



AIチャットボットの機械学習基盤で得たノウハウを「ServerlessConf Tokyo」で披露
商用サービスのサーバーレス構築は「すごく大変」、リクルートLSが語る
2017年11月28日 07時00分更新

Amazon S3:オンプレミスとのインタフェースは可用性の高いサービスで
この機械学習基盤のパイプライン処理は、S3ストレージに新たな処理対象データ(質問ログデータ)がアップロードされたというイベントをトリガとして、自動的にスタートする。
「スケジュール実行やポーリングなど、バッチをキックする(バッチ処理を自動で開始する)方法はほかにもある。だが、イベントトリガ型を選ぶことでサーバーレス化することができ、スケーラブルにもなるメリットがある」(堤氏)
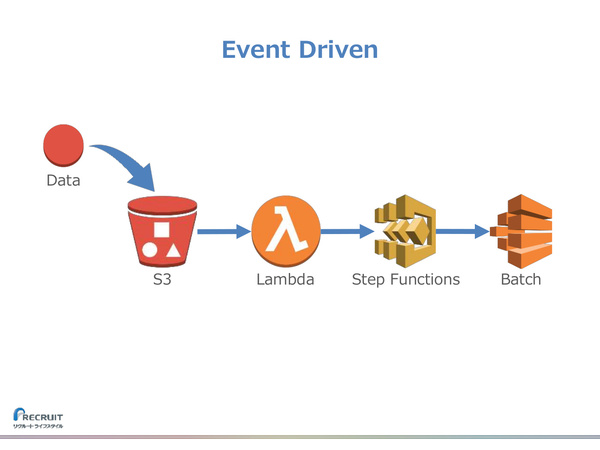
S3へのデータ追加イベントをトリガとして、一連の処理がイベントドリブンで自動実行される仕組み
さらに堤氏は、可用性が高いS3をインタフェースとしてここに置くことで、クラウド側での障害がオンプレミス側に影響しない構成になっていることも指摘した。
「機械学習などの処理は、途中で落ちる(処理が停止する)ことも多い。その影響がオンプレミス側にも波及することを防ぐために、その間のインタフェースには可用性の高いものを選ぶべきだ」(堤氏)
また山田氏は、オンプレミス環境とのインタフェースをS3に統一したことで、発行するクレデンシャルが1種類だけで済み、セキュリティリスクを低減することができたと説明した。
Step Functions:バッチ処理の起動から完了までを見届ける
S3にデータがアップロードされると、Lambdaがそのイベントをトリガとして、ワークフローエンジンのStep Functionsを起動させる。Step Functionsには、LambdaがAWS Batchによるバッチ処理を起動し、処理完了までを見届けるワークフローが定義されている(エラー処理については後述する)。
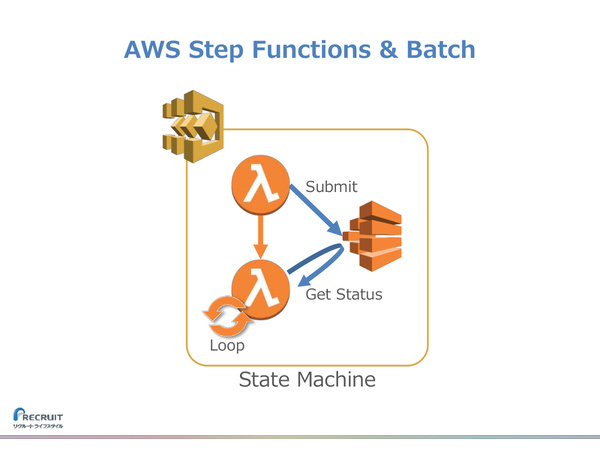
Step Functionsで定義されているワークフロー(ステートマシン)
「ワークフローエンジンにはさまざまなものがあるが、Step Functionsはフルマネージドなサービスとして提供されるため、サーバーを立てる必要がない。サーバーを立てることにより生じるSPOFを回避でき、運用コストも下がる」(山田氏)
なお前出の図のとおり、“S3→Lambda→Step Functions→AWS Batch”という一連の処理は、2回実行されるようになっている。1回目のAWS Batchで下準備(Amazon RedShiftへのデータのロード)を行い、2回目で実際に機械学習処理を行う役割分担だ。
堤氏は、これをどう実現するか考えた結果、1回目のデータロード処理が成功したら、何らかの結果データをS3に書き込み、そのイベントをトリガとして2回目の機械学習処理を自動実行する仕組みにしたと説明した。

2回目の処理を起動するために、再度S3のイベントトリガを使う
AWS Batch:バッチをDockerコンテナで開発可能、実行コストも低減
前述した2回のバッチ処理(RedShiftへのデータロード、機械学習処理)を実行するのがAWS Batchだ。
AWS Batchはフルマネージドのバッチ処理エンジンである。キューに登録されたジョブがあれば、EC2インスタンスを起動して実行し、ジョブの処理が終了したらそのインスタンスを破棄する、バッチ処理の自動実行機能を提供する。今回のシステムでは、バッチをDockerコンテナとして開発しているという。
「AWS Batchは、実行するジョブとしてDockerコンテナを定義することもできる。これを使えば、ローカルのDocker環境で開発し、そのDockerイメージをクラウドに載せたら、あとはAPIを叩くだけで起動(バッチ実行)が可能だ。またスケーラブルな仕組みであること、オンデマンドでEC2を起動するので、(インスタンスを常時起動させておくのに比べて)実行コストが大きく下がることもメリットだ」(山田氏)
なお、AWS Batchへのジョブ登録時にはジョブ実行に使用するリソース(仮想CPU数とメモリ容量)を指定するが、ここではEC2で提供されているインスタンスタイプを強く意識したうえで指定しないと、動作トラブルの原因になると堤氏は注意を促した。
「AWS Batchは、ジョブ登録時に指定されたCPU数/メモリ量に基づいて“最適な”EC2インスタンスを自動的に選び、起動する仕組み。ただし、おかしな指定をすると、エラーを出さずに『Runnable』の状態で(EC2インスタンスを起動できず)止まってしまう」(堤氏)
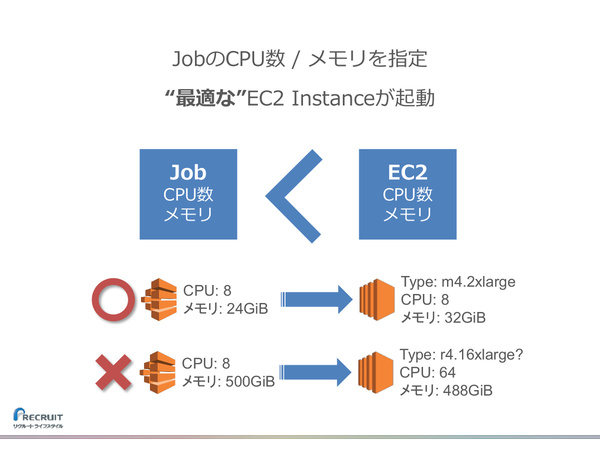
ジョブのCPU数/メモリは、どのEC2インスタンスタイプで実行されるかを意識したうえで指定しないとトラブルの原因となる
機械学習処理が成功すれば、その結果データ(学習モデル)をS3に書き込んで終了する。あとはオンプレミス側から定期的にそのデータを取得する。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



