




初代Google TPUの2倍の性能を誇る第2世代
以下、この2つのソースをもとに解説する。まずGoogle TPU v2の基本構成が下の画像だ。1つのチップに2つのダイが搭載され、おのおののダイに8GBのHBMが装着される構成になっている。
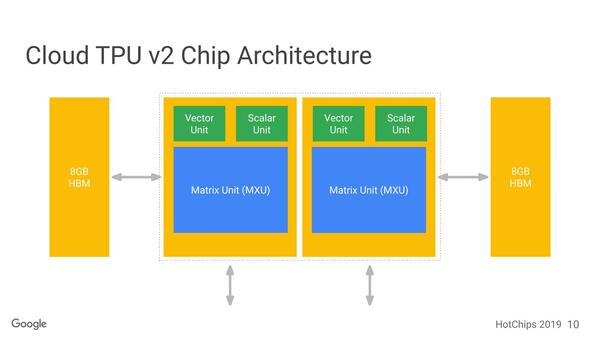
初代Google TPUの反省は外部メモリーの帯域が低すぎたことだそうで、それもあってHBMを使って大幅に高速化された
それぞれのコアの詳細は下の画像だ。MAC Unitは128×128と1/4のサイズになったが、その代わり一度に全ユニットの計算が可能になっている。
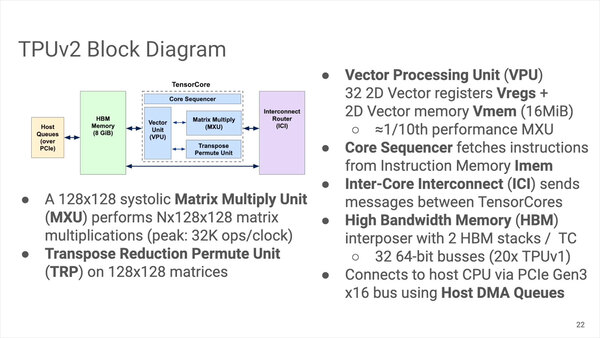
ダイあたりで言えば、PCIe Gen3 x32でホストと接続される構造となる。VPUはMXUの10分の1程度の性能とされる
また16MBのVmemも搭載されている。加えて言えば、データ型も初代のINT 8からTPU v2ではBfloat16/FP32に切り替わった。推論だけならINT 8のままでいいのだろうが、学習に向けてはやはりもう少し精度というか桁数が欲しい、というニーズに応えたものである。
ダイのフロアプランは下の画像がわかりやすい。MXUよりもVPU+Vmemの方がはるかに大きなエリアを占めているのがわかる。
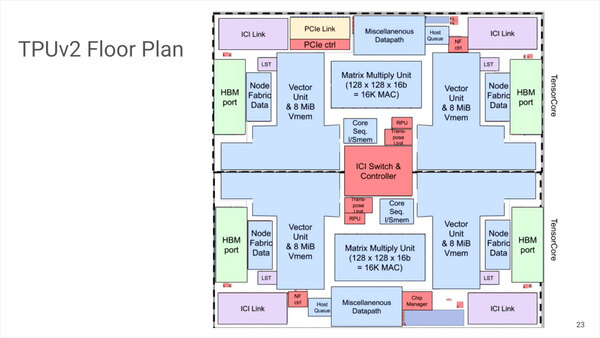
PCIe Linkそのものはダイに1ヵ所か所で、このあたりだけ対称性が崩れている。製造プロセスやダイサイズなどは未公表だが、プロセスは時期的なものから考えるとTSMCの20nmではないかとみられている。動作速度は700MHz
またこのGoogle TPU v2の設計の最中に、Bach normalizationという論文が発表されている。この仕組みを、Google TPU v2ではハードウェアとソフトウェアでサポートすることで、学習速度を最大14倍にできたとしている。

具体的にはベクトルユニットのスループットを初期デザインの8倍にしたほか、逆平方根の計算を行なうハードウェアを追加したとしている
ちなみにCloud TPU v2が64台のPodで11.5TFlopsとされているので、1台(つまり4チップ)あたり180TFlops、ダイ1個あたり45TFlopsという計算になる。

こちらはHot Chipsの論文より
Google TPU v2では先にも書いたがBfloat16/FP32で計算しているので、処理速度はチップ1つあたり45TOP/秒という計算になり、これはおおむね初代Google TPUの2倍の性能に相当する。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















