



独自特許の経路探索技術などを採用した「Kamuee」エンジン、Interopでコアルーターとして実働展示
NTT Comが「世界最高速レベル」ソフトウェアPCルーター開発
2018年06月12日 07時00分更新

NTTコミュニケーションズ(NTT Com)は2018年6月11日、高速/広帯域なパケット転送を可能にするソフトウェアエンジン「Kamuee(カムイ)」を開発したことを発表した。特許技術である「Poptrie(ポップトライ)」やインテルの「DPDK」ライブラリの活用により、特殊なハードウェアを搭載しないx86サーバーをベースとして、高性能なキャリアのバックボーンルーター(BGPルーター)などを安価に実現しうる技術。6月13~15日開催の「Interop Tokyo 2018」では、「ShowNet」を支えるコアルーターとして実働展示される。
8日に行われた記者説明会では、Kamueeの開発を主導してきたNTT Com 技術開発部の小原泰弘氏が、Kamueeの技術的な特徴や開発背景、今後の展開などを紹介した。

NTTコミュニケーションズ 技術開発部 主査 博士(政策・メディア)の小原泰弘氏
小原氏は、Kamueeはソフトウェアパケット転送エンジンとして「世界最高レベルの性能を持つのではないか」と説明する。今回はまずバックボーンルーターという形で実装したが、そのほかにも仮想ルーター、ストリームサーバー、トラフィックジェネレーターなど、多様なバリエーションへの展開が考えられる。どのような市場ニーズや製品/サービス展開の可能性があるかを知るために、広く告知して反応を知りたいと語る。
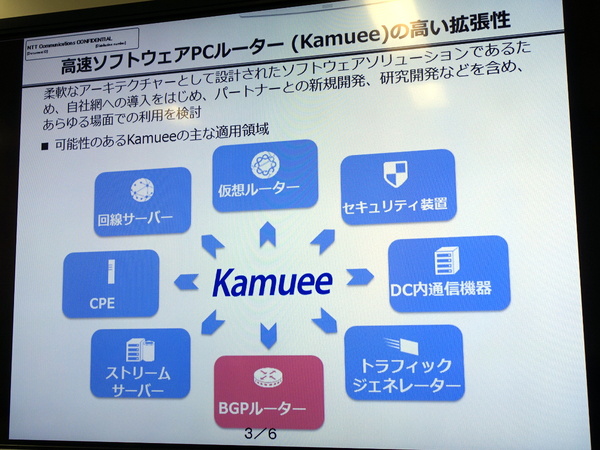
Kamueeは幅広い領域への適用が考えられる。今回は第一弾としてソフトウェアBGPルーター(バックボーンルーター)を実装した
Kamueeは「Poptrieによる高速経路探索」と「DPDKによる高速パケット転送」という、大きく2つの技術的特徴を持つ。
Poptrieは、東京大学 特任助教の浅井大史(ひろちか)氏(現在はPreferred Networks研究員)との共同研究/共同開発で生まれた高効率な経路検索アルゴリズムだ(2015年に技術特許取得)。ハードウェア技術で構成されるバックボーンルーター専用機は、経路検索に最適化された特殊なメモリ(TCAM:Ternary Content Addressable Memory)を搭載している。「たとえば200MHzで動作するTCAMならば、1秒あたり最大2億ルックアップくらいの性能となる」(小原氏)。Poptrieでは、このTCAMと同等の性能をソフトウェアで実現する。
具体的には「経路探索に必要な命令数の削減」と「経路データの大幅な圧縮」を実現したことが、従来のソフトウェアルーターとの大きな違いとなる。より少ない命令数で経路探索が可能なアルゴリズムにすると同時に、現在72万を超えるインターネットのIPv4全経路(フルルート)をキャッシュメモリに格納できるサイズまで圧縮することで、高速な探索処理を可能にしたという。
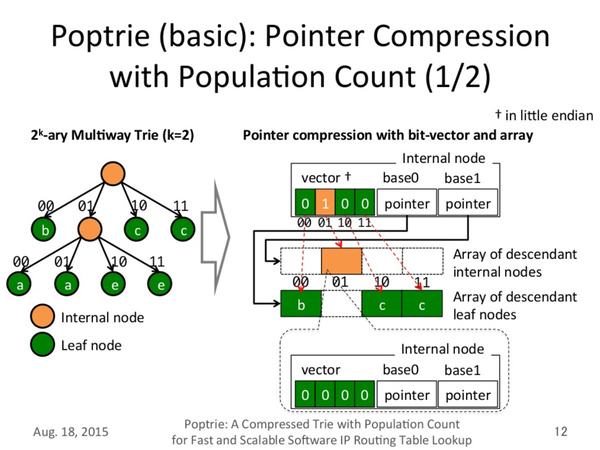
Poptrieの採用で、より少ない命令数での経路探索が可能になり、経路表もキャッシュメモリに格納できるサイズとなったため探索処理が高速化される(画像は小原氏、浅井氏の論文より)
「これまでは、およそ70万経路の経路表は100MBくらいのメモリ容量を消費していた。Poptrieではこれを効率的に圧縮することで、3MBに収まる程度の容量にできる。これならばCPUのL3キャッシュにも経路表全体が乗り、メインメモリにアクセスすることなく高速に処理が可能だ」(小原氏)
もうひとつが、インテルのDPDK(Data Plane Development Kit)採用による高速なパケット転送だ。DPDKは、ソフトウェアルーターなどパケット処理を行うソフトウェア向けのSDKであり、簡単に言えばマルチコア環境を前提に「CPU(コア)をパケット転送に専有させる」(小原氏)ことを可能にする。これをシンプルに利用することで、ソフトウェアベースで高速なパケット転送が出来るのではないか、という発想だったという。
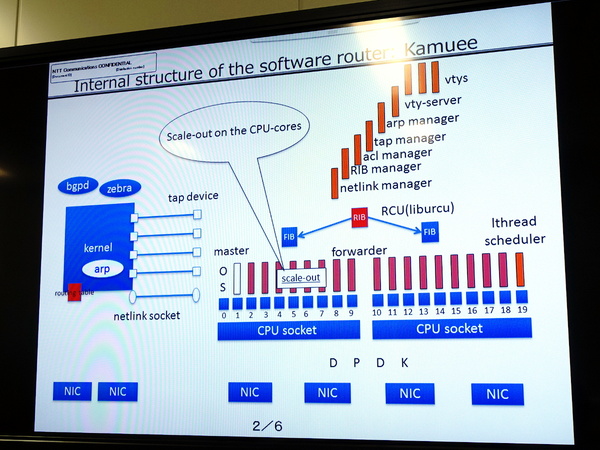
Kamueeの内部アーキテクチャ図。DPDKスレッドを多数のコアに割り当てパケット転送を並列処理する。経路表(RIB/FIB)はPoptrieでコンパクトに圧縮されており、キャッシュメモリに格納できるため高速な経路探索が可能
Kamueeでは、CPUコアごとにDPDKのスレッドを立ち上げ、各スレッドは(OSを介さず)NICやCPUキャッシュ内のデータに直接アクセスする。転送処理が必要なパケットをあるコア(のDPDKスレッド)が受け取ると、ほかのコアに処理を移動させずに、経路探索と送信先の決定、パケット送信の処理は最後までそのコアが実行する(Run-to-Completionモデル)。こうした仕組みで高速な転送処理を実現している。「DPDKの推奨するRun-to-Completionモデルを素直に実現するための設計を行った」(小原氏)。また、Run-to-Completionモデルで処理がコアごとに完結する仕組みになっているため、トラフィックを各コアに分散すれば並列処理によるスケールアウトも容易なアーキテクチャだという。
そのほか、DPDKのデータプレーンと分離されたコントロールプレーンでは、Linuxで稼働するオープンソースのツール資産(GNU Zebra、Quagga、bgpdなど)がそのまま活用できる点もメリットだと、小原氏は説明した。
NTT Comによる実機検証では、一世代前(Broadwell世代)のサーバーと40GbE NICを用い、NIC 1ポートあたり5コア(DPDK 5スレッド)を割り当てたところ、64バイトパケットで最大257.61Mpps(172.92Gbps)を記録した。これをCPUソケット数で割り他のソフトウェアと比較すると「世界最高レベルの性能」に該当するという。ちなみに、512バイトパケットでは277.5Gbps(65.20Mpps)のスループットを記録している。
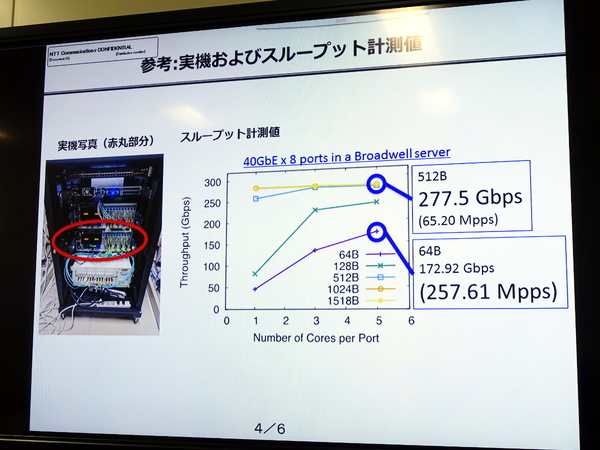
NTT Comによる実機でのスループット検証結果。なおこの40GbE NICはPCIe Gen3接続であり、ここがGen4にアップグレードされれば今後さらにスループットが高まる可能性もあるという
なお前述したとおり、Kamueeはバックボーンルーターだけでなく幅広い展開が考えられる技術だ。これをどのように製品/サービス化していくかは、これから顧客の声などを聞いて検討していく。当然、大幅なコスト削減につながるNTT Com自社網への導入も考えているという。
説明会に同席したNTT Comネットワークエバンジェリスト/技術開発部担当部長の宮川晋氏は、大きな期待を持つ適用領域として「仮想ルーター」を挙げた。これまでのソフトウェアルーターは100GbEのような高いパフォーマンスを実現することができず、それが必要な場面ではハードウェア専用機に頼らざるを得なかった。Kamueeベースの仮想ルーターが開発されれば、ハードウェアルーターには実現できないことが実現できるはずだと、宮川氏は強調した。
「KamueeをSR-IOV(Single Root I/O Virtualization)などの技術と融合させると、完全にクラウドシステムの中のルーターとして完成させられるのではないか。そうすると(従来の仮想ルーターにおけるパフォーマンス課題が解消することで)エンタープライズの企業網全体、ICT全部を仮想化してしまうような、壮大な夢も描ける」(宮川氏)
本記事はアフィリエイトプログラムによる収益を得ている場合があります



