz駆動で825TOPSということは、コア1個あたり1サイクルで295 Ops程度の処理ができることになる。MAC演算は2 Ops/サイクルと換算して148 Ops/サイクル程度。17並列のSIMDエンジン×9とかそんな感じになる。
数字があまり普通ではない(17並列のSIMDは普通作らない)ので組み合わせはもう少し異なる(例えば16並列のSIMD×9と、それと並行して動く別のMACユニット×9などかもしれない)とは思うが、ダイサイズ的には無理がない構成だ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























