



「データ&AIの民主化を実現していく」、ソフトバンクが導入顧客としてゲスト登壇
クラウドネイティブな統合分析基盤のデータブリックスが日本法人設立
2020年09月14日 07時00分更新

米Databricksは2020年9月11日、日本でのビジネスを本格化させるため、日本法人としてデータブリックス・ジャパンを設立することを発表した。カントリーマネージャ(社長)には、セールスフォース・ドットコムでコマースクラウド事業部の執行役員を務めていた竹内賢佑氏が就任。「そこにデータがある限り価値を提供できるよう、“データとAIの民主化”を実現していく。今後1年間で日本法人の社員を2倍にしていきたい」と述べて、日本のデータ分析市場におけるプレゼンス拡大を目指す方針を示した。

「Apache Spark」のクリエーターたちが、UCバークレイの学内プロジェクトを発展させるかたちで創業したDatabricks。現在はAIやデータサイエンスに特化した統合分析基盤をクラウドネイティブで提供するプロバイダとして、グローバルで事業を拡大中

データブリックス・ジャパン 社長に就任した竹内賢佑氏、米DatabricksのCEO兼共同設立者のアリ・ゴティシ(Ali Ghodsi)氏
「AI特化/オープンソース/クラウドネイティブ」を徹底する事業戦略
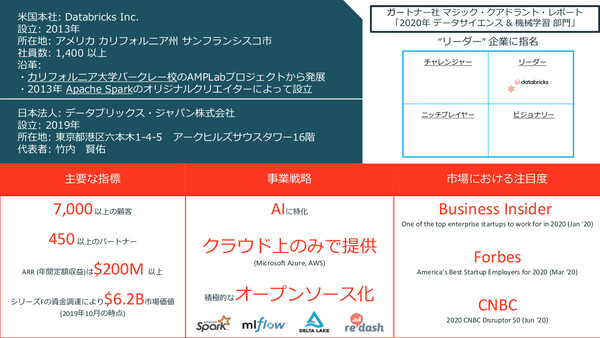
Databricksは米サンフランシスコに本拠を置く、AI/マシンラーニングに特化したデータ分析基盤を提供する企業。開発者に人気の高いオープンソースのデータフレームワーク「Apache Spark」のクリエーターであるマティ・ザハイラ(Matei Zahaira)氏らが2013年に創業し、現在では世界で1400名以上の社員が在籍する。
主力製品であるデータ分析プラットフォームは、Apache Sparkや「MLflow」(マシンラーニングのライフサイクルを支援するプラットフォーム)、「Delta Lake」(Sparkライブラリとして実装されるストレージレイヤ)など、同社が開発に深くコミットするオープンソース技術をベースにしており、AI/マシンラーニングに特化したプラットフォームとして7000社以上の顧客が利用している。
また、同社の製品/サービスは基本的にすべてクラウドネイティブであり、顧客はパブリッククラウド(AWSおよびMicrosoft Azure)が提供するマネージドサービスとしてDatabricksプラットフォームを利用することになる。
02_Databricksの基本戦略は「AI特化」「クラウドネイティブ」「オープンソース」。この基本戦略を掲げ、創業7年目にして日本市場に進出する
AI特化、オープンソース、そしてクラウドネイティブ――。この3つのポイントを徹底する事業戦略を取ってきたことで、Databricksはデータ分析市場において、
・データレイクとデータウェアハウスの統合
・高いパフォーマンスと経済性
・生産性の向上
という競争優位性を獲得したと、竹内氏は語る。
とくにデータレイクとデータウェアハウス(DWH)という、従来であればオンプレミスの環境でそれぞれにコストをかけて構築してきた環境を、クラウド上でひとつのデータソースとして統合したことは、インフラコストの大幅な削減につながっている。さらにデータサイエンスやエンジニアリング、分析などのデータに紐づく作業を一貫して同じ基盤で実行できるため、分析や予測、さらにはそれに伴う意思決定までの時間を大幅に削減し、生産効率を大幅に向上させた事例も少なくない。
また竹内氏は、数年前までデータレイクとして主流だったHadoopを例に挙げ、「Hadoopはパフォーマンスと品質を同時に向上させることがアーキテクチャ上きわめて難しい」と語り、AI/マシンラーニングで実績の高いSparkなどのオープンソースにコミットしているメリットをあらためて強調する。
「AIではモデルの精緻化において反復が必須であり、高いパフォーマンスが要求される。Databricksはインメモリ処理のSparkやエンタープライズの円滑な共同作業をすすめるMLflowなどをベースにしており、Hadoopなどに比較してパフォーマンスやコスト削減、生産性などを大きく改善できる」(竹内氏)

Databricksプラットフォームの特徴。パブリッククラウドからマネージドサービスとして提供することで、データ基盤の統合、高いパフォーマンスと生産性を実現するとしている
記者発表会では、DatabricksのCEO兼共同設立者のアリ・ゴティシ氏がビデオメッセージで挨拶を行った。ゴティシ氏は、「ビッグデータプロジェクトの85%は失敗に終わっており、AIプロジェクトの87%は本番稼働に至っていない」と現状の課題を指摘。その大きな理由は、データがサイロ化した状態に置かれていることにあると説明する。
「われわれはクラウドベースのプラットフォームを提供することでAIのあらゆるプロセスをシンプル化し、分析や予測を短い期間で実行できる環境を届け、データとAIのポテンシャルを高めていく」(ゴティシ氏)
“クラウドネイティブ特化”という特徴は、裏を返せば、自社データセンターなどオンプレミスで活用したいというユーザのニーズとは相容れないものである。その点について同社に質問を向けたところ、「どうしてもオンプレミスやプライベートクラウドでの活用を望むユーザは、オープンソース化されているSparkやDelta Lake、MLflowなどを個別に使うことが可能だ。ただしDatabricksとしては、3つの基本戦略(AI特化、オープンソース、クラウドネイティブ)を徹底し、『フルマネージドのサービスをパブリッククラウドから提供する』という方向性でビジネスを拡大していく」という回答を得た。日本市場においても、グローバルで共通化しているこの戦略を継続して展開していく方針だ。
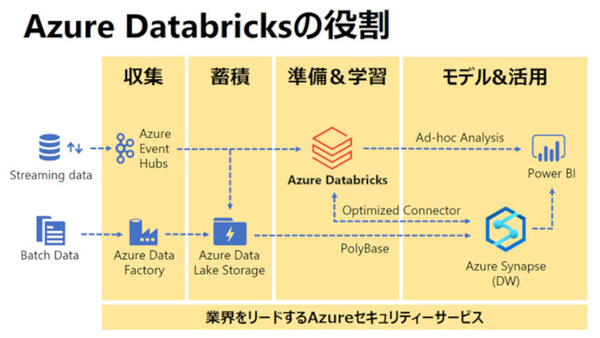
Databricksのデータ処理基盤は、AWSもしくはAzureのマネージドサービスとして提供される。Azureにおいては、オブジェクトストレージの「Azure Data Lake Storage」、次世代データウェアハウスの「Azure Synapse Analytics」などと連携した統合データ分析プラットフォーム「Azure Databricks」として提供されている
オンプレミスのHadoopデータレイクをDatabricksで刷新、ソフトバンクが語る
Databricksの顧客企業には、Netflix、スターバックス、HSBC、Grabなど、さまざまな業界のビッグプレイヤーが名を連ねている。日本でも、ソフトバンクや日経新聞などがすでにDatabricksプラットフォームを導入済みだ。発表会にはゲストとして、ソフトバンク IT&ネットワーク統括 IT本部 本部長 北澤勝也氏が登壇し、同社のデータ分析業務におけるDatabricks活用についてコメントしている。

ゲスト登壇したソフトバンク IT&ネットワーク統括 IT本部 本部長の北澤勝也氏
ソフトバンクでは「全社横断のデータレイク環境」として、2015年からHadoopを4年間に渡って利用してきたが、データ量と処理プロセスの増加により、処理性能の不足に悩まされることになる。とくに、データ作成処理が走る夜間帯(午前1時から9時まで)の間は、継続してメモリ使用量が100%に到達するなど、深刻なメモリ枯渇が発生していた。また、ソフトバンクは自社データセンターでHadoopを運用していたが、データ量が劇的に増えるにもかかわらず、分散処理に必要な物理サーバを追加するためのまとまったラックスペースや、供給可能な電力/空調設備がないという状況が深刻化していた。
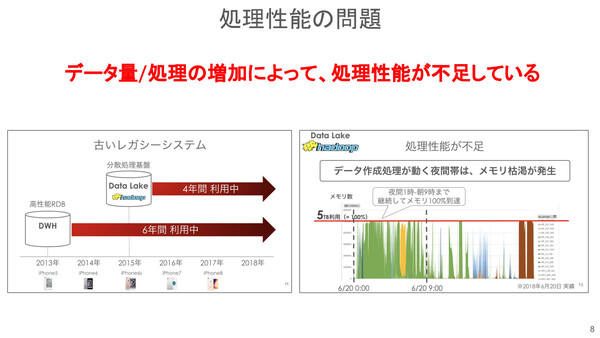
ソフトバンクがレガシーのHadoopで抱えていた処理性能の問題。メモリ不足が慢性化しており、とくに夜間は継続してメモリ使用量がフルに達していた
ここでIT本部がとった方針が「戦略的なデータ利活用に向けての基盤刷新」――つまり、オンプレミスで別々に運用していたデータウェアハウスとデータレイク(Hadoop)を、パブリッククラウド(Microsoft Azure)上で提供されるマネージドサービスの統合分析環境に移行するというものだった。最終的には、Microsoft Azufeが提供するマネージドサービス「Azure Databricks」を選択している。
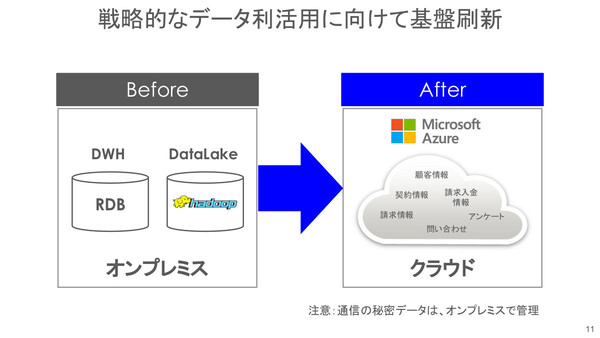
ソフトバンクが選んだ基盤刷新は、Azure上からマネージドサービスとして提供されるDatabricksへの移行。ばらばらに保存されていた、さまざまな形式のデータをひとつの基盤に統合した
北澤氏は、ここでDatabricksを選んだ理由として、
・強力なスケーラビリティ … 特定時間帯の大規模データ処理にあわせてオートスケール
・柔軟な構成 … 処理の重要度や特性にあわせて処理するクラスタを自在に構成
・現行資産の有効活用 … ソフトバンクが以前から活用してきたSparkベースのアーキテクチャであり、オンプレミス(Hive)との互換性もあり
を挙げている。
採用後、いくつかの問題(ナレッジの不足、都度発生する障害との戦い)も顕在化したものの、「DatabricksやMicrosoftのエンジニアと連携して、ひとつずつ克服」(北澤氏)していったという。
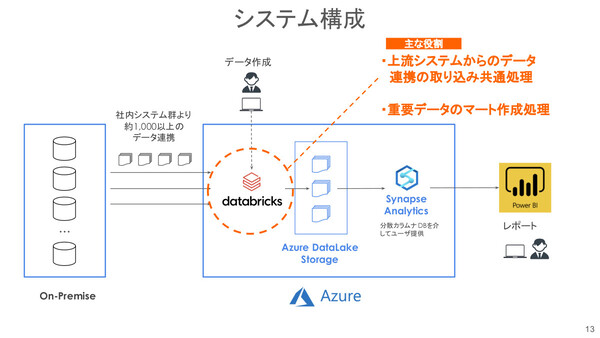
ソフトバンクのデータ基盤刷新後の構成。Azure DatabricksはAzure上の各サービス(Azure Datalake Storage、Azure Synapse Analytics)と連携しており、データレイクとデータウェアハウスが統合された分析環境を容易に利用できる
北澤氏は、Databricksを採用した結果として、
・データ提供早期化 … Databricksのオートスケール機能とアプリケーション見直しにより、1.5時間以上の早期提供
・オートスケーラビリティの獲得 … 日々一定ではないデータ量に対し、過不足なく安定したデータ提供を実現
といった効果を短期間で獲得するに至ったと説明した。
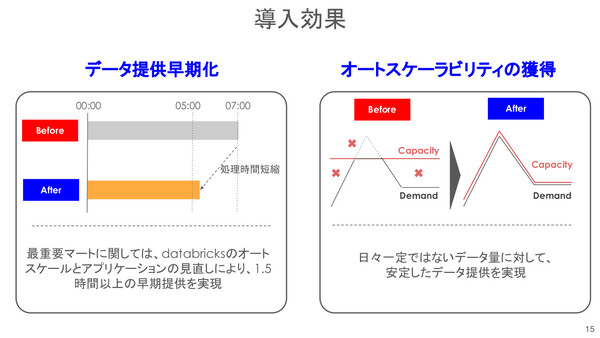
ソフトバンクにおけるAuzre Databricksの導入効果。データ処理時間が1.5時間以上短縮され、オートスケーリングにより安定したデータ提供が実現
* * *
本稿冒頭で触れたとおり、竹内氏は、データブリックス・ジャパンでは日本市場における“データとAIの民主化”を推進していくとコメントした。
「ビッグデータやAIの活用で成功している企業は世界でもひと握り。われわれはそうした状況を打破すべく“AIの民主化”を提唱していきたい。そのためには“データの民主化”が必須であり、日本企業に対してもその方針を強力に推進していく」(竹内氏)
オンプレミスやハイブリッドクラウドでデータ分析基盤を運用する企業が多い日本市場において、グローバルと同じクラウドネイティブ戦略がどこまで受け容れられるのか、日本企業の“データ&AIの民主化”をはかる指標としても非常に興味深い。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



