データを効果的にビジュアライズするために、またデータを分析するための補助ツールを作るためには、よく考えられたデータ管理フレームワークを持つことが大切です。ツールには、適切なバックエンドストレージ、データアクセスのパラダイム、魅力的な表示や分析のためのフロントエンドが求められます。Webアプリのデータアクセススタックを構築するためのツールをこの記事では紹介します。
訪問者のデータを収集しているサイトなら、そのデータを活用したいはずです。私たち開発者は、透明性を保ちながら最高のユーザーエクスペリエンスを提供し、直感的で強力なツールでデータを扱えるようにするべきです。データのビジュアライズは一部でしかありません。優れたユーザーエクスペリエンスに貢献するのは、データの保存、変換、送受信などの総合的な仕組みなのです。
データストレージの選択
近年、データストレージは大きな市場になりました。アプリケーションに採用する技術の選定は気の滅入る作業です。考えるべきことは、パフォーマンス(性能)、スケーラビリティ(拡張性)、実装の容易さ、チームが持つスキルなどいくつかあります。最後に挙げた「チームが持つスキル」はものすごく大切なのに見落とされがちです。チームにSQLの開発者がいるのなら、よほどの利点がない限りわざわざMongoDBに移行しないでしょう。
速くて簡単な道は「できる方法でやる」以外にはありません。
CSVファイルを思い浮かべれば分かるように、フラットなデータベースは単一のテーブルだけで構成されるため理解しやすく、扱いやすいです。しかしすぐに限界が来ます。データが肥大化すると性能が低下してメンテナンスも困難になります。もしフラットなデータベースを使っているなら、なにかほかのストレージに乗り換えたいと考えているところではないでしょうか。
リレーショナルデータベース(MySQLやSQL Server)は、別々のテーブルにデータを保存しつつも一意のキーで複数のテーブルを連結して使える、優れたデータベースです。サイズが小さくなり、性能も向上するうえにすでに確立されたSQL言語が使えるメリットもあります。リレーショナルデータベースは、計画を立ててデータ間の関連と性能面に適切なキーを設定しなければなりません。
人気上昇中なのは、データをJSONオブジェクトに格納できるMongoDBなどのドキュメント指向データベースです。フラットなファイルよりも冗長にならず、効率が良くなります。さらにJavaScript用のデータ形式「JSON」で保存できる利点もあります。ただし、複数のテーブルを結合したり要約・集約したりする場合は複雑になります。
Hadoopをはじめ非構造化データベースはデータ量が大きい場合に適しています。今回は対象外ですが、もし膨大なデータ量を扱うなら、データをサイトで使用する前に抽出、変換、ロード(ETL)をして標準化する必要があるはずです。
クライアント側にデータを保存する選択肢も魅力的ですが、問題もあります。クライアントのマシンにファイル保存しデータをキャッシュすれば効果を発揮しますが、ユーザーとの間に一定の信頼関係が求められます。ユーザーから承認されたサービス、ユーザーが大量のデータを扱うことを承知しているならファイル保存を許可してくれるかもしれません。しかし、ユーザーの承認は期待しないほうが良いでしょう。どうしても求められる場合は別ですが。
データアクセスレイヤーの作成
データアクセスレイヤーの作成方法はいくつかあります。ビューは、リレーショナルデータベースにおいて定番の方法でした。ビューは、データに対するクエリを発行した結果がテーブルで表示されます。group by、order by、sumなどのデータ集約法を使い、表示や分析に使うためのコンパクトで的の絞れたデータセットが取り出せます。
CREATE VIEW population_vw AS
SELECT country, age, year,
sum(total) AS TOTAL
FROM census_data
WHERE year IN ('2010')
AND country IN ('United States')
GROUP BY country, age, year;ほとんどのリレーショナルデータベースはETLプロセスを通してマテリアライズド・ビュー(体現ビュー)の作成もできます。1つのテーブルのみのアクセスとなるため性能が向上します。
これらを組み合わせた方法も有効です。よくあるのは、SQL Serverに格納された大きなデータベースの上に、より的を絞ったMongoDBのレイヤーを設けます。大切なのはドキュメント指向データベースに任せることで高速なアクセスと利用を可能にしつつ、バックエンドのSQLデータベースには完全なデータが保存されているわけです。Nodeなら、Expressでデータセット作成の管理とMongoDBサーバーへの格納が可能です。
OLAP(Online Analytical Processing)でも、表示するデータの切り口や指標などを事前に設計して集約したデータセットを作成できます。OLAPはデータへのアクセスに多次元表現(Multidimensional Expressions、MDX)を利用していますが、Webアプリにはそれほど普及していません。
ネットワークへの依存性
データをユーザーへ届ける前に、できる限りサイズを小さくするべきだと考えられてきました。しかし難しさも伴います。サーバー側で最大限まで集約してしまい、ユーザーがデータの表示項目を変更するだけなのに、必要なデータがそろうまで何度もサーバーのデータにアクセスして、結果ネットワーク負荷がかるのです。
重要なことは、回線速度を考え高速に応答できるサイズまでデータを集約することと、分析するのに十分なデータ量を提供することの中間点を見つけることです。そのために、ユーザーが分析のために必要としている重要指標と切り口が何なのかを見極める必要があります。
データにアクセスする方法で一般的なものはRESTful APIです。RESTful APIはリモートサーバーからデータを要求し、得たデータをアプリで使用できます。形式はJSONです。HTTPリクエストのたびに一定の遅延が発生するのでできるだけその数を少なくします。詳細を省きつつ、かといって集約しすぎないレベルでデータ量を小さくするのが得策です。さらにデータ量を減らすならクライアント側でのデータ保存も検討します。
APIリクエストを明示的にするなら、APIにクエリを定義できるGraphQLが便利です。GraphQLのように言語を使えば特定のデータだけを抜き出すのは容易です。GraphQLは、Facebookのように多数の分類と複雑な関係性を扱うアプリで一躍スタンダードになりました。
関数、ツール、テクニック
JavaScriptはES5から、array prototype(配列のプロトタイプ)という優れたツールができました。filter()は、配列からクエリに合致した要素だけを抜き出します。reduce()はデータを扱いやすいよう集約してそのデータセットを返します。map()も、新たなデータ抽出条件の作成に使用できます。これらは広くサポートされていて、元の配列を変更せず、追加のライブラリーも不要です。
データのプレゼンテーションレイヤーで個人的なお気に入りはD3です。DOMの操作、とりわけSVG要素が操作できるので、優れた表現が可能です。シンプルな棒グラフ、折れ線グラフ、円グラフから、より複雑で対話型の表現までカバーしています。D3による、フル機能のダッシュボードのデモを作成しました。以降の記事内ではリポジトリにあるコードを参照します。
Chart.jsをはじめ、そのほかの簡単に使えてカスタムの余地が少ないツールは、さほどカスタムせずに手早く可視化表現を追加したい場合にとても便利です。
サイトにグラフを表示するには、グラフの書式設定欄にクリックなどのイベントをバインドして、ページ上のSVG要素の描画にかかわる関数がコールされるようにします。
document.getElementById("total").addEventListener('click', function() {
barGraph.render(d, "total")
});関数にはデータの区分であるtotalと、データセットdを渡しました。これには以下の2つの利点があります。
- データセットを受け取ることで、あらかじめデータを選別・抽出でき、分かりやすい項目で配置できる
- データセットの中から、いろいろなデータ抽出条件を選択できる
レンダリング関数のなかで、軸の追加、カーソルをあてた際の表示メッセージ、描画、更新を実装します。一般的には3つのステップがありますが、D3のアプリケーションでは以下4つのステップがあります。
render: function(d, m) {
this._init(d, m);
this._enter(d);
this._update(d);
this._exit();
}- init:尺度、軸、データセットを初期化
- enter:初期表示を生成
- refresh:データが変更された際の表示の更新
- exit:終了
ほかのAPI、たとえばChart.jsではゼロから組み立てずに設定のみでチャート作成ができます。APIをコールして必要な設定を渡せば完成です。
var chartInstance = new Chart(ctx, {
type: "bar",
data: data,
options: {
legend: {
display: true,
labels: {
fontColor: "rgb(255, 99, 132)"
}
}
}
});形式や機能がAPIで定義済みのものに限られていて、独自性のあるカスタム表示を作る柔軟性は持ち合わせていない点が異なります。
これまで私が扱ってきたライブラリーはD3とChart.jsの2つですが、ユーザーに対しデータを見せるためのライブラリーは有料・無料ともに多くあります。選択の際に考えたい基準は以下の3点です。
- Canvas/SVGベースであること。いまだにFlashベース(あるいはSilverlightまで)のものが出回っているが、HTML標準に則していないため、アプリを統合するときに後悔する
- チームのスキルを考慮する。D3のようなライブラリーは熟練したJavaScriptの開発者には良いが、スキルによってはChartJSのようなカスタマイズ性の低いものが見合っているかもしれない
- ユーザーインターフェイス部分をプログラミングする。データを緊密にアプリに結びつけると、ツールの変更に多くの作業が発生する
複数のデータセットを同時に扱うなら、フロントエンドから非同期通信でデータを読み出して、完全にロードされるまで待ってから結合することが重要です。D3には複数データセットを扱うためのメソッドが用意されています。
d3.queue()
.defer(d3.json, "data/age.json")
.defer(d3.json, "data/generation.json")
.await(function(error, d, g) {データをロールアップ(表示前に要約処理済み)で表示するなら、D3は関数nestやrollupを提供しています。データ項目や区分を簡単に選択して要約処理ができます。
var grp = d3.nest()
.key(function(d) {
return d.generation;
})
.rollup(function(v) {
return d3.sum(v, function(d) {
return d.total;
})
})
.entries(dg);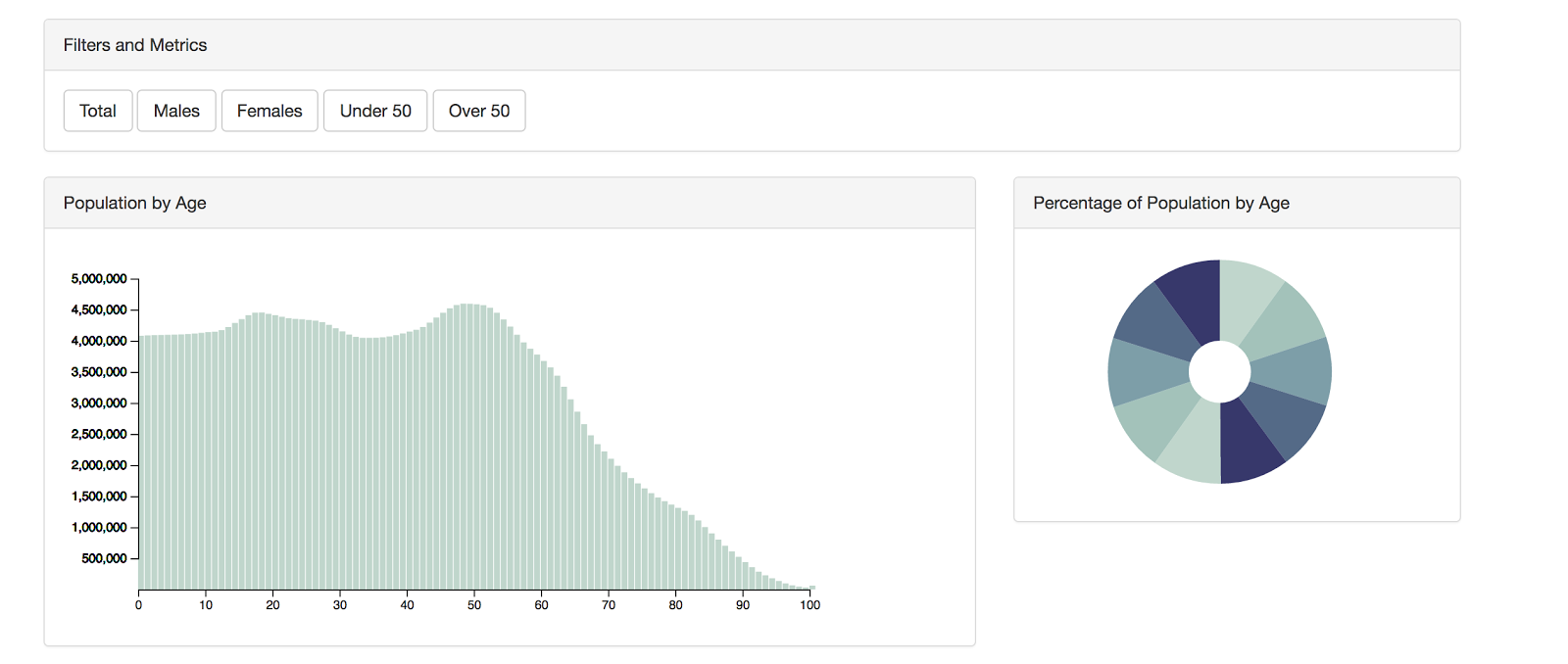
性能と機能の両立
ユーザーにデータを渡す際にもっとも重要な検討事項とはなんでしょう? ユーザーをドツボにはまらせることなく、データ分析ができるようにすることです。ユーザーが操作できる項目や指標をコントロールするのです。回線経由で巨大なデータセットをそのまま渡さずに、クライアント側のデータ処理も減らすように提供することは、パフォーマンスの観点からも有用です。
これは完全に集約して絞り込まれたデータではありません。柔軟性を持たせて、4つか5つのキーを選べるようにしてください。ユーザーがデータセットから異なるデータ区分をいくつか選べるようにして、データのグルーピングや集約もできるように、JavaScriptの配列の関数(filter、reduce、map)やD3のようなライブラリーで実装します。データでどんな分析がされるのか、ユーザーが希望する性能と機能を考慮します。
データセットを扱うなら、表示させるのか仕組みを知ることも大切です。以下は要約したJSONデータセットの例です。
[{
"females": 1994141,
"country": "United States",
"age": 0,
"males": 2085528,
"year": 2010,
"total": 4079669
}, {
"females": 1997991,
"country": "United States",
"age": 1,
"males": 2087350,
"year": 2010,
"total": 4085341
}, {
"females": 2000746,
"country": "United States",
"age": 2,
"males": 2088549,
"year": 2010,
"total": 4089295
}, {
// ...データセットは、項目「年齢、年、国名」を持ち、区分「女性、男性、合計」を持っています。十分な情報量をグラフィカルに表示しつつ、異なった切り口でデータを分析する余地を与えています。
たとえば、それぞれの年齢別にデータをグループ化したいとします。JavaScriptの配列関数を使えば、ジェネレーションX、ベビーブーマーなどの年齢層別にグループ化できます。サーバーに対して追加の関数コールをせずに、クライアント側で直接SVGを再描画できます。
このデモからも分かるように、いくつかの表示オプションと、データを抽出したりデータ区分を選んだりするためのボタンを用意しています。これはユーザーに対しデータを分析するための機能を提供するために大切なことです。
データを描画し、要求されたデータ区分を設定する関数を完成させます。
document.getElementById("total").addEventListener('click', function() {
barGraph.render(d, "total")
});意図した基準でデータをふるいにかけるため、filter()関数を使います。
document.getElementById("over50").addEventListener('click', function() {
const td = d.filter(function(a) {
return a.age >= 50
});
barGraph.render(td, "total");
});このように関数を肉付けしてデータを抽出できれば、データにフィルターをかけたり、区分を変更したり、思いどおりの切り口でデータを分析できます。
最後に
結局、データアクセスの手法はチームのスキルを反映して選ばなければなりません。完璧に設計されたデータストレージレイヤー、適切なデータアクセスレイヤー、そしてデータ表示のためのフロントエンドツールで、ユーザーにとって優れたレポート機能が実現できます。
(原文:Introduction to Data Management & Visualization in JavaScript)
[翻訳:西尾 健史/編集:Livit]
本記事はアフィリエイトプログラムによる収益を得ている場合があります