Node.jsアプリのバックエンドに適しているからか、非SQLのデータベースが話題ですが、流行っていて格好良いという理由だけで次のプロジェクトに採用するわけにはいきません。プロジェクトで要求されることに基づいてデータベース型を選ぶべきです。プロジェクトに動的なテーブル生成やリアルタイムのデータ挿入があるなら非SQLを、複雑なクエリとトランザクションを扱うならSQLデータベースが適しています。
このチュートリアルではまず、JavaScriptで書かれたNode.js用MySQLドライバー「mysql module」の導入方法を解説します。次に、このモジュールを使ってMySQLデータベースに接続する方法、一般的なCRUD操作(レコードの新規作成、読み出し、更新、削除といった基本操作)、ストアード・プロシージャを扱う方法およびユーザー入力のエスケープ方法を解説します。
NodeでMySQLを使う方法
短時間でNodeからMySQLを使える方法を求めている人にうってつけの方法を紹介します。
NodeでMySQLを使うための5つの手順です。
- 新規プロジェクトを作成:mkdir mysql-test && cd mysql-test
- package.jsonファイルの作成:npm init –y
- mysqlモジュールのインストール:npm install mysql –save
- app.jsファイルを作成して以下のコードをコピー
- コードを実行し「Connected!」というメッセージを確認:node app.js
//app.js
const mysql = require('mysql');
const connection = mysql.createConnection({
host: 'localhost',
user: 'user',
password: 'password',
database: 'database name'
});
connection.connect((err) => {
if (err) throw err;
console.log('Connected!');
});mysqlモジュールのインストール
手順を詳しく解説します。コマンドラインで新規フォルダーを作成して移動します。npm init –yコマンドでpackage.jsonファイルを作成します。-yフラグで、npmが初期値を使うように設定します。
Nodeとnpmがインストールされている前提で進めます。インストールしていない場合は、nvmで複数バージョンのNode.jsをインストールする方法を参考にインストールします。
npmでmysql moduleをインストールし、プロジェクトの依存オブジェクト、つまり本番用の依存先に設定します。プロジェクトの依存オブジェクトは開発用の依存オブジェクトとは対照的で、本番でアプリの実行時に必要になる依存先を指します。2つの違いの詳細はこちらが参考になります。
mkdir mysql-test
cd mysql-test
npm install mysql -ynpmの使い方は、こちらのガイドを参照してください。
準備とデータベースの作成
データベースへ接続する前に、MySQLをインストールし環境に応じて設定します。公式サイトのインストール方法の説明を参考にしてください。
次にデータベースの作成と、データベースのテーブルを作成します。phpMyAdminは視覚的でも、コマンドラインでも作成できます。本記事ではデータベース「sitepoint」とテーブル「employees」を作ります。データベースの中身は以下です。
CREATE TABLE employees (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(50),
location varchar(50),
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=5 ;
INSERT INTO employees (id, name, location) VALUES
(1, 'Jasmine', 'Australia'),
(2, 'Jay', 'India'),
(3, 'Jim', 'Germany'),
(4, 'Lesley', 'Scotland');
データベースへの接続
mysql-testフォルダーにapp.jsファイルを作成し、Node.jsからMySQLへ接続する方法を解説します。
// app.js
const mysql = require('mysql');
// First you need to create a connection to the db
const con = mysql.createConnection({
host: 'localhost',
user: 'user',
password: 'password',
});
con.connect((err) => {
if(err){
console.log('Error connecting to Db');
return;
}
console.log('Connection established');
});
con.end((err) => {
// The connection is terminated gracefully
// Ensures all previously enqueued queries are still
// before sending a COM_QUIT packet to the MySQL server.
});ターミナルを開き、node app.jsと入力します。接続に成功したらコンソールにメッセージ「Connection established」が表示されます。パスワードが違うなどの間違いがあればJavaScriptエラーオブジェクト(err)のインスタンスを受け取るコールバックを実行します。コンソールのログでエラー情報を確認できます。
ファイルの変更を監視するGrunt
変更のたびに手動でnode app.jsを実行するのは面倒なので自動化します。この手順は必須ではないものの、確実に手間が省けます。
いくつかのパッケージをインストールします。
npm install --save-dev grunt grunt-contrib-watch grunt-executeGruntはJavaScriptタスクランナーとして知られています。grunt-contrib-watchは監視対象のファイルが変更されたらあらかじめ定義したタスクを実行します。grunt-executeはnode app.jsコマンドの実行に使います。
インストールしたら、プロジェクトのルートフォルダーにファイル「Gruntfile.js」を作成し、以下のコードを加えます。
// Gruntfile.js
module.exports = (grunt) => {
grunt.initConfig({
execute: {
target: {
src: ['app.js']
}
},
watch: {
scripts: {
files: ['app.js'],
tasks: ['execute'],
},
}
});
grunt.loadNpmTasks('grunt-contrib-watch');
grunt.loadNpmTasks('grunt-execute');
};grunt watchを実行し、app.jsを変更します。Gruntが変更を検出し、自動でnode app.jsコマンドを再実行します。
クエリの実行
Node.jsからMySQLへの接続方法を理解したので、SQLクエリの実行方法を解説します。
読み出し
createConnectionコマンドでデータベース名「sitepoint」を指定します。
const con = mysql.createConnection({
host: 'localhost',
user: 'user',
password: 'password',
database: 'sitepoint'
});接続したら、データベーステーブルemployeesに対するクエリの実行には変数conを使います。
con.query('SELECT * FROM employees', (err,rows) => {
if(err) throw err;
console.log('Data received from Db:\n');
console.log(rows);
});grunt-watchによる実行か、ターミナルにnode app.jsと入力して実行するかを問わずapp.jsを実行するとデータベースから取得したデータがターミナルのログに表示されます。
[ { id: 1, name: 'Jasmine', location: 'Australia' },
{ id: 2, name: 'Jay', location: 'India' },
{ id: 3, name: 'Jim', location: 'Germany' },
{ id: 4, name: 'Lesley', location: 'Scotland' } ]MySQLデータベースから取得したデータは単純にrowsオブジェクトにパースできます。
rows.forEach( (row) => {
console.log(`${row.name} is in ${row.location}`);
});新規作成
データベースに対する新規レコードの挿入クエリを実行します。
const employee = { name: 'Winnie', location: 'Australia' };
con.query('
INSERT INTO employees SET ?', employee, (err, res) => {
if(err) throw err;
console.log('Last insert ID:', res.insertId);
});コールバック引数で新しく挿入したレコードのIDを取得します。
更新
同じように、レコードの更新のクエリを実行して変更される列の数をresult.affectedRowsで取得できます。
con.query(
'UPDATE employees SET location = ? Where ID = ?',
['South Africa', 5],
(err, result) => {
if (err) throw err;
console.log(`Changed ${result.changedRows} row(s)`);
}
);削除
削除のクエリも同じです。
con.query(
'DELETE FROM employees WHERE id = ?', [5], (err, result) => {
if (err) throw err;
console.log(`Deleted ${result.affectedRows} row(s)`);
}
);応用編
最後に、mysqlモジュールでストアード・プロシージャを扱う方法と、ユーザー入力のエスケープ方法を紹介します。
ストアード・プロシージャ
ストアード・プロシージャとは、たとえばSQLで書かれた一連の手続きをデータベース側に保存して、データベースエンジンやデータベースに接続するプログラム言語から呼び出し、実行することです。こちらの記事が参考になります。
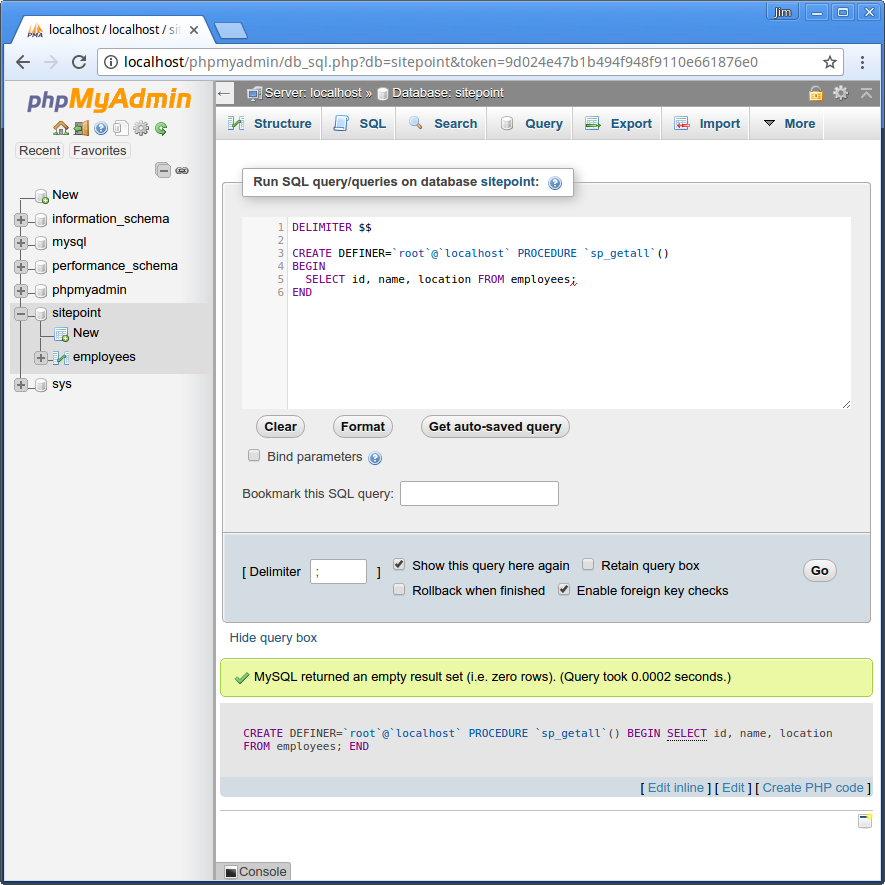
今回のデータベース「sitepoint」に、従業員全員の詳細を取得するストアード・プロシージャを作成し、sp_getallと名前を付けます。作成には、データベースのインターフェイスが必要です。ここではphpMyAdminを使いました。データベースsitepointに対して以下のクエリを実行します。
DELIMITER $$
CREATE DEFINER=`root`@`localhost` PROCEDURE `sp_getall`()
BEGIN
SELECT id, name, location FROM employees;
ENDROUTINESテーブルのデータベースinformation_schemaに、ストアード・プロシージャが作成、保存されます。
次に接続を確立し、conオブジェクトでストアード・プロシージャを呼び出します。
con.query('CALL sp_getall()',function(err, rows){
if (err) throw err;
console.log('Data received from Db:\n');
console.log(rows);
});変更を保存したらファイルを実行します。データベースから返されたデータが表示されます。
[ [ { id: 1, name: 'Jasmine', location: 'Australia' },
{ id: 2, name: 'Jay', location: 'India' },
{ id: 3, name: 'Jim', location: 'Germany' },
{ id: 4, name: 'Lesley', location: 'Scotland' } ],
{ fieldCount: 0,
affectedRows: 0,
insertId: 0,
serverStatus: 34,
warningCount: 0,
message: '',
protocol41: true,
changedRows: 0 } ]目的のデータと一緒に、変更された列の数やinsertIdなどの情報が返ってきます。そのほかの情報から切り離して従業員の詳細情報だけを得るにはインデックス番号0から順に取り出すコードを書きます。
rows[0].forEach( (row) => {
console.log(`${row.name} is in ${row.location}`);
});次に入力パラメーターを必要とするストアード・プロシージャを考えましょう。
DELIMITER $$
CREATE DEFINER=`root`@`localhost` PROCEDURE `sp_get_employee_detail`(
in employee_id int
)
BEGIN
SELECT name, location FROM employees where id = employee_id;
ENDこれで、ストアード・プロシージャを呼び出す際に入力パラメーターが渡ります。
con.query('CALL sp_get_employee_detail(1)', (err, rows) => {
if(err) throw err;
console.log('Data received from Db:\n');
console.log(rows[0]);
});データベースにレコードを挿入するには、最後に挿入したレコードのID番号を出力パラメーターとして返しす必要があります。以下のような、出力パラメーター付きの挿入処理のストアード・プロシージャを作成しました。
DELIMITER $$
CREATE DEFINER=`root`@`localhost` PROCEDURE `sp_insert_employee`(
out employee_id int,
in employee_name varchar(25),
in employee_location varchar(25)
)
BEGIN
INSERT INTO employees(name, location)
values(employee_name, employee_location);
set employee_id = LAST_INSERT_ID();
END出力パラメーター付きのストアード・プロシージャを呼び出すためには、接続を確立する際に複数のコールを有効化します。接続用のコードの記述を変更し、multipleStatements(複数の文)の実行をtrueにします。
const con = mysql.createConnection({
host: 'localhost',
user: 'user',
password: 'password',
database: 'sitepoint',
multipleStatements: true
});プロシージャの呼び出し時に、出力パラメーターを設定して渡します。
con.query(
"SET @employee_id = 0; CALL sp_insert_employee(@employee_id, 'Ron', 'USA'); SELECT @employee_id",
(err, rows) => {
if (err) throw err;
console.log('Data received from Db:\n');
console.log(rows);
}
);出力パラメーター@employee_idをセットし、ストアード・プロシージャを呼び出す際に渡します。実行後、返されたIDにアクセスする際、出力パラメーターを使います。
app.jsを実行します。選択した出力パラメーターが、そのほかの情報と共に表示されれば成功です。rows[2]で選択した出力パラメーターにアクセスできます。
[ { '@employee_id': 6 } ]ユーザー入力のエスケープ
SQLインジェクション(ユーザー入力欄に値ではなくSQLコマンドを入れて不正捜査すること)による攻撃を防ぐため、ユーザー側の入力はSQLクエリに使う前にエスケープ処理を施します。
const userLandVariable = '4 ';
con.query(
`SELECT * FROM employees WHERE id = ${userLandVariable}`,
(err, rows) => {
if(err) throw err;
console.log(rows);
}
);これは無害で、正しい結果が返ります。
{ id: 4, name: 'Lesley', location: 'Scotland' }ところが、userLandVariableを変えたらどうでしょう。
const userLandVariable = '4 OR 1=1';すべてのデータにアクセスできてしまいます。さらにこう変えたらどうでしょう。
const userLandVariable = '4; DROP TABLE employees';本格的にまずいことになります。
解決策はmysql.escapeメソッドを使うだけです。簡単ですね。
con.query(
`SELECT * FROM employees WHERE id = ${mysql.escape(userLandVariable)}`,
function(err, rows){ ... }
);もしくは、本記事の最初の例で使った、クエスチョンマークのプレイスホルダーを使います。
con.query(
'SELECT * FROM employees WHERE id = ?',
[userLandVariable],
(err, rows) => { ... }
);オブジェクト関係マッピングを使わない理由
「ORM」を使うほうがよいという指摘がありますが、良い点・悪い点を述べる前に、ORMとはなにかを手短に説明します。以下はStack Overflowの回答の引用です。
オブジェクト関係マッピング(Object-Relational Mapping、ORM)とは、オブジェクト指向の概念を使って、データベースのクエリ発行とデータ操作を可能にする手法のことです。「ORM」はオブジェクト関係マッピングを実装するためのライブラリーを指していることが多いため、「あのORMは…」と言います。
基本的に、この手法はデータベースのロジックをORMのドメイン固有言語(特定タスク専用の言語)で書くため、紹介してきた基本的な手法とは対極です。少しわざとらしいですがSequelizeを使用したサンプルです。
Employee.findAll().then(employees => {
console.log(employees);
});本来のやり方と比較すると、
con.query('SELECT * FROM employees', (err,rows) => {
if(err) throw err;
console.log('Data received from Db:\n');
console.log(rows);
});ORMを使うことに利点を見出せるかどうかは、どんな対象物に、誰と取り組んでいるのかに左右されます。ORMは、SQLの大半を抽象化することもありチーム全員がデータベース固有の超効率的クエリに精通しなくて済むので、開発者はより生産的になります。また抽象化されているがゆえに、別のデータベースソフトに移行するのも簡単です。
反面、ORMを理解しないと、汚くて非効率的なSQLになる恐れもあります。ORM抜きの素のクエリのほうが最適化しやすいため、性能の差も問題になります。
もし、決断に悩んでいるなら、Stack OverflowのスレッドWhy should you use an ORM?や、SitePointの記事あなたの知らないJavaScript ORM 3選を参考にしてください。
最後に
チュートリアルで紹介したのは、mysqlクライアントが持つ機能のほんの一部です。もっと知るには公式ドキュメントを読むことをおすすめします。またnode-mysql2やnode-mysql-libmysqlclientなどの選択肢もあります。
2017年7月11日更新。ES6構文の追加、node-mysqlモジュールの名称変更の反映、初心者向け説明の追加、ORM(オブジェクト関係マッピング)について追記しました。
(原文:Using MySQL with Node.js & the mysql JavaScript Client)
[翻訳:西尾 健史/編集:Livit]
本記事はアフィリエイトプログラムによる収益を得ている場合があります