



幅広いデータソースや「DataSpider Servista」と連携、メタデータの自動収集とシンプルな操作を実現
セゾン情報、データカタログ新製品「HULFT DataCatalog」を発売
2020年11月27日 07時00分更新

セゾン情報システムズは2020年11月26日、新製品となるデータカタログ製品「HULFT DataCatalog 1.0」を12月24日より提供開始すると発表した。メタデータを自動収集する機能で企業内に存在する各種データの状況を可視化し、検索可能なカタログにすることで、企業内におけるデータ活用を促進する。「DataSpider Servista」との連携による、リネージュ(データの来歴)情報の自動収集機能も備える。
同日の記者発表会では、簡単な操作性、DataSpider Servistaとの連携、細かなデータアクセス権限設定、国内サポート、スモールスタート可能な価格設定といった同製品の特徴が、デモンストレーションもまじえながら紹介された。
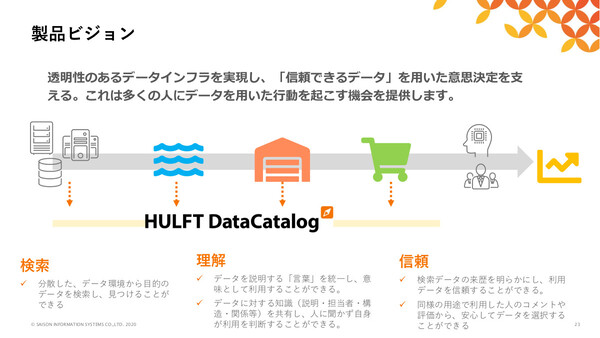
新製品「HULFT DataCatalog」のコンセプト。データソース/データレイク/データウェアハウス(DWH)/データマートに散在するデータをカタログに集約し、データの検索/理解を助ける。リネージュの提供によりデータの信頼性も担保できる

発表会に出席したセゾン情報システムズ マーケティング部 部長の野間英徳氏、同社 テクノベーションセンター 製品開発部 プロダクトマネージャーの吉崎智明氏
メタデータやリネージュの自動収集など、シンプルに使える製品
HULFT DataCatalogは、企業内に存在するさまざまなデータを対象としてメタデータ(データを管理するための情報)を収集し、データの状況を一元的に把握できるデータカタログを構築する製品。データが存在するデータベース/テーブル名/カラム名といったテクニカルメタデータは自動収集することができ、さらに利用者がデータの説明文や品質評価といったメタデータを付与することもできる。
データ利用者は、このメタデータを対象にカタログを検索、データを発見し、さらにコメントやリネージュの閲覧、データ内容のプレビューやダウンロードの機能を使って、データ活用をセルフサービス型で進めることができる。
今回発売される初版(1.0)では、「Oracle Database」「Microsoft SQL Server」「MySQL」「PostgreSQL」「Amazon RDS」といったDBMSや、「Amazon S3」「Microsoft Azure Blob Storage」のクラウドストレージにあるデータのカタログ化(テクニカルメタデータの自動収集)に対応。また、DataSpiderとの連携によって「どんなデータソースから生成されたデータか」「どのように利用されているか」といったリネージュの情報も自動収集される。
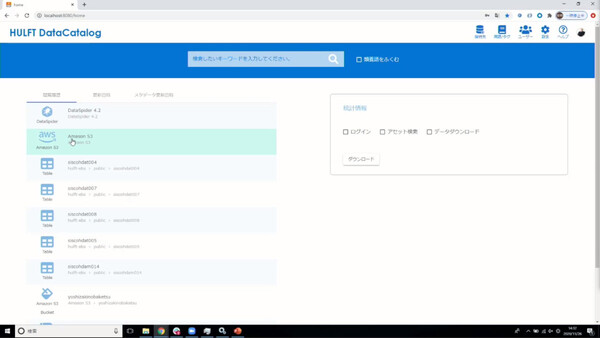
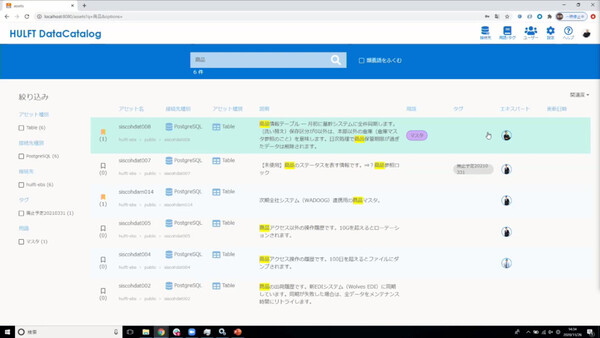
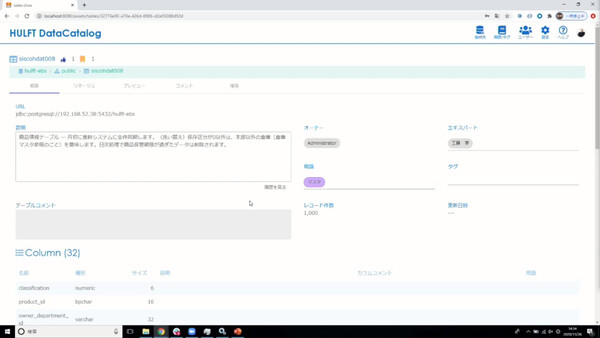
HULFT DataCatalogのトップ画面、検索画面、データの詳細情報画面、リネージュ画面。シンプルで簡単に使えるデータカタログを目指した
またそれぞれのデータに対して、メタデータの書き込み/参照やデータのプレビュー/ダウンロードの細かなアクセス権限設定もできるようになっている。これにより、たとえばエンドユーザーにデータの変更権限を与えないまま、セルフサービス型でのデータ活用を促すことが可能だ。
HULFT DataCatalogは、Windows Server上で稼働するパッケージ製品として提供される。1CPUライセンス/10ユーザーライセンスを含む標準製品(必須ライセンス)の税抜価格は、永続ライセンス版が300万円で、年間保守費用が60万円。年間利用ライセンスと年間保守費用がセットになったターム版は年額210万円。CPUライセンスやユーザーライセンスは追加オプションが提供される。
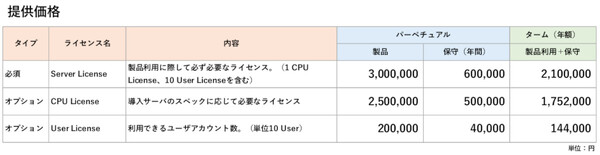
HULFT DataCatalogの提供価格(いずれも税抜)
セゾン情報システムズ マーケティング部 部長の野間英徳氏は、国産パッケージとして、国内サポート窓口の体制や高い品質のサポートが提供できること、スモールスタートが可能な価格体系、ユーザーフレンドリーな操作といった強みがあると説明。まずはHULFTを導入している1万社強の企業をターゲットとして販売を展開していきたいと語った。
データの分散や信頼性担保、規制準拠といった課題を解決するデータカタログ
セゾン情報では2年ほど前から「Data Management Solution」ビジョンを掲げ、5つのカテゴリーでツール群を揃えていく方針を示してきた。野間氏は、今回のHULFT DataCatalogはその一環であり、具体的にはデータ状況の“Identification(見える化)”カテゴリーの製品にあたると説明する。
「COVID-19(新型コロナウイルス感染症)により不確実性は増大し、データの重要性はますます増加している。しかし、企業内に膨大なデータはあるものの散在していて使えていない、またデータ自体は使えても整備されておらず整合性がない、あるいは使っていいデータなのかどうかわからない、といったことが生じている」(野間氏)
こうした課題を解消し、企業内にあるデータをすばやく活用する、また既存システムにあるデータを活用するうえでは「データの見える化が必要だ」と野間氏は強調し、これがHULFT DataCatalogの開発背景になったと語る。
セゾン情報システムズ テクノベーションセンター 製品開発部 プロダクトマネージャーの吉崎智明氏も、現在の企業データ基盤においては「オンプレミス/クラウド/サービスへのデータの分散」「多数のシステム間で連携されることによるデータの“姿形”の変化」「データに対する多様なニーズの発生」といった課題が生じていると指摘した。
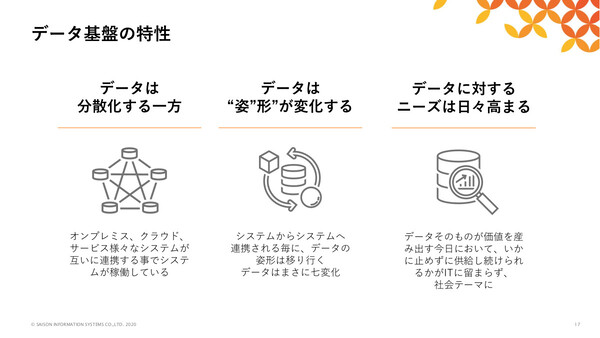
現状の企業データ基盤におけるトレンドと課題
吉崎氏は、HULFT DataCatalogでは、こうした課題を排除した「透明性のあるデータインフラ」を実現し、「信頼できるデータ」を用いた意思決定を支えることで、多くの人に「データを用いたアクション」を起こす機会を提供したいと語る。セルフサービス利用できる簡単な操作性、DataSpider Servistaとの連携、細かな権限設定という特徴から、社内のデータエンジニアをはじめビジネス部門のユーザー、“シチズンアナリスト”でのデータ活用ハードルも引き下げるものと期待していると語った。

HULFT DataCatalogのユースケース例。信頼できるデータに基づく経営計画策定、社内データの把握による機密情報/個人情報の管理厳格化、セルフサービスBIといった用途を挙げた。また部門間で、メタデータに使う用語の不統一を補正するビジネスグロッサリー(用語集)機能も備える

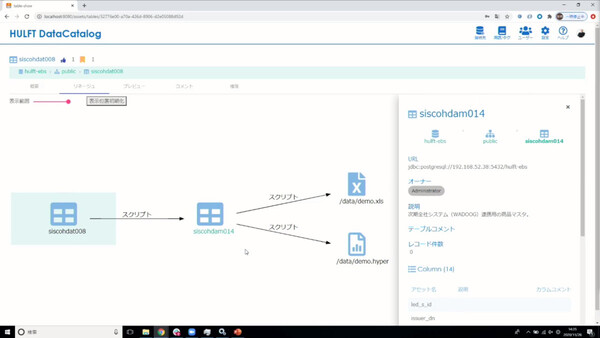
HULFT DataCatalogとDataSpider Servistaの連携イメージ。社内データをセルフサービスで探索/発見し、内容を理解したうえで、DataSpiderによるノンプログラミングでのデータ取得/変換を行ったうえで、外部BIツールでビジュアライズする
本記事はアフィリエイトプログラムによる収益を得ている場合があります



